Clear Sky Science · de
Identifikation visueller Informationen und Q&A zu Erben des immateriellen Kulturerbes mithilfe eines erweiterten Graph-Retrieval-Frameworks
Verborgene Traditionen ins digitale Zeitalter bringen
In ganz China bewahren Meister der traditionellen Oper, Scherenschnittkunst, Schattenspielerei und anderer lebendiger Künste Fertigkeiten, die über Generationen weitergegeben wurden. Vieles von dem, was wir über diese Überlieferer wissen, liegt jedoch nur verstreut in Dateien und Bildern im Internet vor, wodurch es für die Öffentlichkeit – oder sogar für Forschende – schwierig wird, verlässliche Informationen zu finden. Dieser Beitrag stellt ein neues Computerframework vor, das automatisch die „visuellen Visitenkarten“ der Erben des immateriellen Kulturerbes (ICH) ausliest und anschließend fortgeschrittene Sprachmodelle nutzt, um Fragen zu beantworten und lesbare Berichte über sie zu erzeugen.
Von Bildkarten zu strukturiertem Wissen
Viele Kultureinrichtungen veröffentlichen inzwischen digitale Karten, die Text, Layout und einfache Grafiken kombinieren, um jeden Überlieferer vorzustellen: Name, Handwerk, Herkunft, Biografie und mehr. Menschen können diese Karten auf einen Blick erfassen, aber Computer tun sich schwer, weil die Karten aus vielen Regionen stammen, unterschiedliche Designs verwenden und oft fehlende oder beschädigte Texte enthalten. Die Autorinnen und Autoren erstellen einen großen Datensatz von 5.237 solchen Visitenkarten chinesischer ICH-Überlieferer, die jeweils sorgfältig mit zehn wichtigen Informationstypen annotiert sind, etwa Projektnummer, Projektname, Region, Geschlecht, Arbeitseinheit und eine Kurzbeschreibung. Sie nutzen zunächst optische Zeichenerkennung (OCR), um den Text zu lesen und zu vermerken, wo jeder Ausschnitt auf der Karte erscheint, und setzen dann große Sprachmodelle ein, um Labels zu standardisieren, bevor Expertinnen und Experten die Ergebnisse prüfen.
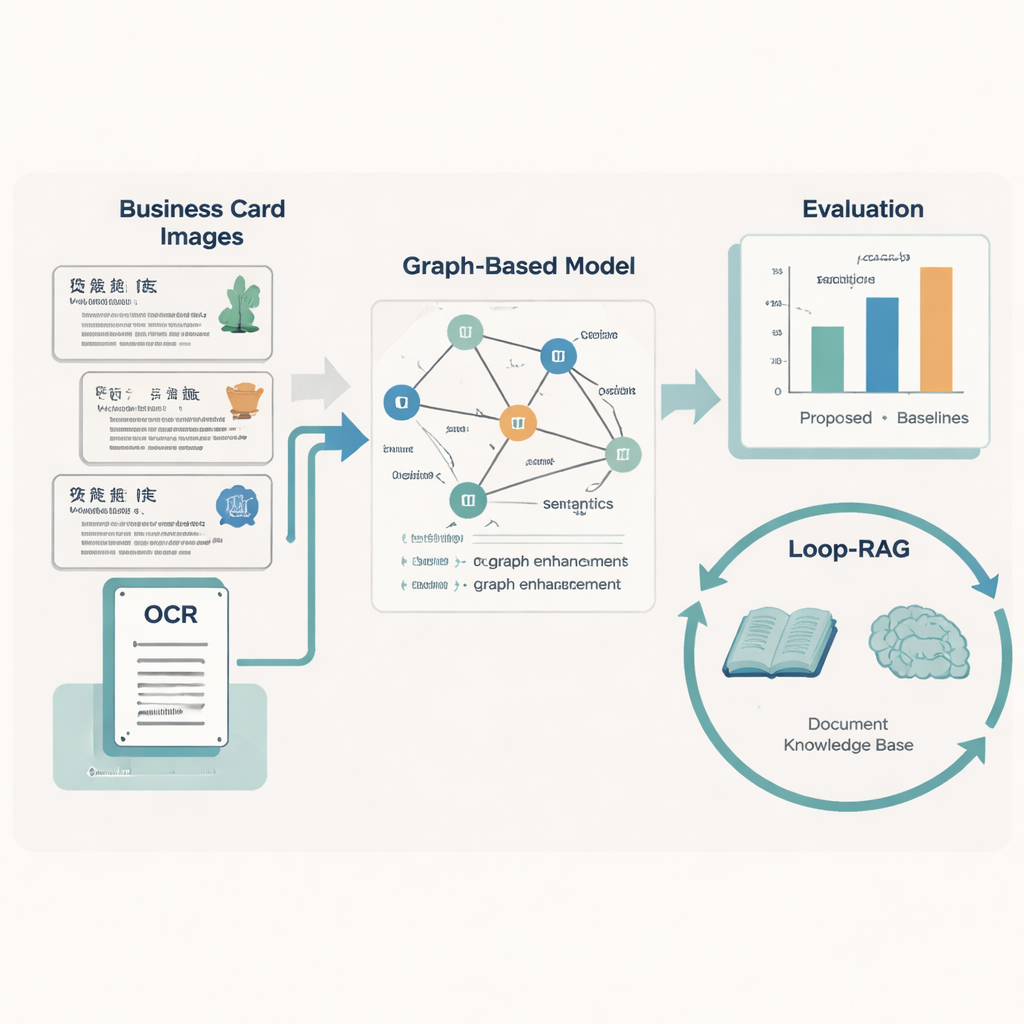
Maschinen das Lesen von Layout und Bedeutung beibringen
