Clear Sky Science · de
Multimodale Bilderkennung für Kulturerbe basierend auf einem quanten-klassischen multimodalen Fusionsnetzwerk
Warum es wichtig ist, Computern alte Schätze beizubringen
Kulturelle Schätze in Museen und Archiven werden zunehmend fotografiert und online gestellt, doch die meisten dieser Bilder sind spärlich oder gar nicht beschriftet. Das erschwert es Besuchern, Lehrenden und Forschenden, Gesuchtes zu finden, und begrenzt, wie tief die Öffentlichkeit das gemeinsame Erbe der Menschheit erkunden kann. Diese Arbeit untersucht einen neuen Weg, solche Bilder automatisch zu erkennen und zu sortieren, indem zwei selten zusammengeführte Ideen kombiniert werden: Museumsbestände und Quantencomputing.
Von staubigen Depots zu digitalen Sammlungen
Museen beherbergen heute Millionen von Objekten, von Bronzearbeiten und Lackkunst bis zu bestickten Gewändern. Viele Institutionen arbeiten daran, diese Bestände zu digitalisieren, sodass jeder mit Internetzugang stöbern kann. Sobald Bilder jedoch online sind, müssen sie in die richtigen Kategorien eingeordnet werden – etwa Emaille, Jade, Seide oder Brokat –, damit sie wirklich nützlich sind. Konventionelle KI-Werkzeuge betrachten meist nur die Pixel eines Bildes. Sie übergehen die reichen Textbeschreibungen, die Kuratorinnen und Historiker den Objekten hinzufügen, obwohl diese Bildunterschriften oft Materialien, Farben und Motive nennen, die nicht sofort sichtbar sind. Mit zunehmender Größe der Sammlungen stoßen klassische Algorithmen zudem an Grenzen in puncto Geschwindigkeit, Energieverbrauch und Komplexität.
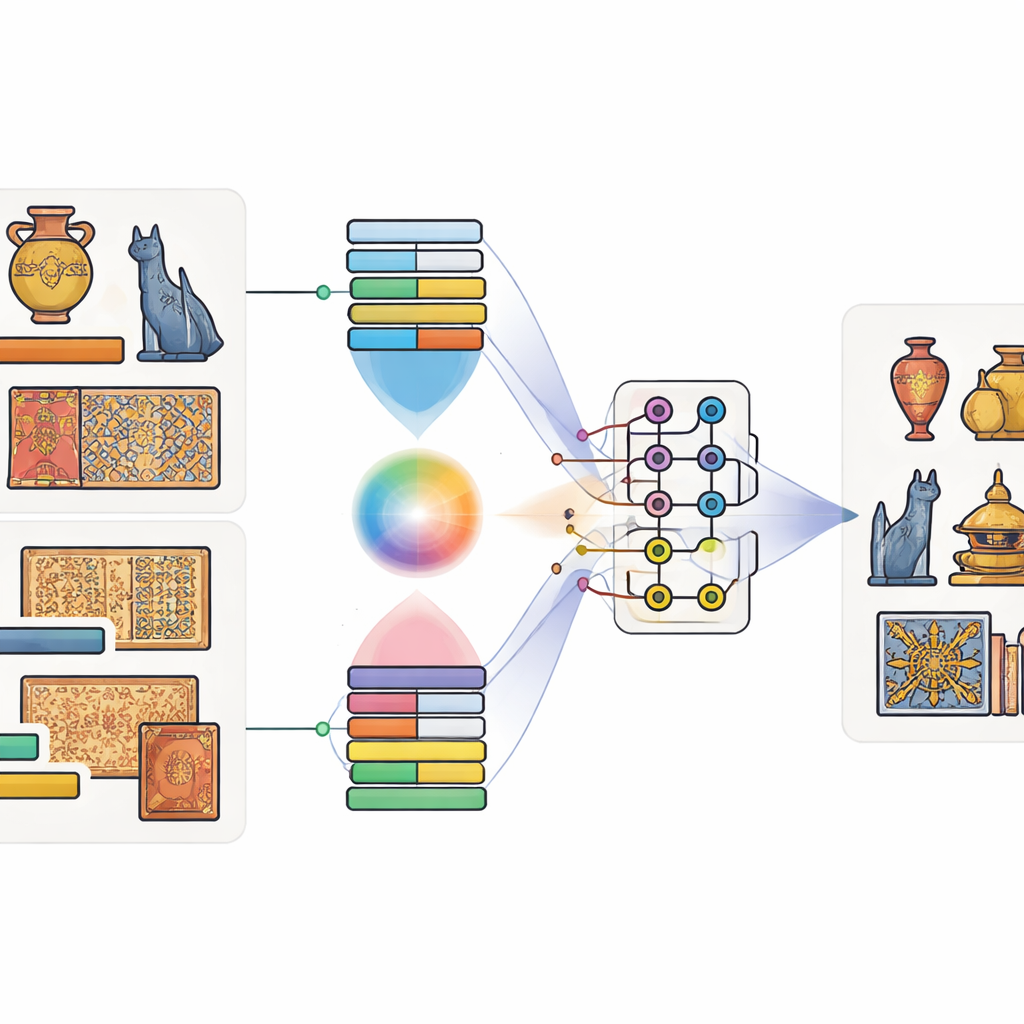
Bilder mit Worten paaren, Bits mit Qubits
