Clear Sky Science · de
Einzelbild‑Neuralbeleuchtungsabschätzung und -bearbeitung für dynamische Lightfield‑Displays
Warum Ihre virtuelle Welt zum Wohnzimmer passen sollte
Jeder, der eine Virtual‑ oder Mixed‑Reality‑Brille getragen hat, kennt das: Ein digitales Objekt wirkt seltsam fehl am Platz, weil Beleuchtung und Schatten nicht zum realen Raum passen. Dieses Paper nimmt genau dieses Problem in Angriff. Die Autorinnen und Autoren stellen eine Methode vor, mit der Headsets die Beleuchtung der realen Umgebung aus nur einer Kameraperspektive „verstehen“ können und diese Information nutzen, damit virtuelle Objekte so aussehen, als gehörten sie wirklich in Ihre Welt – ganz ohne spezielle Lichtsonden, aufwändige Aufnahmen oder umfangreiche Neukalibrierung.
Licht im Raum leichter handhabbar machen
In Physik und Computergrafik wird das Aussehen einer Szene durch das vollständige „Lichtfeld“ bestimmt: alle Lichtstrahlen, die den Raum in jeder Richtung durchfließen. Dieses Feld exakt zu rekonstruieren ist normalerweise sehr datenintensiv und erfordert viele Bilder und sorgfältige Messungen. Moderne 3D‑Techniken wie neuronale Radiance‑Felder speichern Szenen in Netzwerken, „backen“ dabei jedoch meist die Beleuchtung ein, die bei der Erfassung vorherrschte. Das heißt: Die virtuelle Szene wirkt nur unter diesen ursprünglichen Bedingungen korrekt und bricht auseinander, wenn sich die Beleuchtung im realen Raum ändert. Das Ziel der Autoren ist es, diese Einschränkung zu überwinden, indem sie eine kompakte Beschreibung der realen Beleuchtung aus minimalen Daten finden und diese dann nutzen, um ein neuronales 3D‑Modell flexibel neu zu beleuchten.
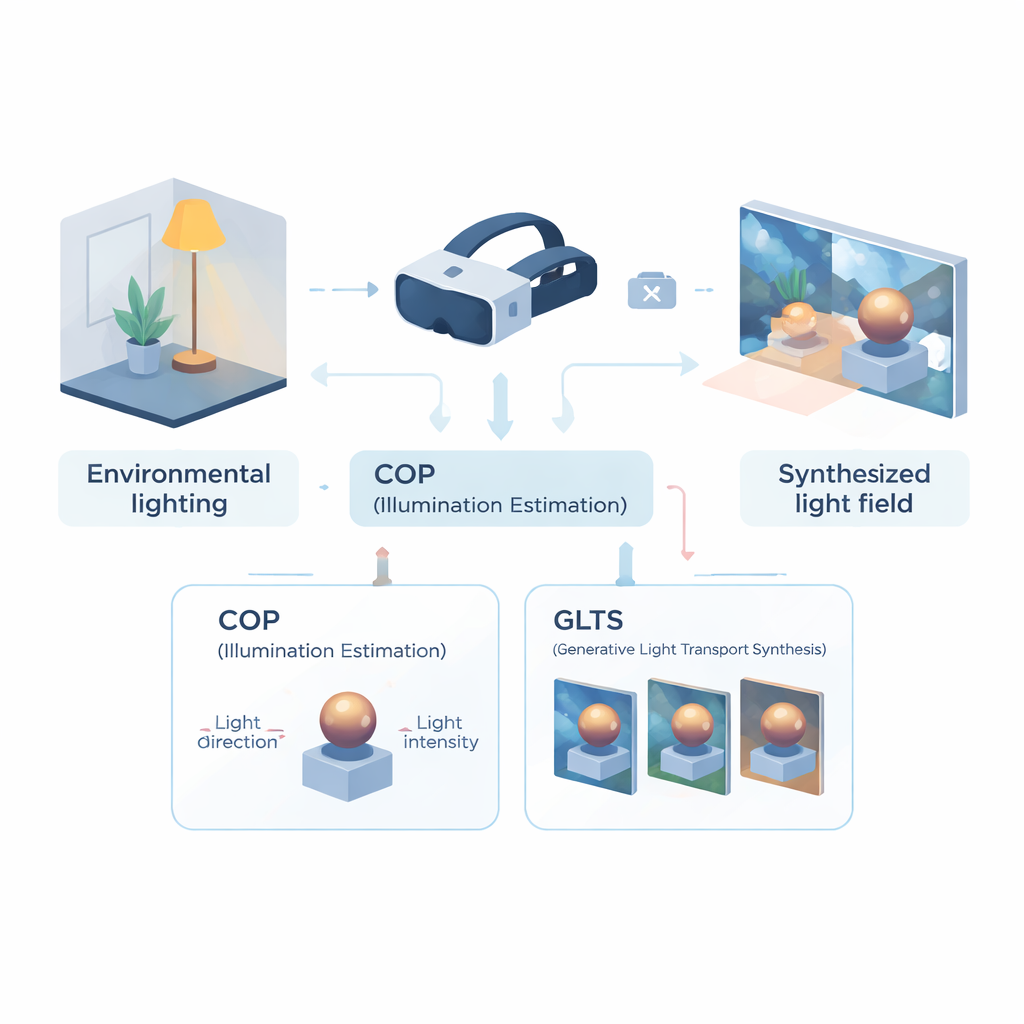
Der Brille beibringen, den Raum zu lesen
