Clear Sky Science · de
Die Rolle niederkomplexer Wiederholungen bei RNA–RNA-Interaktionen und ein Deep-Learning-Rahmen zur Duplexvorhersage
Haftende RNA-Sequenzen, die das Zellverhalten formen
In jeder Zelle stoßen RNA-Moleküle ständig aufeinander und bilden flüchtige Partnerschaften, die steuern, welche Gene aktiviert werden, wie Proteine hergestellt werden und wie sich Zellen entwickeln. Diese Studie zeigt, dass viele dieser RNA–RNA-Begegnungen nicht zufällig sind: Sie werden von kurzen, einfachen, stark repetitiven Sequenzen gelenkt, die wie molekulares Klett wirken. Die Forscher bauen außerdem ein Werkzeug der künstlichen Intelligenz, das vorhersagen kann, wo solche RNA-Paare wahrscheinlich entstehen, und eröffnen damit neue Wege, die Funktionsweise von Zellen in Gesundheit und Krankheit zu erkunden.
Einfache Wiederholungen mit starken Wirkungen
RNA wird häufig als Bote beschrieben, der genetische Informationen von DNA zu Proteinen trägt, doch sie dient auch als Gerüst, Regulator und Führer. Vieles davon beruht darauf, dass sich zwei RNA-Stränge miteinander verbinden. Durch die Zusammenführung von Daten mehrerer großer experimenteller Untersuchungen in menschlichen und Mäusezellen zeigen die Autoren, dass die Regionen der RNA, die tatsächlich an solchen Paarungen beteiligt sind, stark angereichert sind in dem, was sie niederkomplexe Wiederholungen nennen. Dabei handelt es sich um Abschnitte, die aus kurzen Motiven — etwa Wiederholungen von G- und C-Basen — immer wieder aufgebaut sind. Anstatt genomischer „Abfall“ zu sein, erweisen sich diese repetitiven Abschnitte als zentrale Andockstellen, an denen eine RNA an viele andere binden kann und so dichte Interaktionsknoten im Transkriptom bildet. 
RNA-Hubs für Entwicklung und Regulation
Als das Team untersuchte, welche Gene diese repeat-reichen Kontaktstellen tragen, zeichnete sich ein auffälliges Muster ab: Viele von ihnen kodieren Proteine, die Entwicklung und Zellidentität steuern, etwa Transkriptionsfaktoren. Selbst in Krebszelllinien, die sich nicht aktiv differenzieren, waren RNAs, die mit Entwicklungsprogrammen verknüpft sind, stark in wiederholungsbasierte Kontakte eingebunden. Die Autoren betrachteten auch spezifische lange nicht-kodierende RNAs (lncRNAs), also RNA-Moleküle, die nicht für Proteine kodieren, aber häufig regulierend wirken. So zeigten die Ziele der lncRNA TINCR und einer weiteren für die Motorneuronenbildung wichtigen lncRNA, Lhx1os, beide eine Überhäufung komplementärer Wiederholungen. In diesen Fällen werden einfache Wiederholungen auf der lncRNA durch komplementäre Wiederholungen in ihren Partner-RNAs ergänzt, was stabile Paarungen ermöglicht, die helfen können, die Menge oder Translation wichtiger Entwicklungs-Gene feinzujustieren.
Wo Proteine und Editierungsenzyme hinzukommen
Diese wiederholungsgetriebenen RNA-Kontakte wirken selten allein. Die Autoren überlagerten Protein-Bindungskarten mit ihren Interaktionsdaten und fanden, dass viele wiederholungsführende Kontaktstellen auch von RNA-Bindungsproteinen erkannt werden, die an der Translationskontrolle, RNA-Abbau und an der Bildung zytoplasmatischer Granula wie P-Bodies und Stressgranula beteiligt sind. Ein Protein im Besonderen, STAU1, das den Abbau seiner RNA-Ziele auslösen kann, bindet häufig Duplexe, die durch niederkomplexe Wiederholungen gebildet werden. Das Herunterregulieren von STAU1 führte zu höheren Konzentrationen von RNAs, die an diesen Duplexen beteiligt sind, insbesondere solchen mit Wiederholungen, was darauf hindeutet, dass repeat-vermittelte RNA-Paarungen Transkripte zur kontrollierten Degradation markieren können. Dieselben wiederholungsreichen Regionen ziehen auch RNA-Editierungsenzyme wie ADAR1 an, die spezifische Basen in doppelsträngiger RNA chemisch modifizieren, und deuten damit an, dass niederkomplexe Wiederholungen Editierungsstellen positionieren, die das RNA-Verhalten feinabstimmen.
