Clear Sky Science · de
Unvoreingenommene Clusterbildung von Patienten mit akut-auf-chronischem Leberversagen mittels Machine Learning in einer realen Intensivkohorte
Warum das für Menschen mit Lebererkrankung wichtig ist
Wenn Menschen mit einer langjährigen Lebererkrankung plötzlich sehr schwer erkranken, müssen Ärztinnen und Ärzte rasch einschätzen, wer das höchste Sterberisiko hat und wer sich erholen könnte. Heute basieren diese Entscheidungen auf Bewertungssystemen, die aus Expertenmeinung und kleinen Studien entstanden sind. Diese Arbeit zeigt, wie ein datengesteuerter Machine-Learning-Ansatz verborgene Muster bei realen Intensivpatienten mit akut-auf-chronischem Leberversagen aufdecken kann und damit auf einfachere, genauere Wege hinweisen könnte, diejenigen zu identifizieren, die die intensivste Behandlung benötigen.
Sehr kranke Patienten ohne Vorannahmen sortieren
Die Forschenden untersuchten 1.256 Intensivpatienten mit akut-auf-chronischem Leberversagen, definiert nach nordamerikanischen Kriterien, die das Versagen von Gehirn, Lunge, Herz-Kreislauf und Nieren in den Mittelpunkt stellen. Statt von etablierten Leber-Scores auszugehen, fütterten sie 50 routinemäßig gemessene klinische und laborchemische Werte in eine unüberwachte Machine-Learning-Methode namens nichtnegative Matrixfaktorisierung. Diese Technik sucht nach natürlichen Gruppierungen in den Daten, ohne vorher zu wissen, welche Merkmale wichtig sind oder wie viele Patiententypen zu erwarten sind. Ein separates Algorithmusverfahren wurde verwendet, um verschiedene Lösungen zu testen und zu entscheiden, wie viele Cluster die Daten am besten beschreiben.
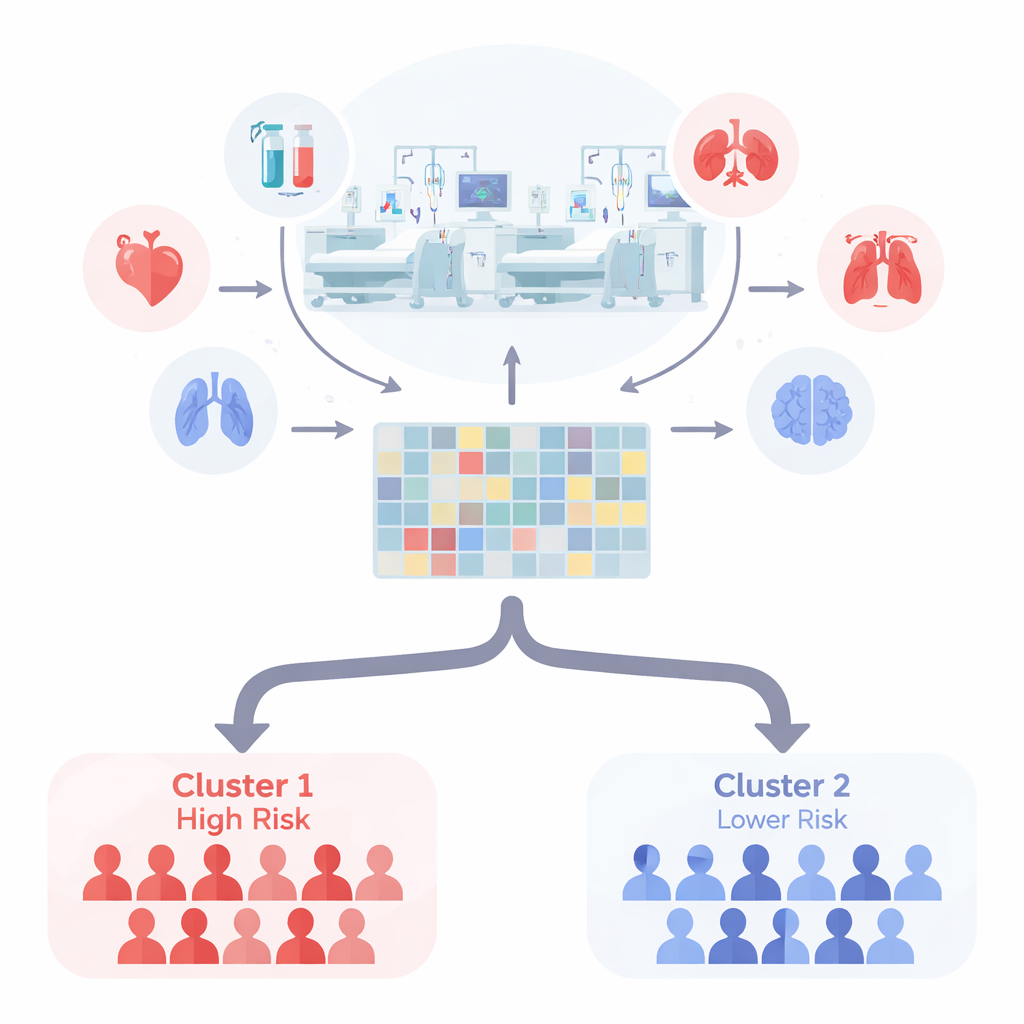
Zwei klare Gruppen mit sehr unterschiedlichen Ergebnissen