Der erste Teil des Frameworks ist ein Modul für computational optical perception (COP), das dafür ausgelegt ist, Beleuchtung aus einer einzigen Kameraperspektive zu erfassen. Statt das gesamte Lichtfeld zu rekonstruieren, konzentriert sich COP auf die dominante Lichtquelle: deren Richtung und Stärke. Ein multiskaliges neuronales Netz durchsucht das Eingangsbild nach physikalischen Hinweisen – helle Spiegelungen, Schattierungsgradienten und Schatten – während ein spezieller Interpolationsschritt für die nichtlineare Art korrigiert, wie Kameras Helligkeit komprimieren. Das liefert numerische Schätzwerte für Lichtintensität und ‑richtung, die die reale Energieverteilung in der Szene besser widerspiegeln. Eine zweite Stufe, der semantische Interpreter, verfeinert diese Werte und erzeugt eine kurze, textähnliche Beschreibung der Beleuchtung (zum Beispiel: Licht kommt von oben und rechts). Die Kombination aus Zahlen und Worten macht die Schätzung stabiler und einfacher in den folgenden Schritten nutzbar.
Objekte mit neuem Licht ummalen
Mit dieser kompakten Beleuchtungsbeschreibung übernimmt das zweite Modul – generative light transport synthesis (GLTS) – die Weiterverarbeitung. GLTS startet von einer vorhandenen neuronalen 3D‑Darstellung eines Objekts oder einer Szene, die ursprünglich unter der alten, eingebrannten Beleuchtung gerendert wurde. Geleitet von der ermittelten Lichtrichtung, Intensität und der Textbeschreibung „übermalt“ ein generatives Netz diese Ansicht so, dass Glanzlichter und Schatten zur neuen Umgebung passen. Um das Ergebnis sowohl realistisch als auch objektspezifisch zu halten, kombiniert GLTS zwei Arten von Steuerung: globale Kontrolle durch die Beleuchtungsparameter und feine Details, die direkt aus dem beobachteten Bild entnommen werden. Durch einen spezialisierten Trainingsprozess, der sich ausschließlich darauf konzentriert, wie ein einzelnes Objekt auf verschiedene Lichtverhältnisse reagiert, lernt das Modell, Reflexionen zu verschieben und Schattenkanten physikalisch plausibel zu verfeinern, anstatt nur einen generischen Stilfilter anzuwenden.
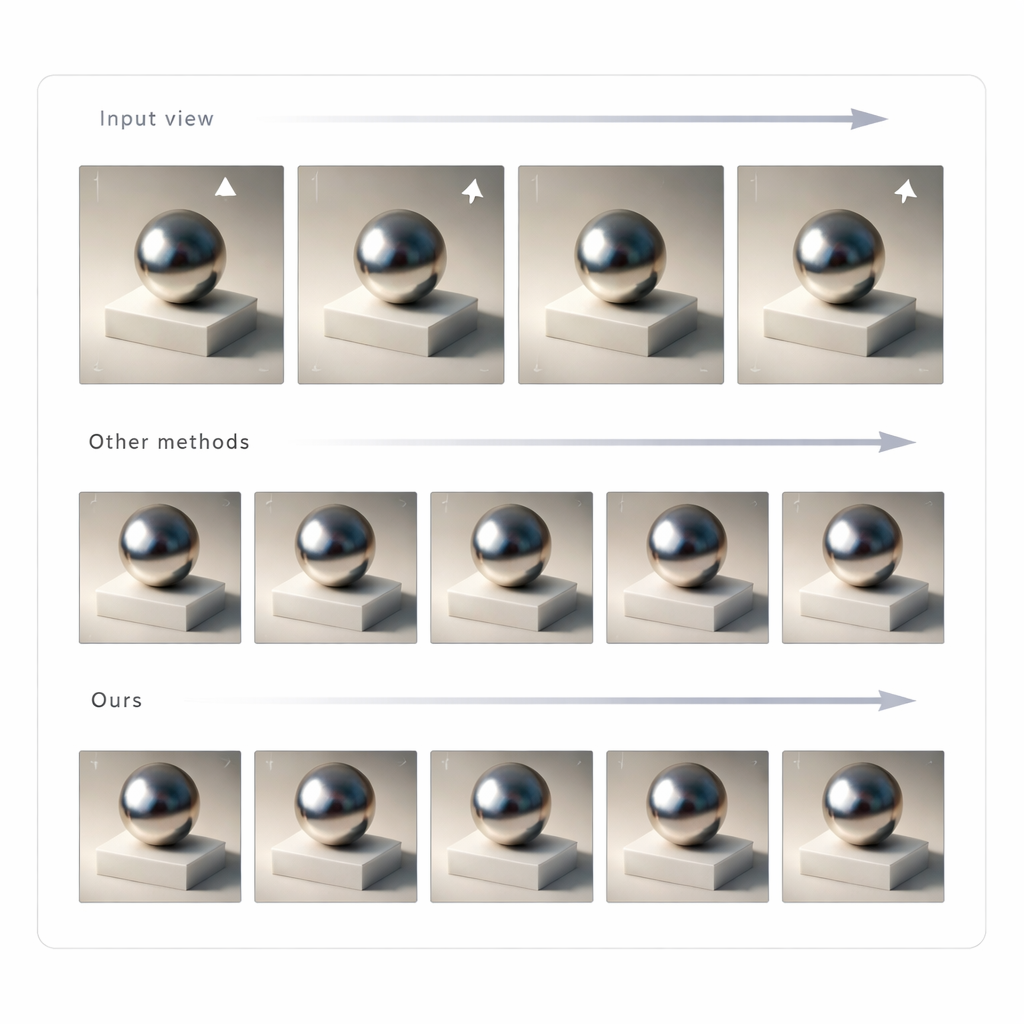
Ein konsistentes 3D‑Lichtfeld aus vielen Ansichten aufbauen