Ein neuronales Netz beibringen, RNA-Kontakte zu lesen
Gängige Computerprogramme versuchen, RNA–RNA-Bindungen hauptsächlich auf der Grundlage thermodynamischer Stabilität vorherzusagen — wie viel Energie es erfordern würde, einen Duplex zu bilden oder zu lösen. Diese Modelle sind zwar nützlich, übersehen aber oft reale Interaktionen, die in Zellen beobachtet werden, insbesondere zwischen langen RNAs. Um über einfache Energie-regeln hinauszugehen, trainierten die Autoren ein Deep-Learning-Modell namens RIME, das "Language-Model"-artige Einbettungen verwendet: numerische Repräsentationen von RNA-Sequenzen, die Muster kodieren, die aus riesigen Sammlungen von Nukleinsäuredaten gelernt wurden. RIME werden Paare von RNA-Segmenten gezeigt und es lernt zu klassifizieren, ob sie interagieren, wobei viele echte Paarungen aus Psoralen-basierten Crosslinking-Experimenten als positive Beispiele und sorgfältig konstruierte Nicht-Interaktionspaare als negative Beispiele dienen. 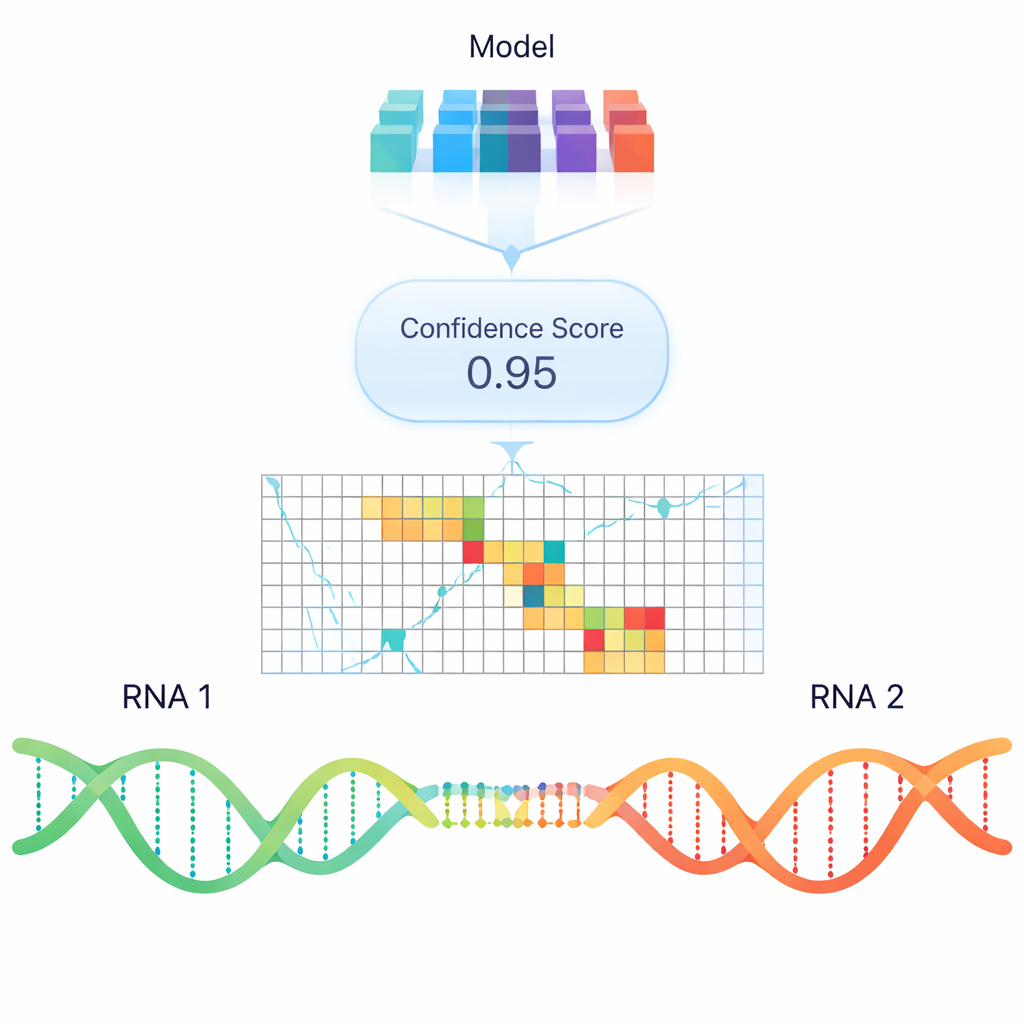
Intelligentere Vorhersagen und neue biologische Hinweise
Im Vergleich mit führenden thermodynamikbasierten Werkzeugen und einer anderen neuronalen Methode schneidet RIME beständig besser ab, wenn es darum geht, echte RNA–RNA-Kontakte von Ködern zu unterscheiden, insbesondere bei experimentellen Interaktionen mit hoher Zuverlässigkeit. Es sagt nicht nur voraus, ob sich zwei RNAs paaren, sondern neigt auch dazu, die exakt beteiligten Regionen hervorzuheben, und lernt von selbst, dass niederkomplexe Wiederholungen starke Prädiktoren für Kontakte sind. Bemerkenswerterweise funktioniert dasselbe Modell, das ausschließlich auf