Clear Sky Science · de
Mit Mikrokämmen ermöglichter paralleler, selbstkalibrierender optischer Faltungs‑Streaming‑Prozessor
Warum schnellere Denkmaschinen wichtig sind
Von Streaming‑Video bis zum Training massiver KI‑Modelle versinken moderne Rechenzentren in Daten. Diese Daten mit heutigen elektronischen Chips zu verschieben und zu verarbeiten, verbraucht enorme Mengen Energie und stößt an Geschwindigkeitsgrenzen. Dieses Paper stellt einen neuen, lichtbasierten Rechenchip vor, der als schneller, energieeffizienter „Frontend“ für KI‑Systeme fungieren kann und einen Teil der rechenintensiven Aufgaben übernimmt, noch bevor die Daten konventionelle Prozessoren erreichen.
Das Licht die schwere Arbeit erledigen lassen
Die meisten KI‑Systeme beruhen auf Faltung, einer Art gleitendem mathematischen Fenster, das Bilder, Ton oder andere Signale durchsucht, um Merkmale wie Kanten oder Texturen zu erkennen. Elektronische Systeme führen diese Operationen Schritt für Schritt aus und verschieben dabei Zahlen hin und her im Speicher. Der hier beschriebene Chip ersetzt das durch einen physikalischen Prozess, bei dem Lichtstrahlen gespalten, verzögert, gewichtet und wieder zusammengeführt werden. Da die Berechnung während der Lichtausbreitung stattfindet, entfallen viele der Datenbewegungen, die elektronische Hardware verlangsamen und erwärmen, und es sind Betriebsraten von Dutzenden Milliarden Operationen pro Sekunde pro Datenstrom möglich.
Viele Lichtfarben, viele Aufgaben zugleich
Ein zentrales Element ist ein sogenannter Mikrokamm: eine winzige, ringförmige Laserquelle, die Dutzende gleichmäßig voneinander getrennte Farben bzw. Wellenlängen erzeugt. Jede Farbe funktioniert wie eine eigene Spur auf einer Hochgeschwindigkeits‑Optikautobahn. Der optische Faltungs‑Streaming‑Prozessor des Teams schickt all diese Farben durch denselben Chip, ordnet die Pfade jedoch so an, dass sie denselben „Faltungs‑Kernel“—das Gewichtset zur Analyse der Daten—durchlaufen. Zeitverzögerungen zwischen den Pfaden kombiniert mit den unterschiedlichen Wellenlängen schaffen eine dreidimensionale Form von Parallelismus in Zeit, Raum und Wellenlänge. In Experimenten verarbeitete das System Daten mit 50 Gigabaud pro Farbe und erreichte über fünf Wellenlängen eine Gesamtrechengeschwindigkeit von etwa 4 Billionen Operationen pro Sekunde.
Dem Lichtchip beibringen, genau zu bleiben
Rechnen mit Interferenz zwischen Lichtwellen ist leistungsfähig, aber empfindlich: Nanometer‑große Änderungen der Pfadlänge können die sorgfältig eingestellten Gewichte zerstören. Um die Genauigkeit des Chips zu bewahren, integrierten die Forscher einen speziellen Referenzpfad und ein Selbstkalibrierungsverfahren. Durch das Durchstimmen eines Lasers über Frequenzen und das Messen nur der Ausgangsleistung rekonstruieren sie sowohl die Stärke als auch die Phase jedes Pfads im Gerät. Eine Rückkopplungsschleife stellt dann winzige Heizungen auf dem Chip so ein, bis die gemessenen Faltungsgewichte den gewünschten entsprechen. Diese automatische Feinabstimmung korrigiert nicht nur Fertigungsfehler und Temperaturdrift, sie erlaubt auch, denselben Chip für verschiedene Aufgaben neu zu programmieren, etwa zum Weichzeichnen oder zur Kantenerkennung in Bildern.
