Clear Sky Science · de
M3SFormer: Mehrstufiger semantischer und stilintegrierter Transformer für die Bildinpainting von Wandmalereien
Verblasste Wandkunst wieder zum Leben erwecken
In Tempeln und Höhlen Chinas bröckeln antike Wandmalereien und Schriftrollen langsam — abblätternde Pigmente, fehlende Gesichter und ganze Szenen, die der Zeit zum Opfer gefallen sind. Restauratoren greifen zunehmend auf digitale Werkzeuge zurück, um diese Werke sicher zu untersuchen und sich vorzustellen, wie sie einst ausgesehen haben könnten. Dieses Papier stellt M3SFormer vor, ein neues System der künstlichen Intelligenz, das speziell dafür entwickelt wurde, beschädigte Wandmalereien und traditionelle Gemälde zu „inpainten“, also fehlende Bereiche zu füllen und dabei der ursprünglichen Struktur, den Farben und dem künstlerischen Stil treu zu bleiben.

Warum alte Wandmalereien so schwer zu reparieren sind
Die Restaurierung historischer Wandbilder ist weitaus anspruchsvoller als das Ausbessern eines Familienfotos. Wandmalereien enthalten oft dichte Muster, filigrane Pinselstriche und scharfe Farbgrenzen zwischen Figuren, Gewändern und Hintergrund. Frühere Deep-Learning-Methoden, insbesondere solche, die auf konvolutionalen neuronalen Netzen basieren, funktionieren gut bei kleinen Kratzern, versagen jedoch, wenn große Bereiche fehlen. Sie können wichtige Linien verwischen, Formen erfinden, die mit der umgebenden Darstellung kollidieren, oder dramatische Kontraste glattbügeln, die dem Werk seinen Charakter verleihen. Andere Ansätze komprimieren Bildinformationen zu stark und werfen damit genau die hochfrequenten Details weg — feine Risse, Haarlinien, Textilstrukturen — die für Konservatoren am wichtigsten sind.
Eine dreistufige digitale Restaurierungspipeline
M3SFormer begegnet diesen Herausforderungen mit einer grob-zu-fein, mehrstufigen Pipeline. Zunächst teilt ein Schritt der Globalen Struktur-Analyse das Bild in kleine Patches und nutzt einen Transformer — ein ursprünglich für Sprache entwickeltes Modell — um zu verstehen, wie weit entfernte Bildbereiche zueinander in Beziehung stehen. Indem es Langstreckenverbindungen modelliert, ohne die üblichen Informationsverluste durch starke Quantisierung, erstellt diese Stufe einen detaillierten, globalen Bauplan der Bildstruktur. Danach bringt eine Phase der Semantisch-stilistischen Konsistenz zwei Arten hochrangiger Hinweise ein: Das Bild wird in bedeutungsvolle Regionen (etwa Gesichter, Gewänder oder Hintergrund) segmentiert und ein vortrainiertes Netzwerk lernt die charakteristischen Texturen und Farben jeder Region. Schließlich behandelt eine Flow-geführte Verfeinerung-Stufe die Restaurierung als schrittweise Entwicklung und nutzt ein erlerntes „Geschwindigkeitsfeld“, um die anfängliche Schätzung in mehreren kleinen Schritten zu einem visuell kohärenten Endergebnis zu bewegen.
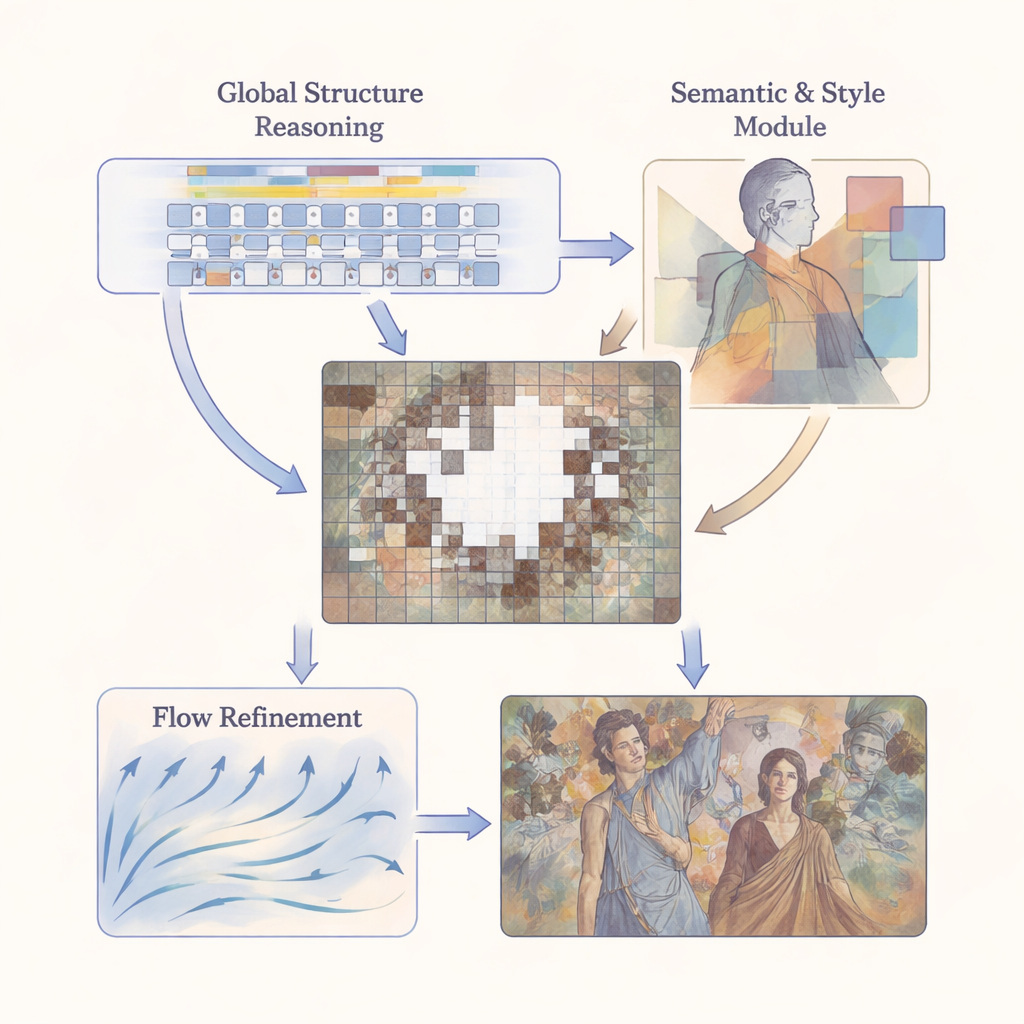
Struktur und Stil in Einklang halten