Interaktionen zwischen unterschiedlichen RNAs trainiert wurde, auch gut zur Vorhersage interner Basenpaarungen innerhalb einer einzelnen RNA und stimmt mit strukturellen Experimenten sowie klassischen Faltungsalgorithmen überein. Für nicht-kodierende Regulatoren wie TINCR, NORAD und SMaRT entdeckt RIME bekannte funktionelle Interaktionsstellen zuverlässig wieder und schlägt zusätzliche Kandidatenregionen vor.
Warum das wichtig ist
Für die allgemeine Leserschaft ist die Kernbotschaft, dass kurze, repetitive Abschnitte in RNA — einst leichtfertig als nutzloses Rauschen abgetan — als zentrale Verbindungspunkte im RNA-Verdrahtungsdiagramm der Zelle fungieren. Sie bringen RNAs zusammen, laden regulatorische Proteine und Editierungsenzyme ein und werden intensiv in Signalwegen genutzt, die steuern, wie sich Zellen entwickeln und auf Stress reagieren. Das neue RIME-Modell bietet Forschenden ein leistungsfähiges Werkzeug, um Genome nach diesen RNA–RNA-Partnerschaften zu durchsuchen, einschließlich solcher, die bei neurologischen und anderen an Wiederholungsexpansionen gebundenen Erkrankungen fehlgehen können. Im Kern zeigt diese Arbeit, dass das Verstehen — und Vorhersagen — wie einfache RNA-Wiederholungen aneinanderhaften, verborgene Ebenen der Genregulation offenbaren kann.
Zitation: Setti, A., Bini, G., Pellegrini, F. et al. The role of low-complexity repeats in RNA–RNA interactions and a deep learning framework for duplex prediction. Nat Commun 17, 1637 (2026). https://doi.org/10.1038/s41467-026-68356-w
Schlüsselwörter: RNA–RNA-Interaktionen, niederkomplexe Wiederholungen, lange nicht-kodierende RNA, Deep Learning, Genregulation