Clear Sky Science · de
Hochtaktiges Freiraum‑Optik In‑Memory‑Computing
Warum das für alltägliche intelligente Technik wichtig ist
Von selbstfahrenden Autos und Lieferdrohnen bis hin zu Hochfrequenzhandel und Fernoperationen müssen immer mehr Entscheidungen in Bruchteilen einer Sekunde getroffen werden, oft weit entfernt von großen Rechenzentren. Die heutige Elektronik hat Probleme, Schritt zu halten, ohne zu überhitzen oder Batterien zu leeren. Dieses Papier stellt eine neue Art lichtbasierter Recheneinheit vor, die Schlüsselaufgaben der künstlichen Intelligenz extrem schnell und mit geringem Energieaufwand ausführen kann und damit die Funktionsweise intelligenter Geräte am „Edge“ des Netzwerks grundlegend verändern könnte.
Licht als Rechenwerkzeug
Moderne KI beruht stark auf einer Grundoperation: dem Multiplizieren und Addieren großer Zahlen‑Gitter, vergleichbar mit dem wiederholten Verschieben einer kleinen Schablone über ein Bild und dem Aufsummieren der Werte. Das mit Elektronen auf Chips zu tun ist leistungsfähig, aber ineffizient, weil Daten ständig zwischen Speicher und Prozessoren hin- und hergeschoben werden müssen. Die Forschenden bauen stattdessen ein System namens FAST‑ONN, das viel der Arbeit dem Licht in der Luft überlässt. Sie verwenden winzige Halbleiterlaser in einem geordneten Raster, um Bildpixel als Lichtintensität zu kodieren, und lassen diese Strahlen durch optische Komponenten laufen, die die „Gewichte“ eines neuronalen Netzes direkt im Raum anwenden, bevor die Strahlen auf Lichtsensoren treffen, die die Ergebnisse wieder in elektrische Signale umwandeln.
Aufbau der optischen Recheneinheit
Im Zentrum des Systems steht ein dichtes Array mikroskopisch kleiner Laser, bekannt als vertical‑cavity surface‑emitting lasers (VCSELs). Jedes Gerät in einem 5×5‑Gitter repräsentiert ein Pixel eines kleinen Bildausschnitts und kann mit Gigahertz‑Geschwindigkeit ein- und ausgeschaltet werden — Milliarden Mal pro Sekunde. Ein gemustertes Glaselement teilt dieses Strahlenraster in mehrere Kopien, sodass derselbe Ausschnitt parallel von mehreren verschiedenen Filtern verarbeitet werden kann. Ein programmierbarer räumlicher Lichtmodulator, vergleichbar mit einem hochauflösenden Display, fungiert als In‑Memory‑Speicher für die Filterwerte: Millionen winziger Pixel dämpfen oder passieren Licht, um ein neuronales Netzwerkgewicht darzustellen. Die Strahlen laufen dann auf fasergekoppelte Detektoren zusammen, die das Licht für jeden Filter aufsummieren und damit effektiv einen Batch von Faltungsoperationen in einem optischen Schritt abschließen. 
Umgang mit positiven und negativen „Gedanken”
KI‑Modelle müssen nicht nur bestimmte Muster verstärken; sie müssen andere auch unterdrücken, was sowohl positive als auch negative Gewichte erfordert. Da Lichtintensität naturgemäß nie negativ ist, stellt das eine langjährige Herausforderung für rein optisches Rechnen dar. Die Autor:innen lösen das, indem sie das Licht in einen Signalpfad aufteilen, der die gewichteten Strahlen trägt, und einen Referenzpfad, der unbelastet bleibt. Beide werden in spezielle gepaarte Detektoren eingespeist, die eine Differenzbildung durchführen, sodass weniger Licht eine negative Beiträge repräsentieren kann. Diese clevere differentielle Auslesung erlaubt der optischen Hardware, das volle Verhalten Standard‑neuronaler Netze nachzuahmen und gleichzeitig robust gegenüber Rauschen und kleinen Fehlern in den Bauteilen zu bleiben.
