Clear Sky Science · de
Korpus mit Wortartenangaben zu den Zweiundzwanzig (?) Geschichte(n) — Korpus der Zweiundzwanzig klassischen Historien (alt‑neu) mit Wortart‑Annotation
Warum alte Chroniken im Zeitalter der KI wichtig sind
Über mehr als zwei Jahrtausende hinweg hielten chinesische Historiker Kriege, Höfe, Hungersnöte und das Alltagsleben in der umfangreichen Reihe bekannt als die Zweiundzwanzig (Twenty-Four) Historien fest. Heute werden diese Klassiker nicht nur von Gelehrten, sondern auch von Computern neu entdeckt. Diese Studie beschreibt, wie Forschende diese alten Chroniken und ihre modernen chinesischen Übersetzungen in eine sorgfältig annotierte Sprachdatenbank überführten. Diese Ressource kann der künstlichen Intelligenz helfen, historische Texte genauer zu lesen, zu übersetzen und zu analysieren — und die ferne Vergangenheit der Öffentlichkeit viel zugänglicher zu machen.
Von verstaubten Bänden zu digitalem Text
Das Projekt beginnt mit einer grundlegenden, aber gewaltigen Aufgabe: Millionen gedruckter Zeichen in sauberen, korrekten digitalen Text zu überführen. Das Team nutzte zwei Quellen — eine maßgebliche moderne Edition der Zweiundzwanzig Historien und eine umfangreiche Online‑Sammlung — um ein optisches Zeichenerkennungssystem zu speisen. Anschließend entfernten sie sorgfältig fehlerhafte Passagen, korrigierten falsch erkannte Zeichen und beseitigten Störeinflüsse wie Seitenköpfe und -füße. Das Ergebnis war ein paralleles Satz von Dateien, eine in altchinesischer, die andere in moderner chinesischer Form, die den Originalbänden treu blieben und zugleich für die rechnergestützte Analyse bereit waren. 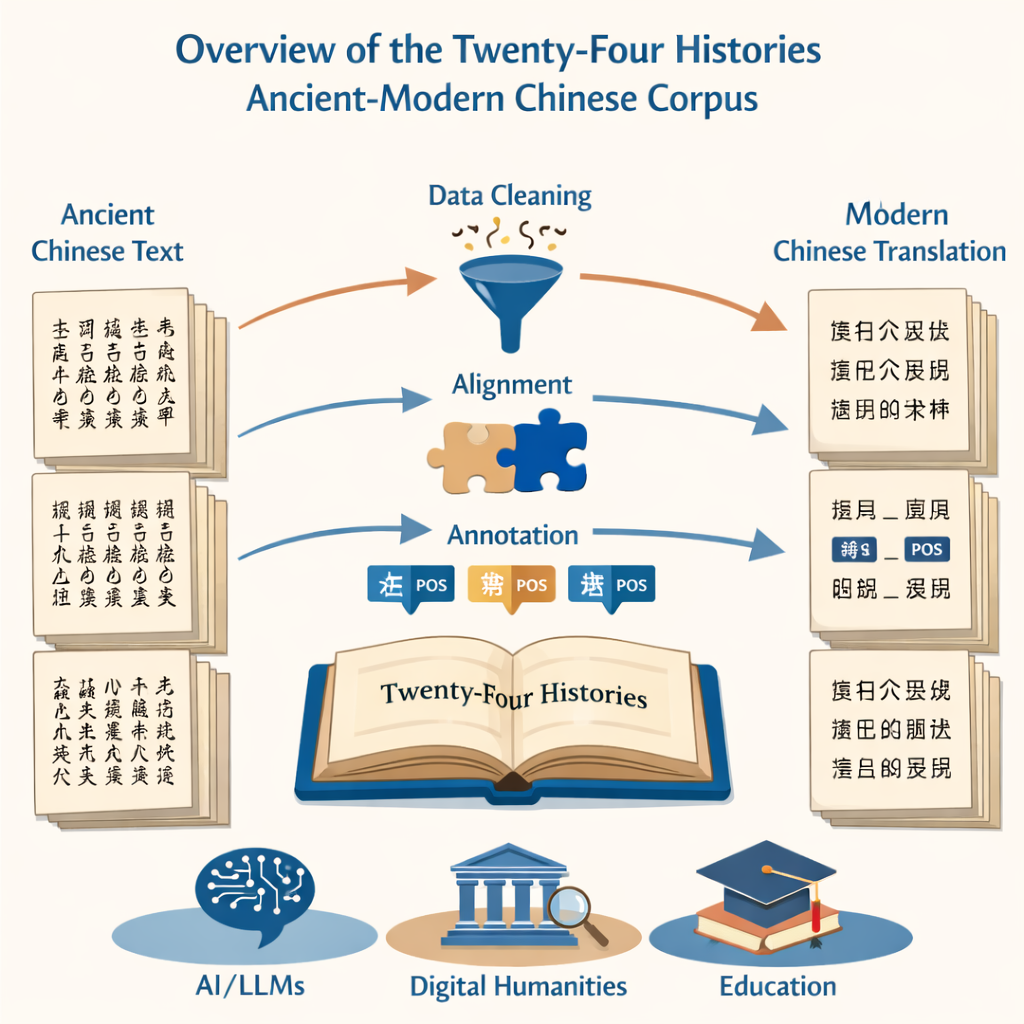
Alte Sätze mit modernen paaren
Da das Ziel war, Sprachwandel über die Zeit zu vergleichen, war es entscheidend, die alten und neuen Versionen Satz für Satz aufeinander abzustimmen. Die Forschenden verwendeten spezialisierte Alignment‑Software, um zunächst Absätze abzugleichen und diese dann in korrespondierende Sätze zu zerlegen. Automatisierte Werkzeuge leisteten die schwere Arbeit, doch