Clear Sky Science · de
Geo-TCAM: eine Thangka-Beschreibungsmethode, die Themenmodellierung mit geometriegeleiteter räumlicher Aufmerksamkeit verbindet
Alte Kunst trifft auf intelligente Technologie
Thangka-Malereien – die lebhaft gefärbten Rollbilder, die man in vielen tibetischen Tempeln sieht – sind voller winziger Details und mehrschichtiger religiöser Bedeutungen. Für Museumsbesucher oder Online-Betrachter ohne Fachwissen bleibt ein Großteil dieser Symbolik schwer verständlich. Diese Studie stellt Geo‑TCAM vor, ein System der künstlichen Intelligenz (KI), das automatisch reichhaltige, präzise Beschreibungen von Thangka-Bildern erzeugt und Menschen weltweit dabei hilft, dieses einzigartige Kulturerbe besser zu verstehen und zu bewahren.
Warum Thangka-Bilder für Computer schwierig sind
Im Gegensatz zu Alltagsfotos sind Thangka-Werke bewusst dicht gestaltet und stark symbolisch. Ein einziges Bild kann eine zentrale Gottheit, Dutzende kleinerer Figuren, gemusterte Ränder sowie spezifische Handgesten, Objekte, Farben und Haltungen enthalten, die jeweils religiöse Bedeutung tragen. Standardprogramme zur Bildbeschriftung kommen oft gut mit einfachen Szenen wie „ein Hund am Strand“ zurecht, haben hier aber Schwierigkeiten: Sie könnten den Haupt-Buddha benennen, dabei jedoch übersehen, ob er eine Schale oder ein Schwert hält, seine Haltung falsch interpretieren oder ihn mit einer ähnlich aussehenden anderen Gottheit verwechseln. Solche Fehler sind nicht trivial – sie können die Erzählung und die Lehre, die das Bild vermitteln soll, komplett umkehren und somit seinen Bildungs- und Kulturwert untergraben.
Ein neuer Plan für die Beschreibung sakraler Bilder
Geo‑TCAM geht diese Probleme mit einer Kombination aus drei Ideen an: mehrstufige visuelle Merkmale, Themawissen über Thangka-Kunst und geometriegeführte Aufmerksamkeit auf Schlüsselbereiche wie Gesichter. Zunächst verwendet es ein tiefes Netzwerk (ResNet50), das jedes Bild gleichzeitig auf mehreren Ebenen betrachtet: Mittlere Schichten erfassen Kanten, Texturen und einfache Formen, während tiefere Schichten die Gesamtkomposition zusammenfassen. Durch die Fusion dieser Ebenen kann das Modell sowohl feine Details wie Verzierungen als auch die grobe Anordnung von Hintergrund und Figuren erkennen und erhält damit ein reichhaltigeres visuelles Verständnis als frühere Systeme, die sich auf eine einzelne Schicht konzentrierten. 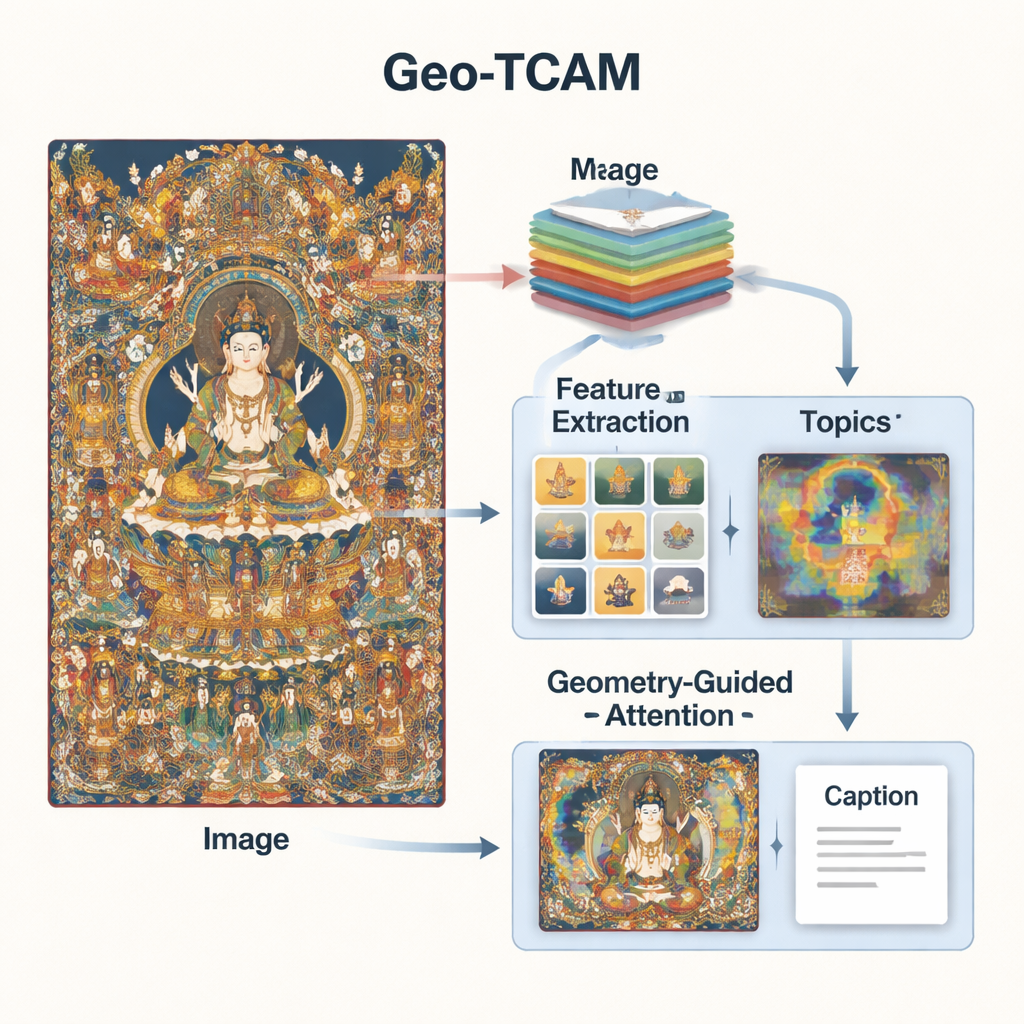