Über mehrere Varianten der Cluster-Methode hinweg teilten sich die Daten konsistent am besten in nur zwei Patientengruppen. Das siegreiche Modell, bekannt als Lee-Algorithmus, erzeugte hochstabile Cluster: dieselben Patienten wurden tendenziell wieder zusammengefasst, selbst wenn das Modell viele Male neu gestartet wurde. Beim Vergleich der Überlebensraten fanden die Autorinnen und Autoren auffällige Unterschiede. Ein Cluster hatte eine 30-Tage-Sterberate von etwa 70 %, während die andere Gruppe bei rund 26 % lag. Dieses einfache Zwei-Cluster-Schema sagte die Sterblichkeit besser voraus als der traditionelle Ansatz, die Zahl der versagten Organe zu zählen, obwohl beide Gruppen Patienten mit einer Mischung aus Organversagen enthielten.
Blutchemie und Stoffwechsel als entscheidende Signale
Um zu verstehen, was die Cluster voneinander unterschied, untersuchte das Team, welche Messgrößen die Gruppierung am stärksten beeinflussten. Mehrere vertraute Marker kritischer Erkrankung, wie der Bedarf an blutdruckunterstützenden Medikamenten, Laktatwerte im Blut und Kreatinin (ein Nierenfunktionsmarker), waren wichtig. Besonders bemerkenswert war jedoch, dass Messgrößen des Säure‑Basen-Haushalts im Blut — Bicarbonat, pH, Basenüberschuss, Laktat und die Anionenlücke — zu den wichtigsten Beiträgen gehörten. Der Hochrisiko-Cluster wies tendenziell schwerere Störungen des Säure‑Basen-Haushalts auf: niedrigerer pH und Bicarbonat, größere Basendefizite und höhere Anionenlücken, was mit ausgeprägtem metabolischem Stress und schlechter Gewebeoxygenierung vereinbar ist. Diese Muster deuten darauf hin, dass die Fähigkeit des Körpers, sein chemisches Gleichgewicht aufrechtzuerhalten, genauso wichtig sein könnte wie die Frage, welche Organe versagt haben.
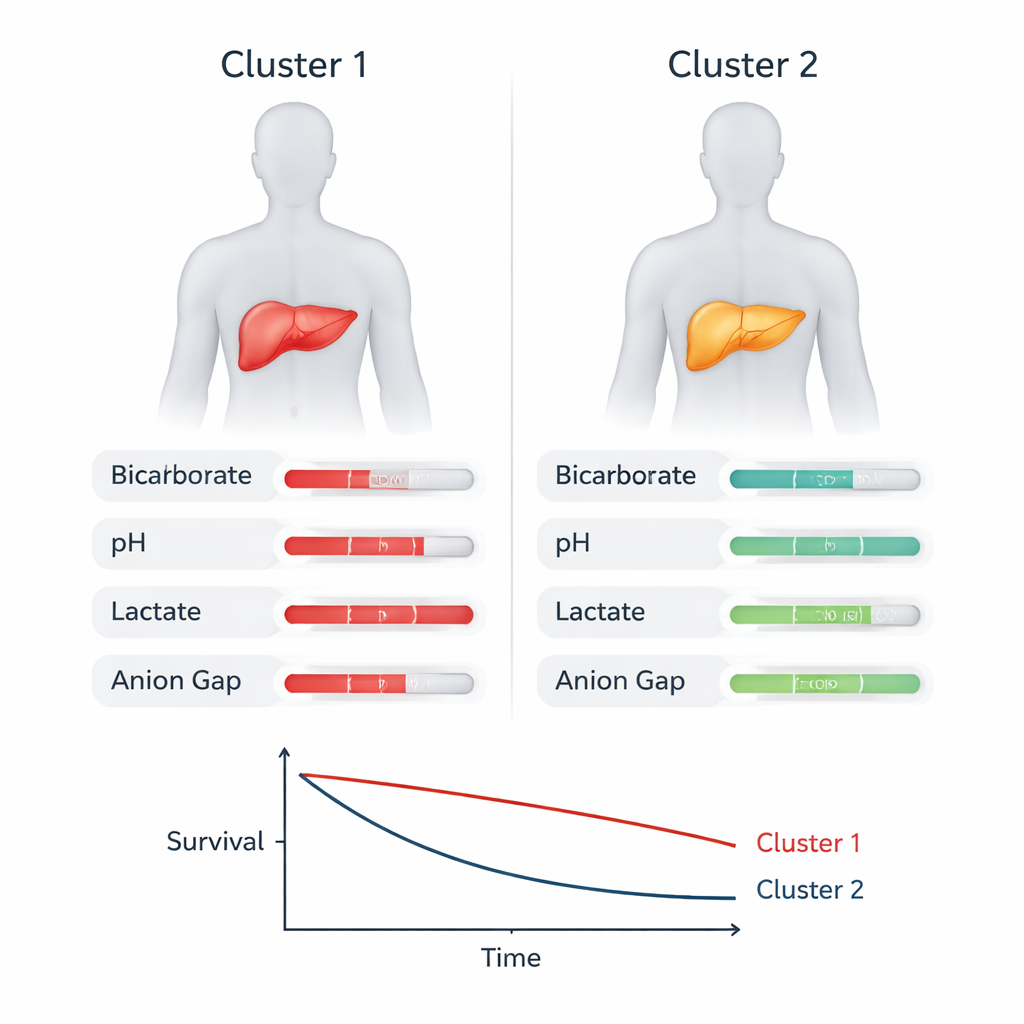
Überprüfung des Musters in anderen Patientengruppen
Da Intensivdaten aus einem einzigen Gesundheitssystem und nach einer Definition des akut-auf-chronischen Leberversagens stammten, prüften die Autorinnen und Autoren, ob ihre Ergebnisse auch anderswo Bestand haben. Sie wendeten dasselbe Modell auf Patienten an, die einer europäischen Definition des Syndroms entsprachen, und auf eine breitere