Die Autorinnen und Autoren schlagen ein Modell vor, das sie Quantum-Classical Multimodal Fusion Model nennen. „Multimodal“ bedeutet schlicht, dass es mehr als eine Informationsart zugleich berücksichtigt – hier sowohl das Bild eines Objekts als auch seine Bildunterschrift. Zunächst kommen bewährte Werkzeuge zum Einsatz, die auf sehr großen Datensätzen trainiert wurden: ein tiefes Bildnetzwerk, das Formen und Texturen erfasst, und ein Sprachmodell, das die Bedeutung der Caption erfasst. Ein spezieller Attention-Mechanismus lernt anschließend, welche Bildregionen typischerweise zu welchen Wörtern gehören. Wenn etwa in einer Bildunterschrift „goldener Drache“ steht, lernt das Modell, sich auf goldfarbene Bereiche in drachenähnlicher Form zu konzentrieren. So entsteht eine gemeinsame Beschreibung, die Sehen und Sprache verbindet.
Quanten-Schaltkreise die Signale mischen lassen
Sind die Bild- und Textmerkmale extrahiert, werden sie in einen kleinen simulierten Quanten-Schaltkreis eingespeist. Da heutige Quantenhardware nur über eine begrenzte Zahl von Qubits verfügt, verdichten die Autorinnen und Autoren die Informationen mithilfe eines Schemas, das viele klassische Werte in den Amplituden weniger Qubits unterbringt. Im quantenbasierten Teil entwerfen sie einen zweistufigen Schaltkreis, der wiederholt Rotationengates auf einzelne Qubits anwendet und sie dann verschränkt – wodurch ihre Zustände voneinander abhängig werden. Diese Struktur soll subtile Beziehungen zwischen visuellen Mustern und sprachlichen Hinweisen herausarbeiten, die ansonsten übersehen würden. Nach der quantenmechanischen Verarbeitung werden die Qubit-Zustände gemessen und zurück in gewöhnliche Zahlen umgewandelt, die dann an einen abschließenden Klassifikator weitergegeben werden, der die Objektkategorie vorhersagt.
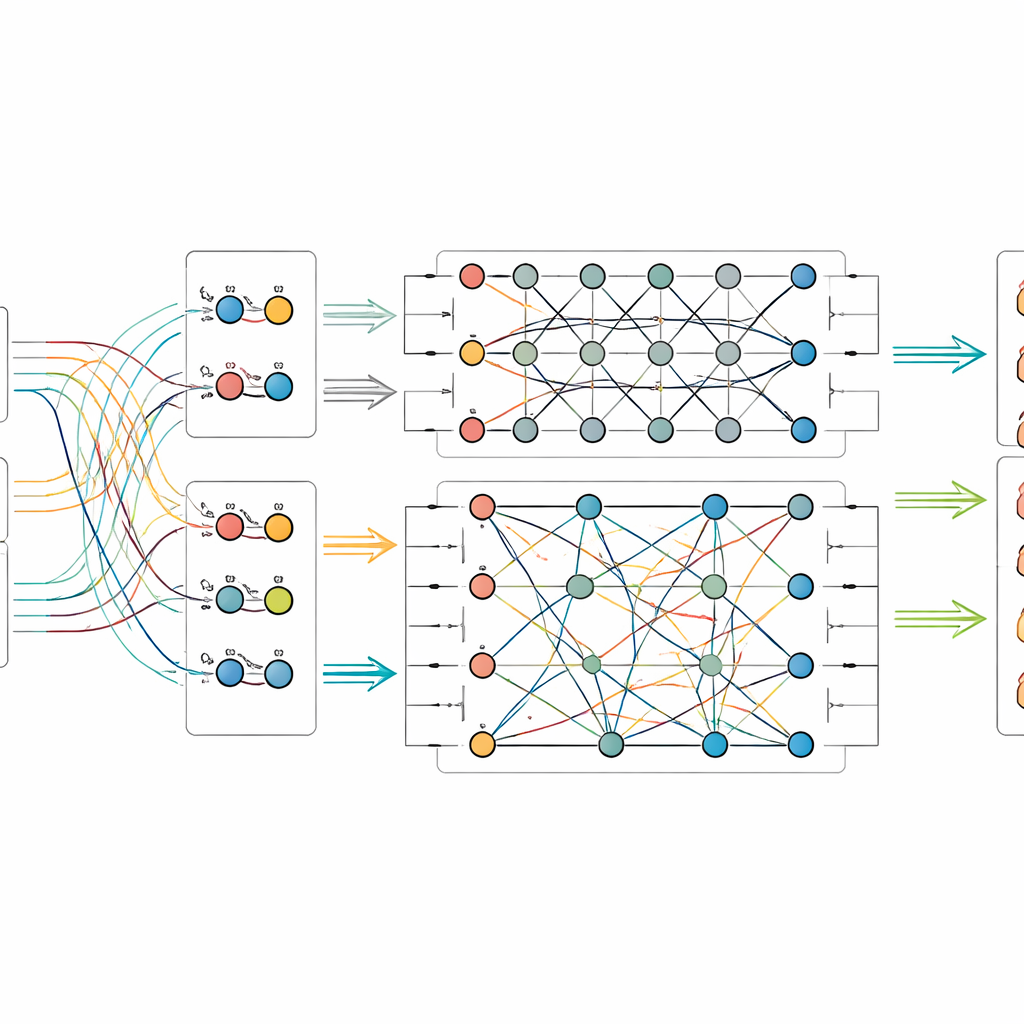
Die neue Methode auf die Probe gestellt
Um zu prüfen, ob ihre Methode echte Vorteile bringt, stellten die Forschenden zwei neue Datensätze aus dem Palastmuseum zusammen: einen mit physischen Objekten wie Emaille, Gold- und Silberarbeiten, Lack-, Bronze- und Jadeobjekten und einen zweiten mit Textilien wie Seide, Satin, Brokat und dem komplexen Webstil Kesi. Jedes Bild ist mit einer offiziellen