Dem Modell Thangka‑„Themen“ beibringen
Visuelle Informationen allein reichen nicht aus; das System braucht außerdem ein Gespür für die Sprache und Themen der Thangka‑Tradition. Zu diesem Zweck trainierten die Forschenden ein Themenmodell auf tausenden von fachkundig verfassten Thangka-Beschreibungen. Dieses Modell gruppiert Wörter in einige gängige Themen – zum Beispiel solche, die mit Buddhas, Bodhisattvas, Lotus-Sitzen, rituellen Gegenständen oder Schutzgottheiten zu tun haben. Für jedes neue Bild schätzt Geo‑TCAM, welche Themen am relevantesten sind, und mischt diese Information mit den visuellen Merkmalen. Ein Aufmerksamkeitsmechanismus hebt dann die Bildregionen hervor, die am besten zu den wahrscheinlichen Themen passen. Effektiv lenkt dieses Vorwissen darüber, welche Objekte und Symbole typischerweise zusammen auftreten, die KI hin zu sinnvolleren, kulturell informierten Beschreibungen.
Die KI dort „schauen“ lassen, wo es am meisten zählt
Die dritte Innovation ist ein geometriegeführtes modulares System für Gesichtsräumliche Aufmerksamkeit (GFSA). Thangka-Kompositionen platzieren das Gesicht der Hauptfigur meist in etwa vorhersehbaren Bereichen des Bildes. Geo‑TCAM verwendet einfache Kantenerkennungswerkzeuge, um diesen Bereich sowie die umliegenden Hände und die Körperhaltung einzugrenzen, und wendet dann einen dedizierten Aufmerksamkeitsmechanismus an, der den Einfluss dieser Pixel beim Generieren einer Beschriftung verstärkt. Diese Strategie „zuerst lokalisieren, dann führen“ hilft, frühe Fehlidentifikationen der zentralen Gottheit zu vermeiden, die sonst zu langen Ketten von textlichen Fehlern über Gesten, Attribute und Rang führen würden. Visuelle Heatmaps zeigen, dass das Modell mit GFSA konzentrierter auf das Gesicht der Hauptfigur und wichtige Objekte fokussiert, während es dennoch wichtige Hintergrundmotive im Blick behält. 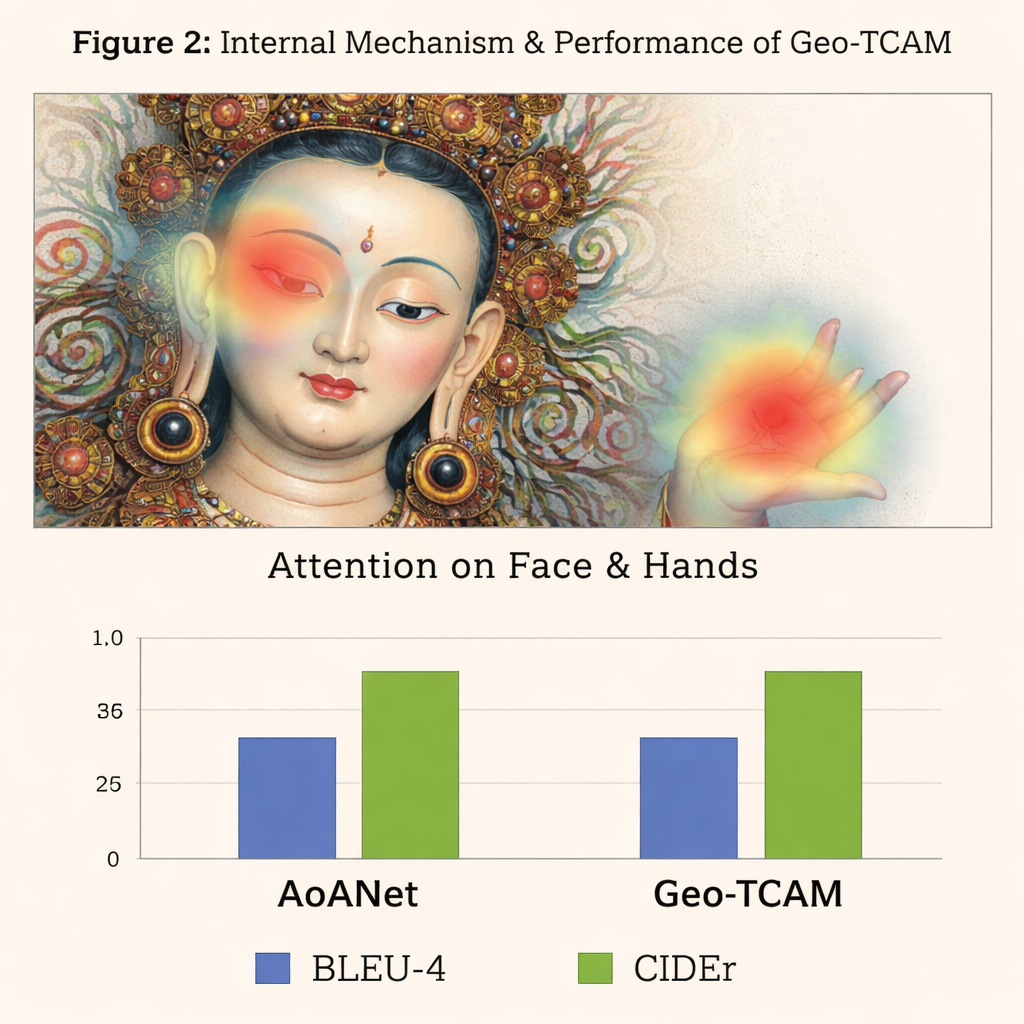