Um jede Karte in saubere, strukturierte Daten zu überführen, entwickelt das Team ein „Graph-Retrieval“-Modell, das nachahmt, wie Menschen sowohl Wörter als auch Layout verwenden. Jeder Textfragment auf einer Karte wird zu einem Knoten in einem Graphen, und die räumlichen Beziehungen zwischen Fragmenten – links, rechts, oberhalb, unterhalb – bilden die Kanten. Eine sprachliche Komponente auf Basis von RoBERTa und einem bidirektionalen LSTM lernt die Bedeutung des Textes, unterstützt durch ein eigenes Wörterbuch mit nahezu 5.000 ICH-spezifischen Begriffen, damit ungewöhnliche Handwerksbezeichnungen oder lokale Ausdrücke korrekt behandelt werden. Darüber hinaus verteilt ein graphneuronales Netzwerk Informationen über benachbarte Knoten hinweg, wodurch die Vorhersagen darüber verbessert werden, welche Rolle ein Textfragment hat (beispielsweise ob ein Ortsname eine Region oder eine Arbeitseinheit bezeichnet).
Das System robust gegen Unschärfen der Praxis machen
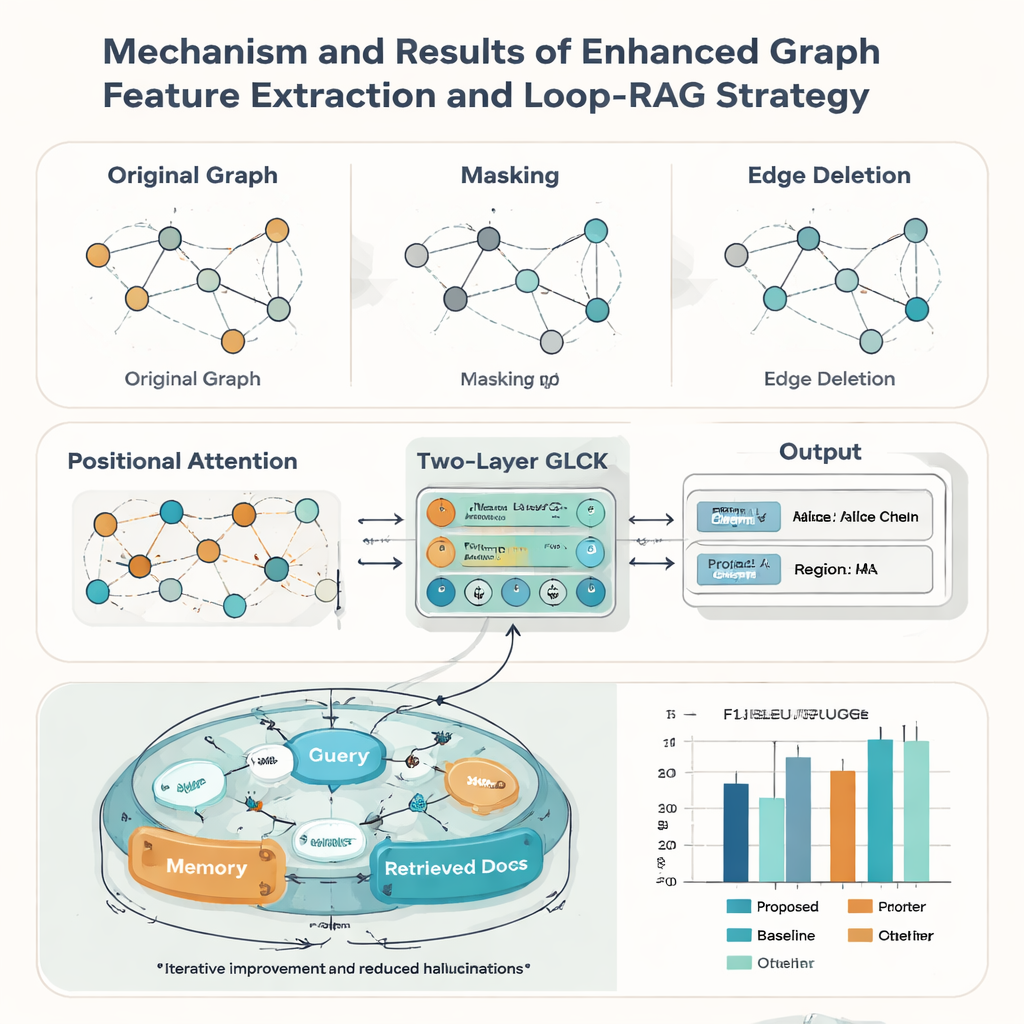
Reale Kulturdokumente sind selten perfekt: Karten können abgenutzt, beschnitten oder schlecht gescannt sein. Um damit umzugehen, stärken die Autorinnen und Autoren ihr Graph-Modell mit drei Ideen aus der Datenaugmentation. Sie maskieren zufällig einige Knoten, sodass das System lernt, fehlende Informationen aus dem Kontext zu schließen; sie löschen zufällig einige Kanten, damit es Layoutveränderungen toleriert; und sie fügen einen Positions-Attention-Mechanismus hinzu, der die allgemeine „Lesereihenfolge“ der Elemente auf einer Karte erfasst. Zusammen helfen diese Tricks dem Modell, auf viele Stile und Qualitätsstufen von Dokumenten zu generalisieren. In Tests gegen neun bekannte Konkurrenzmethoden erreicht der neue Ansatz die höchste makro-durchschnittliche F1-Score (0,928) auf dem ICH-Kartendatensatz und führt zudem bei fünf öffentlichen Dokumenten-Benchmarks, was darauf hindeutet, dass er über den Bereich des Kulturerbes hinaus nützlich ist.
Intelligentere Fragebeantwortung mit Looping Retrieval
