Clear Sky Science · de
Photonischer Single-Shot-Matrix-Matrix-Prozessor basierend auf räumlich-spektral hypermultiplexierter paralleler Beugung
Warum schnelleres, grüneres Rechnen wichtig ist
Jedes Mal, wenn wir einem digitalen Assistenten eine Frage stellen oder durch soziale Medien scrollen, arbeiten leistungsstarke KI-Modelle im Hintergrund. Diese Modelle werden so groß, dass konventionelle Computerchips Schwierigkeiten haben, Schritt zu halten, ohne enorme Mengen Energie zu verbrauchen. Dieser Artikel beschreibt eine neue Art von Rechenhardware, die statt Elektrizität Licht verwendet, um zentrale KI-Berechnungen durchzuführen, mit dem Ziel, künftige Maschinen sowohl schneller als auch deutlich energieeffizienter zu machen.
Wie man Licht in einen Rechner verwandelt
Moderne KI beruht auf Operationen, die Matrixmultiplikationen genannt werden und die Milliarden- bis Billionenfach ausgeführt werden, wenn ein neuronales Netz Bilder oder Texte analysiert. Elektronische Chips erledigen diese Arbeit zuverlässig, verschwenden dabei aber viel Energie allein durch das Bewegen von Daten innerhalb des Chips. Die hier vorgestellten Forschenden bauen auf einer anderen Idee auf: Das Licht selbst die Rechnung ausführen zu lassen. In einem optischen neuronalen Netz werden Informationen in Laserstrahlen codiert, beim Durchgang durch Linsen und Modulatoren manipuliert und anschließend von Lichtdetektoren ausgelesen. Da Photonen nicht die gleichen Wärmeverluste in Leitungen verursachen wie Elektronen, können solche Systeme prinzipiell deutlich höhere Geschwindigkeiten und Effizienzen erreichen.
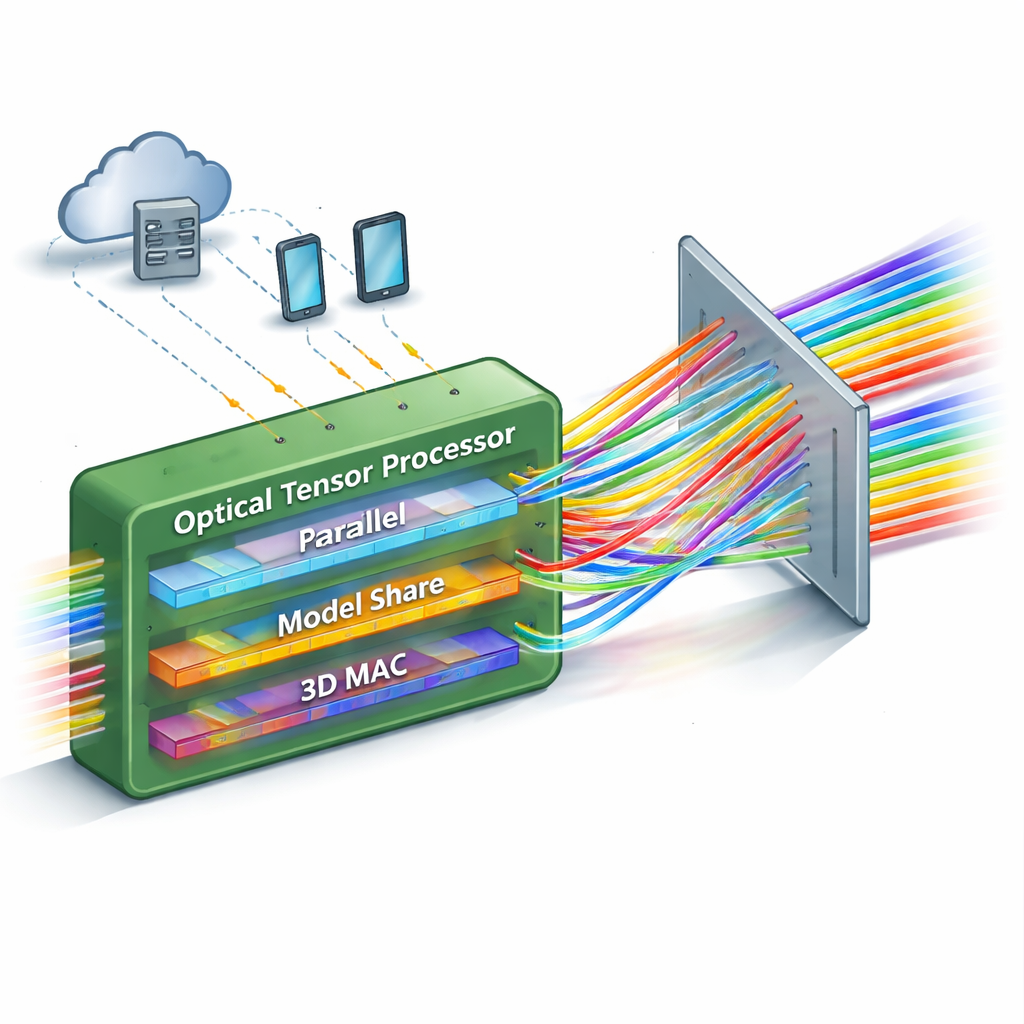
Viele Berechnungen auf einen Schlag
Die meisten bestehenden optischen neuronalen Netze haben eine Einschränkung: Sie können nur eine begrenzte Anzahl von Berechnungen parallel verarbeiten, bevor sie zu komplex werden, um skaliert zu werden. Diese Arbeit stellt einen „Single-Shot“-Matrix–Matrix-photonischen Prozessor vor, der die Anzahl gleichzeitig ausführbarer Operationen drastisch erhöht. Die Kernidee ist, Informationen gleichzeitig in drei verschiedenen Eigenschaften des Lichts zu bündeln — seiner räumlichen Position, seiner Farbe (Wellenlänge) und seiner Zeitlichkeit. Durch sorgfältige Anordnung dieser Dimensionen kann das Gerät eine vollständige Matrix–Matrix-Multiplikation durchführen, die Tausende von Multiplizier- und Akkumulationsschritten umfasst, in einem einzigen Durchgang des Lichts durch das System.