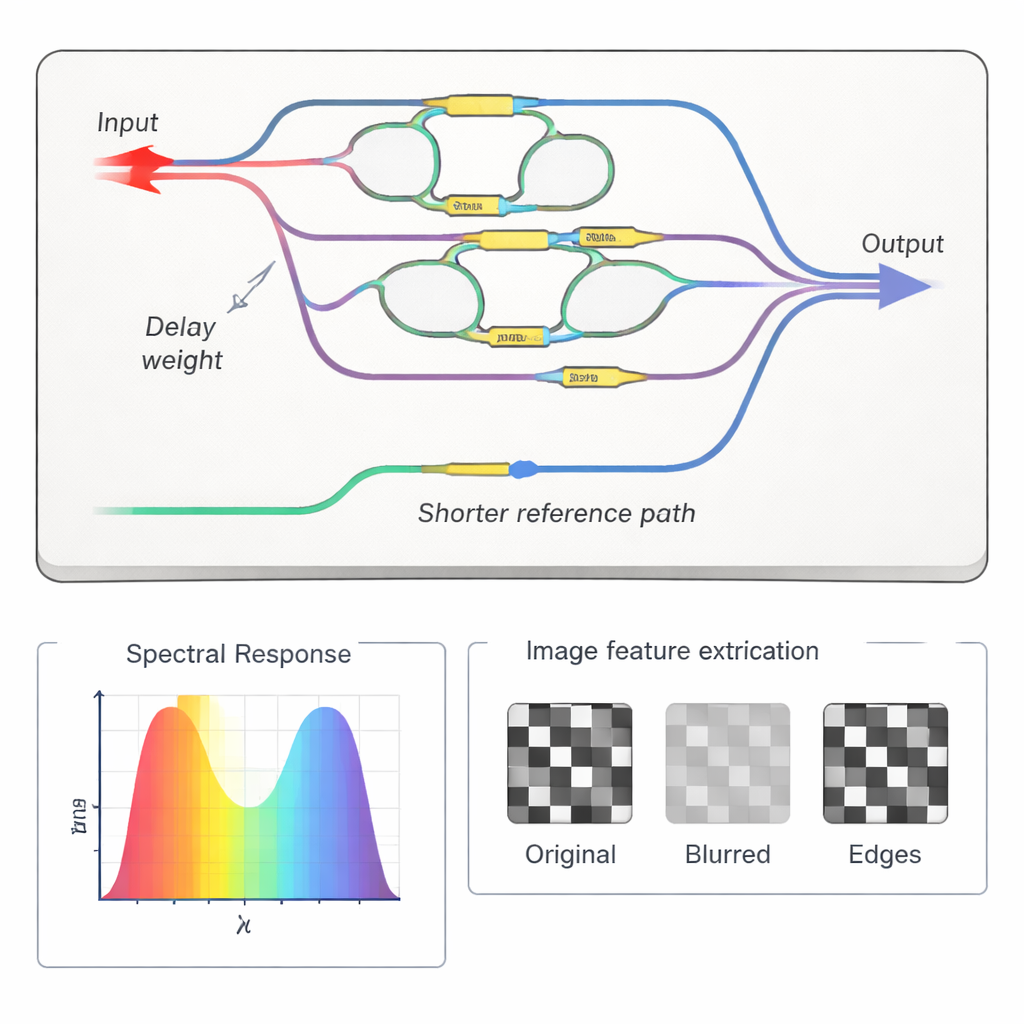
Von Bildfiltern zu echten KI‑Workloads
Um zu zeigen, dass der Prozessor über einfache Demos hinaus nützlich ist, kombinierten die Autoren ihn mit standardmäßigen elektronischen Neuronalschichten in einem hybriden System. Der optische Chip übernahm die erste Faltungsschicht und extrahierte Grundmerkmale aus Farbbildern, die über mehrere Wellenlängenkanäle übertragen wurden. Die resultierenden Merkmalsströme wurden zurück in die Elektronik konvertiert und in ein tieferes digitales Netzwerk eingespeist. Getestet am CIFAR‑10‑Bilddatensatz, der Klassen wie Flugzeuge, Katzen und LKW enthält, kam das gemischte optisch‑elektronische System nahe an die Genauigkeit eines vollständig digitalen Modells heran, während ein Teil der rechenintensiven Arbeit in die photonenbasierte Domäne ausgelagert wurde.
Was das für künftige Rechenzentren bedeuten könnte
Kurz gesagt zeigt diese Arbeit, dass winzige Chips, die mit Licht rechnen, direkt an vorhandene Glasfaserverbindungen in Rechenzentren angeschlossen werden können und als gemeinsame Beschleuniger für KI‑Workloads dienen. Durch die Kombination vieler Lichtfarben, mehrerer Verzögerungspfade und einer eingebauten Selbstkalibrierungsmethode erreicht der demonstrierte Prozessor sehr hohe Geschwindigkeiten und gute Genauigkeit bei moderatem Energieeinsatz. Bei entsprechender Skalierung könnten ähnliche Geräte zwischen Speicher‑ und Rechner‑Racks sitzen, Daten beim Fluss schnell filtern und Merkmale extrahieren und so dazu beitragen, künftige „denkende“ Maschinen schneller und energieeffizienter zu machen.
Zitation: Wang, J., Xu, X., Zhu, X. et al. Microcomb-enabled parallel self- calibration optical convolution streaming processor. Light Sci Appl 15, 149 (2026). https://doi.org/10.1038/s41377-025-02093-5
Schlüsselwörter: optisches Rechnen, photonische KI‑Hardware, Mikrokamm, Beschleunigung von Rechenzentren, Faltungsneuronale Netze