Clear Sky Science · de
Semantische Segmentierung von Buddha-Gesichtspunktwolken durch wissensgeführtes Region Growing
Das Gesicht der Geschichte lesen
In Fels gehauene oder an Tempelwände gearbeitete Buddha-Statuen sind mehr als schöne Kunstwerke – sie sind dreidimensionale Aufzeichnungen religiöser Überzeugungen, künstlerischer Moden und kulturellen Austauschs über Jahrhunderte. Diese Studie zeigt, wie Informatiker und Denkmalpflege-Expertinnen diese steinernen Gesichter im Detail „lesen“ können, indem sie Augen, Nase, Mund und andere Merkmale automatisch aus dichten 3D-Messungen separieren, selbst wenn es keine beschrifteten Beispiele zum Lernen gibt. Ziel ist es, stummen Stein in messbare Daten zu verwandeln, die Historiker beim Vergleich von Stilen, der Nachverfolgung von Veränderungen im Lauf der Zeit und der Planung sorgfältiger Konservierungsmaßnahmen unterstützen.
Warum digitale Gesichter wichtig sind
An berühmten Stätten wie Dunhuang, Yungang und Longmen unterscheiden sich Buddha-Gesichter dezent nach Dynastie und Region – teils runder, teils schlanker, mit weicheren Augen oder markanteren Nasen. Traditionell beschreiben Kunsthistoriker diese Unterschiede visuell; mittlerweile erfassen hochpräzise 3D-Scans die Oberfläche von Statuen als Millionen Punkte im Raum. Diese „Punktwolken“ sind jedoch unübersichtlich: sie besitzen keine Farbe oder Textur und enthalten keinen eingebauten Hinweis darauf, wo das Auge endet und die Wange beginnt. Bestehende automatische Verfahren benötigen entweder viele manuell beschriftete Trainingsbeispiele, die für Kulturgüter kaum verfügbar sind, oder sie teilen Flächen rein geometrisch, ohne die bildhauerischen Regeln zu berücksichtigen, denen die Künstler tatsächlich folgten.

Algorithmen die Regeln des Gesichts beibringen
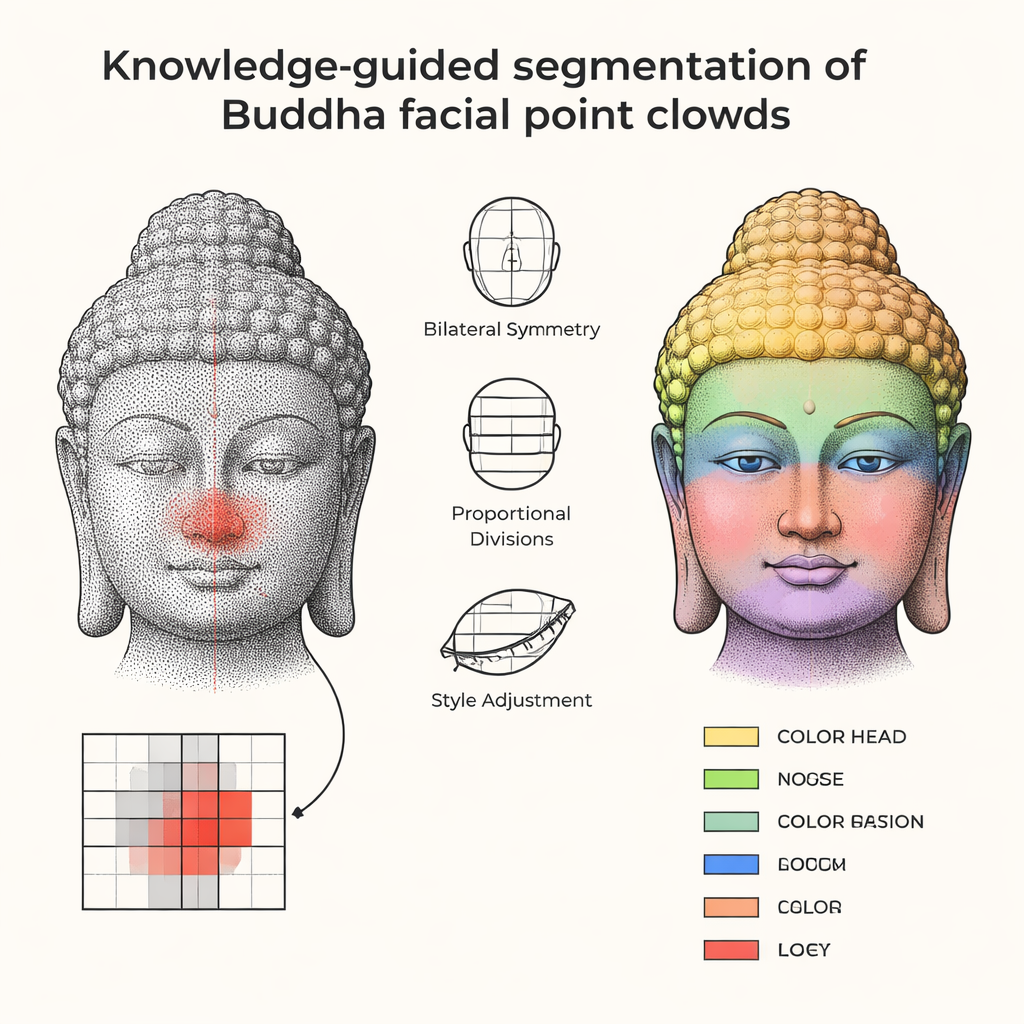
Anstatt aus knappen Daten lernen zu wollen, starten die Autorinnen und Autoren mit dem Wissen, das Bildhauer selbst nutzten. Traditionelle buddhistische Handbücher beschreiben standardisierte Gesichtsproportionen, etwa die Dreiteilung von Stirn, Nase und Kinn, und die Symmetrie der Merkmale um eine Mittelachse. Die Forschenden übersetzen dieses kulturelle und anatomische Know-how in einfache geometrische Regeln: eine Symmetrieebene in der Mitte; eine vertikale Linie durch die Nasenmitte; und Verhältnisse, die Positionen und Größen von Augen, Nase, Mund, Ohren und Kinn miteinander in Beziehung setzen. Diese Regeln sind keine starren Schablonen: sie enthalten anpassbare Parameter, sodass sowohl vollere Tang‑Stil‑Gesichter als auch schlankere Song‑Stil‑Gesichter innerhalb eines flexiblen, aber erkennbaren Rahmens abgedeckt werden können.