Das System im Praxistest
Um zu zeigen, dass FAST‑ONN nicht nur ein physikalischer Demonstrator ist, koppelt das Team es an realistische Erkennungsaufgaben. Sie verbinden die optische Einheit mit einem Standard‑Visionsnetz, das auf dem COCO‑Bilddatensatz trainiert wurde, der weit verbreitet für Objekterkennungstests ist. In einem Experiment, das ein Szenario eines selbstfahrenden Autos nachbildet, werden zugeschnittene Bereiche von Verkehrsszenen analysiert, um zu entscheiden, ob sie ein Fahrzeug enthalten. Die anspruchsvollste Faltungsschicht wird an die optische Hardware ausgelagert, während die übrigen Schritte digital laufen. Die optische und die rein elektronische Version des Modells stimmen eng überein und erreichen nahezu identische Leistungen bei der Unterscheidung von Autos und Hintergrund. Sie demonstrieren außerdem Handschrifterkennung und Kleidungs‑Klassifikation und führen sogar Training durch, bei dem das optische System Vorwärtsdurchläufe berechnet, während ein Computer die Gewichte aktualisiert, die dann wieder in den Lichtmodulator geladen werden. 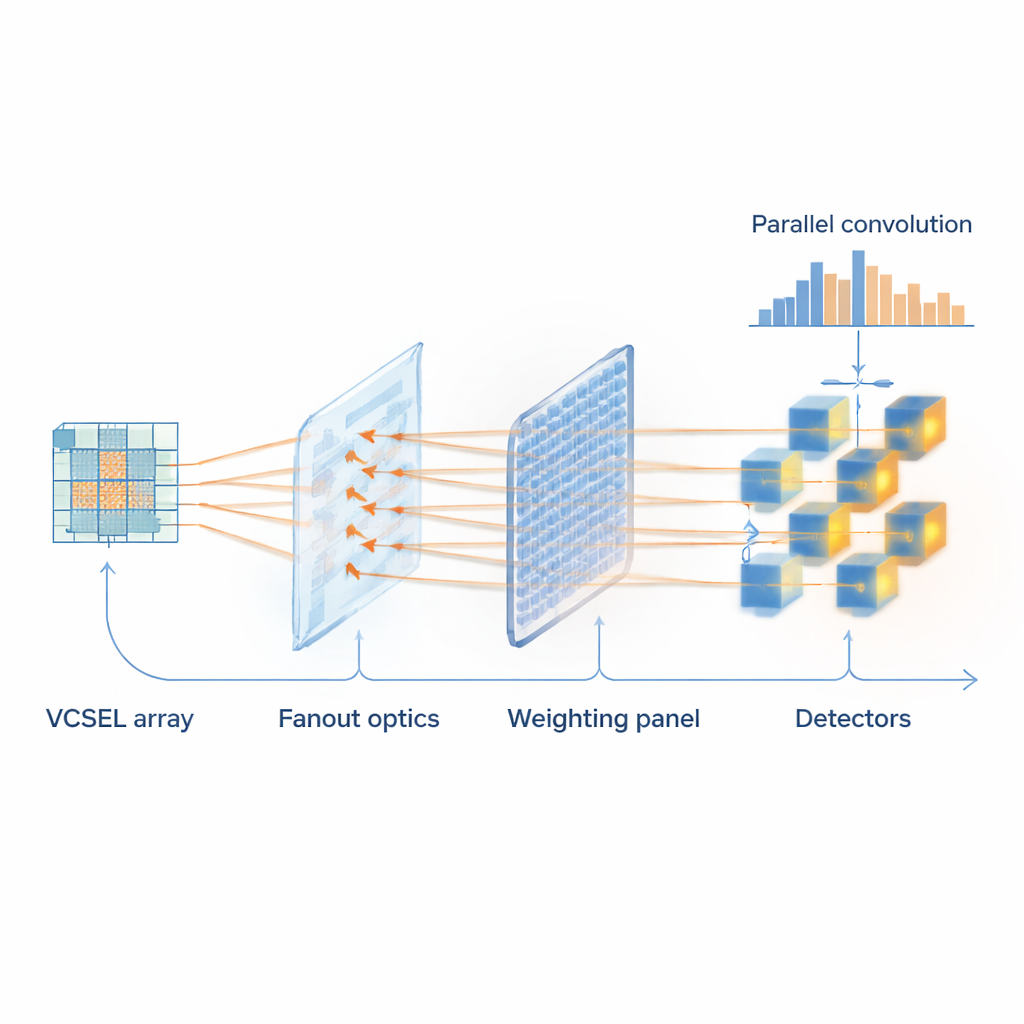
Geschwindigkeit, Effizienz und Ausblick
In seiner aktuellen Form verarbeitet der Prototyp 100 Millionen kleine Bildausschnitte pro Sekunde mit 5×5‑Lasern und neun Filtern gleichzeitig und erreicht damit bereits nahezu eine Milliarde Faltungsoperationen pro Sekunde bei Entscheidungszeiten im Mikrosekunden‑Bereich. Detaillierte Analysen legen nahe, dass sich dieser Ansatz mit größeren Arrays und schnelleren kommerziellen Lasern auf Zehntausende von Billiarden Operationen pro Sekunde skalieren ließe, bei deutlich geringerem Energieverbrauch als führende elektronische Beschleuniger. Da die Schlüsselkomponenten kompakt und in Serie herstellbar sind, könnte FAST‑ONN schließlich winzige, energiesparende optische Coprozessoren in Kameras, Drohnen und anderen Edge‑Geräten ermöglichen, die mit Licht „denken“ und fast so schnell auf die Welt reagieren, wie sie sich verändert.
Zitation: Liang, Y., Wang, J., Xue, K. et al. High-clockrate free-space optical in-memory computing. Light Sci Appl 15, 115 (2026). https://doi.org/10.1038/s41377-026-02206-8
Schlüsselwörter: optische neuronale Netze, Edge‑KI‑Hardware, VCSEL‑Arrays, In‑Memory‑Computing, Hochgeschwindigkeits‑Faltung