Das Erkennen des Textes ist nur die halbe Geschichte; der zweite Beitrag der Arbeit ist eine Loop-RAG-Strategie (Loop Retrieval-Augmented Generation), die mit großen Sprachmodellen wie GPT-4, Llama und ChatGLM zusammenarbeitet. Traditionelle retrieval-unterstützte Systeme holen Hintergrunddokumente einmal ab und generieren dann eine Antwort, die dennoch unvollständig oder falsch sein kann. Im Gegensatz dazu fügt Loop-RAG eine innere Schleife hinzu, die wiederholt prüft, ob das Sprachmodell für die aktuelle Antwort über ausreichende Informationen verfügt und, falls nicht, eine weitere gezielte Suche in einer vektorisierten ICH-Wissensdatenbank auslöst. Eine äußere Schleife analysiert anschließend viele vergangene Interaktionen, um zu lernen, welche Abrufpfade und Prompt-Stile am besten funktionieren, und reduziert so nach und nach unnötige Suchvorgänge und faktische Fehler.
Von Rohdaten zu verlässlichen kulturellen Erzählungen
Mit diesem kombinierten Framework kann das System automatisch kurze Berichte über einen Überlieferer erstellen – die sein Handwerk, seine Region, repräsentative Werke und seinen Status zusammenfassen – und Tausende faktischer Fragen über Personen und Praktiken beantworten. Gemessen an gängigen Sprachqualitätsmetriken wie BLEU, METEOR und ROUGE übertrifft Loop-RAG mit GPT-4 sowohl einfache Sprachmodelle als auch einfachere Retrieval-Setups und erzielt gleichzeitig die beste Genauigkeit (F1 bis zu 0,941) in der Fragebeantwortung, selbst wenn nur wenige Beispiele vorliegen. Für eine nicht fachliche Leserschaft bedeutet das: Zukünftige Plattformen zum Kulturerbe könnten interaktive, vertrauenswürdige Erklärungen zu traditionellen Künsten auf Abruf bieten und verstreute digitale Aufzeichnungen in reichhaltige, navigierbare Erzählungen verwandeln, die dazu beitragen, lebendige Traditionen sichtbar und geschätzt zu halten.
Zitation: Wang, R., Zhang, X., Liu, Q. et al. Visual information identification and Q&A of intangible cultural heritage inheritors by using enhanced Graph-Retrieval framework. npj Herit. Sci. 14, 113 (2026). https://doi.org/10.1038/s40494-026-02384-z
Schlüsselwörter: immaterielles Kulturerbe, Informationsextraktion, Graph-Neuronale Netzwerke, retrieval-unterstützte Generierung, digitale Geisteswissenschaften