Ein Beugungsgitter als Verkehrslenker für Licht
Im Zentrum des Designs steht ein einfaches, aber kraftvolles optisches Element: ein Beugungsgitter, das Licht je nach Farbe in unterschiedliche Winkel aufspaltet. Das Team verwendet ein speziell angeordnetes, dreidimensionales Gittersystem wie einen Verkehrslenker, der viele farbige Strahlen aus zahlreichen Eingangskanälen in neu geordnete Ausgangskanäle leitet. Zu verarbeitende Daten werden als Lichtintensitäten auf einer Reihe von Modulatoren kodiert, während die „Gewichte“ des neuronalen Netzes auf einer anderen Reihe gespeichert sind. Treffen die Strahlen auf das Gitter und passieren es, werden ihre Bahnen so umsortiert, dass jeder Ausgangskanal die richtigen Kombinationen aus Daten und Gewichten natürlich aufsummiert. Zeitintegrierende Detektoren akkumulieren dann Beiträge über mehrere kurze Zeitschritte und erweitern damit effektiv die Größe der Berechnung, ohne zusätzliche Komplexität in der Optik zu erzeugen.
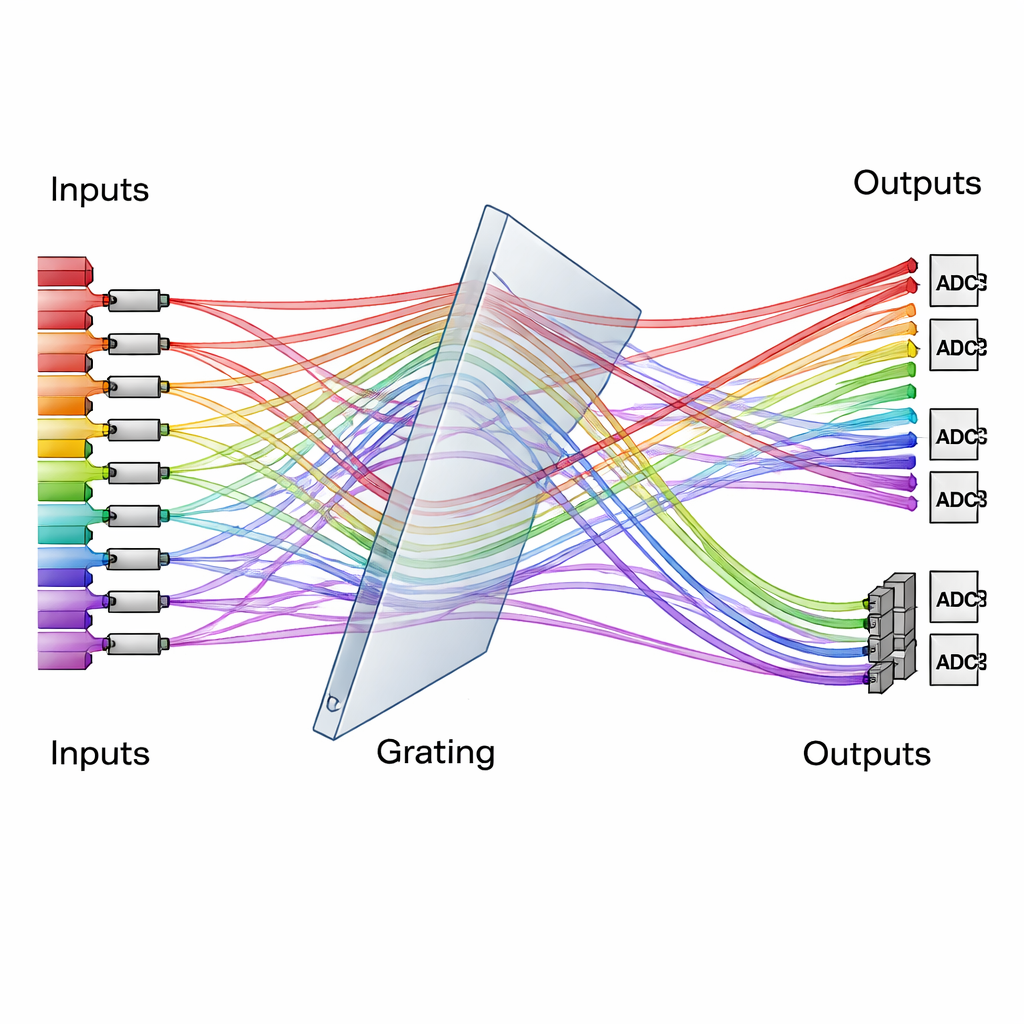
Vom Laboraufbau zu echten KI-Aufgaben
Die Autoren demonstrieren einen optischen Tensorprozessor mit der Struktur 16×16×16×16, das heißt, er kann eine 16×16-Matrix in einer einzigen optischen „Shot“ mit einer anderen 16×16-Matrix multiplizieren und erreicht damit 4096 Grundoperationen gleichzeitig. Das System arbeitet mit Multi-Gigahertz-Taktraten und erzielt eine effektive Rechenpräzision von mehr als acht Bits, vergleichbar mit vielen praktischen KI-Beschleunigern. Um zu zeigen, dass dies mehr als ein physikalischer Demonstrator ist, setzen sie den Prozessor in Teilen einer kleinen Bilderkennungs-Pipeline ein: ein Faltungsneuronales Netz, das Merkmale aus Ziffernbildern extrahiert, gefolgt von einem vollständig verbundenen Netz zur Klassifikation. Selbst mit optischem Rauschen und Hardware-Unvollkommenheiten erkennt der Aufbau handschriftliche Ziffern mit etwa 96 % Genauigkeit, nahe an einer rein digitalen Umsetzung desselben Modells.