Gruppe von Intensivpatienten mit dekompensierter Zirrhose, von denen viele formal nicht als akut-auf-chronisch Leberversagen klassifiziert waren. In beiden Umgebungen teilte das Clustering die Patienten erneut in zwei Gruppen mit ähnlich großen Unterschieden in der 30-Tage-Sterblichkeit, und dieselben säure‑basenbezogenen Variablen blieben zentral. Eine unabhängige Intensivdatenbank aus vielen US-Krankenhäusern, obwohl sie keine Langzeitergebnisdaten enthielt, zeigte dieselbe Zwei-Cluster-Struktur und überlappende Schlüsselvariablen, was die Robustheit des Ansatzes stützt.
Was das für die zukünftige Versorgung bedeuten könnte
Die Studie liefert noch kein bettseitiges Instrument, das das Überleben direkt verbessert, und sie hat Einschränkungen, einschließlich des Fokus auf sehr kranke Intensivpatienten und der Abhängigkeit von retrospektiven Daten. Dennoch bietet sie einen Machbarkeitsnachweis, dass eine unvoreingenommene, datengesteuerte Methode klinisch bedeutungsvolle Subtypen innerhalb einer komplexen Erkrankung aufdecken kann, die sich lange einer einfachen Einordnung widersetzt hat. Für Patientinnen und Patienten sowie Familien ist die Hauptbotschaft, dass der Säure‑Basen-Haushalt im Blut — etwas, das Ärztinnen und Ärzte bereits routinemäßig messen — starke Hinweise auf Risiko und Erholung bei schweren Leberkrisen liefern kann. Mit weiterer Forschung und prospektiver Prüfung könnten solche Clustering-Modelle Klinikern helfen, die fragilsten Patienten früher zu identifizieren und Behandlungen zu entwickeln, die die metabolischen Störungen gezielt adressieren, die ihre schlechten Outcomes antreiben.
Zitation: Zhang, M., Ji, F., Zu, J. et al. Unbiased clustering of acute-on-chronic liver failure patients using machine learning in a real-world ICU cohort. Nat Commun 17, 1670 (2026). https://doi.org/10.1038/s41467-026-68368-6
Schlüsselwörter: akut-auf-chronisches Leberversagen, Machine Learning, ICU-Ergebnisse, Säure-Basen-Haushalt, Zirrhose