Bildunterschrift und einem verlässlichen Label aus den Museumsunterlagen versehen. Sie verglichen ihr quanten-klassisches Fusionsmodell mit einer Reihe starker Konkurrenten, darunter reine Bildsysteme, reine Textsysteme und andere Verfahren, die beides kombinieren. In beiden Datensätzen erzielte das neue Modell die höchsten Werte bei Genauigkeit und verwandten Metriken und übertraf damit sogar fortgeschrittene multimodale und quanteninspirierte Baselines. Weitere Experimente zeigten, wie die Leistung von der Anzahl der Qubits und der Schaltkreistiefe abhängt, und dass das Modell auch dann zuverlässig bleibt, wenn in Simulationen gängige Arten von Quantenrauschen hinzugenommen werden.
Was das für künftige Museumsbesucher bedeuten könnte
Für Nichtfachleute ist die zentrale Botschaft, dass die Kombination von Bildern, Texten und quanteninspirierter Verarbeitung Computer darin verbessern kann, verschiedene Arten kultureller Objekte zu unterscheiden. Obwohl die Quantenkomponenten derzeit auf Simulatoren laufen statt auf vollausgebauten Quantenmaschinen, weist die Studie einen Weg zu effizienteren und ausdrucksstärkeren Werkzeugen, wenn die Hardware reift. Praktisch könnten solche Systeme Museen und Archiven helfen, neue Uploads automatisch zu sortieren, alte Aufzeichnungen zu bereinigen und es Menschen zu erleichtern, nach „Jade-Ritualgefäßen“ oder „bestickten Drachengardebenen“ zu suchen und sie tatsächlich zu finden. Die Arbeit deutet darauf hin, dass Quantencomputing eine nützliche neue Route werden könnte, um kulturelles Erbe im digitalen Zeitalter zu verstehen und zu bewahren.
Zitation: Fan, T., Wang, H., Zhao, Y. et al. Multimodal cultural heritage image recognition based on quantum and classical multimodal fusion network. npj Herit. Sci. 14, 160 (2026). https://doi.org/10.1038/s40494-026-02419-5
Schlüsselwörter: Bilder des Kulturerbes, quantum machine learning, multimodale Fusion, Digitalisierung von Museen, Bilderkennung