Energieverbrauch, Empfindlichkeit und Skalierbarkeit
Da die Architektur dieselben optischen Komponenten über viele parallele Kanäle wiederverwendet und Signale effizient akkumuliert, kann jede Grundoperation mit extrem geringem Energieaufwand ausgeführt werden — bis hinab zu einigen zehn Attojoule optischer Energie pro Multiplikation. Die Autoren schätzen, dass die Gesamtenergieeffizienz bereits einige moderne elektronische KI-Beschleuniger übertrifft, und argumentieren, dass moderate Verbesserungen bei Modulatoren und Digital-Analog-Wandlern dies in den Bereich von Hunderten Billionen Operationen pro Sekunde und Watt bringen könnten. Wichtig ist, dass das Design einige der Skalierungsprobleme vermeidet, die andere optische Konzepte heimsuchen, sodass größere Versionen mit deutlich mehr Kanälen (zum Beispiel 30×30 oder sogar 60×60 Arrays) mit ähnlichen Komponenten realisierbar erscheinen.
Was das für die Alltagstechnik bedeutet
Einfach ausgedrückt zeigt diese Forschung, dass eine relativ einfache optische Anordnung — eine intelligente Art, gefärbte Lichtstrahlen durch ein Beugungsgitter zu lenken — als leistungsfähige, energiearme Recheneinheit für KI-ähnliche Berechnungen dienen kann. Zwar handelt es sich noch um einen Laborprototyp, doch der Ansatz deutet auf künftige Rechenzentren und Edge-Geräte hin, in denen lichtbasierte Prozessoren die schwersten Lasten neuronaler Netzwerke übernehmen, Energiekosten senken und größere, schnellere Modelle ermöglichen. Können solche photonischen Tensorprozessoren integriert und in großem Maßstab gefertigt werden, könnten sie zu einem Schlüsselbaustein der nächsten Generation leistungsstarker, energieeffizienter KI-Hardware werden.
Zitation: Luan, C., Davis III, R., Chen, Z. et al. Single-shot matrix-matrix photonic processor based on spatial-spectral hypermultiplexed parallel diffraction. Nat Commun 17, 484 (2026). https://doi.org/10.1038/s41467-026-68452-x
Schlüsselwörter: optische neuronale Netze, photonisches Rechnen, Matrixmultiplikation, energieeffiziente KI-Hardware, Beugungsgitter