Eine zentrale Idee der Arbeit ist, dass Inhalt und Stil gemeinsam behandelt, aber nicht verwechselt werden dürfen. Die semantische Komponente des Modells, basierend auf einem leistungsfähigen Segmentierungssystem namens Mask2Former, sagt dem Netzwerk, wo sich verschiedene Elemente der Szene beginnen und enden. Darauf aufbauend misst die Stilkomponente, wie eng die wiederhergestellten Bereiche in jeder semantischen Zone dem Original entsprechen, indem sie auf mehreren Skalen Schichtvergleiche von Merkmalsmustern (mittels Gram-Matrizen) durchführt. So kann das System beispielsweise ein Gesicht anders behandeln als ein gemustertes Gewand oder einen wolkigen Himmel, statt eine einzige globale Stilregel anzuwenden, die lokale Unterschiede verwischen würde. In der Verfeinerungsphase wirken semantische Masken wie Leitplanken für das Flow-Feld und sorgen dafür, dass die eingefüllten Pixel sich so entwickeln, dass sowohl Struktur als auch Stil gewahrt bleiben.
Die Methode auf die Probe stellen
Um die Leistungsfähigkeit von M3SFormer in realistischen Szenarien zu prüfen, stellten die Autoren zwei große Datensätze zusammen: einen mit chinesischen Wandmalereien aus verschiedenen Regionen und einen weiteren mit traditionellen Landschaftsgemälden. Sie simulierten Schäden mit Masken, die echten Rissen und fehlenden Fragmenten nachempfunden sind, und verglichen ihre Methode mit sieben modernen Alternativen, darunter Transformers- und Diffusions-basierte Systeme. Über gängige Messgrößen für Bildqualität, strukturelle Ähnlichkeit und wahrnehmungsbasierten Realismus hinweg schnitt M3SFormer konstant am besten ab, insbesondere wenn der beschädigte Bereich groß und komplex war. Visuelle Vergleiche zeigen, dass es die Unschärfen, seltsamen Farbflächen und verrauschten Sprenkel vermeidet, die viele konkurrierende Methoden plagen, und dabei noch mit einer für die Praxis angemessenen Geschwindigkeit arbeitet.
Grenzen, Erkenntnisse und zukünftige Möglichkeiten
Trotz seiner Stärken ist M3SFormer keine magische Allheilung. Bei sehr großen Fehlstellen oder hochkomplexen Mustern kann es weiterhin Details halluzinieren, die mit der historischen Realität kollidieren — eine wichtige Warnung für Restauratoren, die stets die Grenze zwischen plausibler Rekonstruktion und Spekulation im Blick behalten müssen. Die Autoren schlagen vor, künftige Versionen sollten explizite Vorgaben einbeziehen, etwa Skizzen oder kurze Textbeschreibungen, um die Vorstellungskraft des Modells zu verankern. Selbst mit diesen Vorbehalten bietet der Ansatz ein mächtiges neues Werkzeug für Museen und Forscher: eine Möglichkeit, detaillierte, stiltreue digitale Rekonstruktionen zu erzeugen, „Was-wäre-wenn“-Restaurierungen nicht-invasiv zu erkunden und dazu beizutragen, dass fragile Kulturschätze noch lange studiert und geschätzt werden können, nachdem die Originalpigmente verblasst sind.
Zitation: Hu, Q., Ge, Q., Zhang, Y. et al. M3SFormer: multi-stage semantic and style-fused transformer for mural image inpainting. npj Herit. Sci. 14, 64 (2026). https://doi.org/10.1038/s40494-026-02325-w
Schlüsselwörter: digitale Restaurierung von Wandmalereien, Bildinpainting, kulturelles Erbe, Transformer-Modelle, Kunstkonservierung