Regionen aus Samen wachsen lassen
Ausgehend von einem bereinigten 3D-Scan richtet die Methode das Buddha-Gesicht zunächst so aus, dass es geradeaus blickt, und projiziert dann die Oberfläche auf ein quadratisches Gitter, wodurch die 3D-Form etwas wie eine schattierte Höhenkarte wird. Innerhalb dieses Gitters wählt der Algorithmus Start‑„Samen“ für jedes Gesichtsmerkmal, unterstützt durch die vorgegebenen Regeln: der Nasensamen liegt nahe der zentralen Vertikalen und einem lokalen Höhenmaximum, die Augen werden als symmetrische Gipfel links und rechts platziert, der Mund befindet sich unter der Nase in einer flachen Mulde, und so weiter. Von jedem Samen „wächst“ der Computer eine Region nach außen und fügt benachbarte Zellen nur dann hinzu, wenn deren Höhe und Neigung dem entsprechen, was man eher für einen Nasenrücken als für eine Wange erwarten würde. Zusätzliche Schritte bereinigen das Ergebnis, schneiden Ausreißer ab, füllen kleine Lücken und glätten Konturen behutsam, damit die segmentierten Augen, Lippen und das Kinn sowohl für die Maschine als auch für Fachleute kontinuierlich und plausibel wirken.
Prüfung der Methode
Das Team testete seinen Ansatz an fünfzehn Buddha-Gesichtern – neun synthetischen Modellen mit kontrollierten Formen und sechs realen Scans von renommierten chinesischen Kulturerbestätten. Die Qualität wurde daran gemessen, wie gut sich die automatisch segmentierten Bereiche mit sorgfältig von Spezialistinnen und Spezialisten gezeichneten Umrissen überschneiden und wie genau die berechneten Grenzen den Konturen der Expertinnen und Experten entsprechen. Über Augen, Augenbrauen, Ohren, Nase, Mund und Kinn erzielte die Methode hohe Werte, was bedeutet, dass die meisten Punkte korrekt dem jeweiligen Merkmal zugewiesen wurden. Wichtig ist, dass die Ergebnisse über verschiedene Bildhauerstile und Verschleißgrade hinweg stabil blieben. Im Vergleich mit einem populären Deep‑Learning‑Modell, das nur mit wenigen beschrifteten Beispielen trainiert wurde, schnitt das datenhungrige Netzwerk schlecht ab, während die wissensgeführte Methode ohne große Trainingsmengen genau blieb.
Was das für das kulturelle Erbe bedeutet
Indem traditionelle Messregeln der Bildhauer in einen modernen Algorithmus kodiert werden, zeigt diese Studie, dass Computer Buddha-Gesichter in 3D mit wenig oder gar keiner manuellen Beschriftung segmentieren können und dabei die kulturelle Logik der Originalwerke respektieren. Für Historikerinnen und Historiker eröffnet dies die Möglichkeit systematischer, quantitativer Vergleiche von Gesichtsformen über Stätten und Zeiträume hinweg; für Konservatorinnen und Konservatoren bietet es ein präzises Mittel zur Überwachung von Schäden oder zur Führung digitaler Restaurierungen. Im Kern macht die Methode jahrhundertealte Konventionen über das ideale Buddha-Gesicht zu einem praktischen Werkzeug, um die steinernen Gesichter zu lesen, zu bewahren und zu verstehen, die seit mehr als tausend Jahren über Tempel und Grotten wachen.
Zitation: Wei, S., Hou, M., Yang, S. et al. Semantic segmentation of Buddha facial point clouds through knowledge-guided region growing. npj Herit. Sci. 14, 109 (2026). https://doi.org/10.1038/s40494-026-02377-y
Schlüsselwörter: 3D-Scannen von Buddha-Statuen, Digitalisierung des kulturellen Erbes, Segmentierung von Punktwolken, Gesichtsproportionen in der Kunst, wissensgeführte Algorithmen