Ein einzelnes Bild zu ändern reicht für überzeugende Mixed‑Reality nicht aus; die Beleuchtung muss beim Bewegen des Kopfes konsistent bleiben. Um das zu erreichen, erzeugen die Autorinnen und Autoren mit GLTS aus vielen Blickwinkeln eine Reihe neu beleuchteter Bilder und verwenden diese als Zielbilder zum Wiederaufbau der 3D‑Szene. Ein gemeinsam optimierender Prozess passt gleichzeitig die neuronale 3D‑Darstellung und die virtuellen Kamerapositionen an, sodass das Rendering des neuen Modells alle synthetisierten Ansichten reproduziert. Dieser Schritt korrigiert subtile Verzerrungen, die das generative Netz einführt, und erzeugt ein kohärentes 3D‑Asset, dessen Erscheinungsbild aus jedem Winkel stabil und glaubwürdig bleibt. Das Team verglich seine Methode mit mehreren aktuellen Relighting‑Ansätzen und fand, dass sie eine schärfere Übereinstimmung mit Referenzbildern sowie natürlicher wirkende Schatten und Reflexionen liefert, gemessen an Pixel‑ wie auch wahrnehmungsbasierten Metriken.
Was das für zukünftige Headsets bedeutet
Für Nicht‑Spezialisten ist die wichtigste Erkenntnis: Diese Arbeit zeigt, wie künftige VR‑, AR‑ und Mixed‑Reality‑Geräte virtuelle Inhalte an die reale Beleuchtung anpassen könnten – allein durch einen kurzen Blick der Kamera. Anstelle mühsamer Aufnahmeaufbauten oder dem Neubilden spezieller Modelle für jede Szene schätzt das System die wichtigsten Beleuchtungsbedingungen, erstellt neu, wie die Szene unter diesen Bedingungen aussehen sollte, und baut eine konsistente 3D‑Darstellung auf. Das Ergebnis sind virtuelle Objekte, deren Helligkeit, Glanz und Schatten auf Ihre Umgebung reagieren wie echte Gegenstände und so Mixed‑Reality‑Erlebnisse ermöglichen, die weniger wie überlagerte Grafiken und mehr wie echte Ergänzungen der physischen Welt wirken.
Zitation: Hong, X., Xie, J., Sheng, J. et al. Single-view neural illumination estimation and editing for dynamic light field display. Light Sci Appl 15, 147 (2026). https://doi.org/10.1038/s41377-026-02234-4
Schlüsselwörter: Mixed‑Reality‑Beleuchtung, neuronale Lichtfelder, Einzelbild‑Relighting, Virtual‑Reality‑Displays, computational imaging