Wie gut funktioniert Geo‑TCAM?
Um ihren Ansatz zu prüfen, erstellten die Autorinnen und Autoren ein spezialisiertes D‑Thangka-Datenset mit fast 4.000 sorgfältig annotierten Bildern, jeweils mit detaillierten Expertenbeschreibungen. Auf diesem Datensatz übertraf Geo‑TCAM mehrere starke Beschriftungssysteme deutlich, darunter das populäre AoANet und große Vision‑Language-Modelle. Je nach Metrik verbesserten sich die Werte um bis zu etwa 120 % gegenüber der Basislinie, und menschliche Gutachter bevorzugten seine Bildunterschriften überwältigend in Bezug auf Genauigkeit, Sprachfluss und Detailreichtum. Wichtig ist, dass das gleiche Modell bei der Bewertung an einem Standard-Datensatz für Alltagsfotografie (dem COCO-Datensatz) konkurrenzfähig mit führenden Methoden blieb, was zeigt, dass sein Design leistungsfähig und zugleich allgemein einsetzbar ist.
Was das für das Kulturerbe und darüber hinaus bedeutet
Für Nicht‑Expertinnen und Nicht‑Experten lautet die Hauptaussage, dass Geo‑TCAM visuell komplexe Thangka-Malereien in klare, informative Erzählungen verwandeln kann, die zeigen, wer dargestellt ist, was getan wird und warum diese Details wichtig sind. Durch die Verbindung von gestaffelter visueller Analyse, gelernten Themen aus Fachtexten und spezieller Aufmerksamkeit für Gesichter und Gesten bringt das System seine Beschreibungen viel näher an die Art und Weise heran, wie menschliche Fachleute diese Kunstwerke lesen. Langfristig könnten solche Werkzeuge digitale Archive, Museumsführer und Bildungsplattformen unterstützen und damit esoterische religiöse Kunst besser zugänglich machen sowie Konservatorinnen, Forschende und Kuratorinnen beim Dokumentieren und Schützen fragiler Kulturschätze helfen.
Zitation: Zhong, P., Hu, W., Zhao, Y. et al. Geo-TCAM: a Thangka captioning method integrating topic modeling with geometry-guided spatial attention. npj Herit. Sci. 14, 87 (2026). https://doi.org/10.1038/s40494-026-02343-8
Schlüsselwörter: Thangka-Bildbeschriftung, KI für Kulturerbe, visuelle Aufmerksamkeit, Themenmodellierung, Kunstkonservierung