menschliche Expertinnen und Experten mussten jedes vorgeschlagene Paar überprüfen, da die Grammatik des Altchinesischen sehr unterschiedlich zur modernen Sprache sein kann. Wo die Software stolperte — einen Gedanken an der falschen Stelle trennte oder ein Zeichen falsch las — überprüften Annotatorinnen und Annotatoren die originalen Scans und korrigierten den digitalen Text, sodass jeder alte Satz sauber mit seinem modernen Pendant übereinstimmte.
Computern Grammatik beibringen
Über die reine Transkription hinaus besteht der Kern des Projekts in grammatischen Kennzeichnungen. Jedes Wort in den alten und modernen Texten wurde mit einem Wortart‑Tag versehen, das angibt, ob es sich beispielsweise um ein Substantiv, ein Verb oder ein Zeitwort handelt. Da es keinen einheitlichen Standard für das Altchinesische gibt, orientierte sich das Team an modernen nationalen Richtlinien und passte diese dann an ältere Verwendungsweisen an. Sie entwickelten ein 22‑Tag‑Schema, das ein besonderes Label für spezifisch alte Verbverwendungen enthält, etwa Ausdrücke im Sinn von „zum Leben verhelfen“ oder „für das Land sterben“. Ein maßgeschneidertes neuronales Netzwerk — aufgebaut auf einem Sprachmodell für alte Texte und Schichten zur Sequenz‑Kennzeichnung — erzeugte erste Tags, die anschließend von einem großen Team gut ausgebildeter Doktorandinnen und Doktoranden überprüft und korrigiert wurden. Strenge Übereinstimmungstests zwischen Annotierenden zeigten sehr hohe Konsistenz und bestätigten, dass das final annotierte Korpus sowohl umfangreich als auch zuverlässig ist.
Was die neue Linse offenbart
Mit dem annotierten Korpus untersuchten die Autorinnen und Autoren einige der sichtbaren Muster. Im Altchinesischen dominieren einsilbige Schriftzeichenwörter, was einen bekannt kompakten Schreibstil widerspiegelt, während das moderne Chinesisch zwei‑silbige Wörter bevorzugt. Die häufigsten alten Einheiten sind kleine grammatische Partikeln wie „之“ und „以“, während Verben und gewöhnliche Substantive zusammen in beiden Zeiträumen etwa die Hälfte aller Wörter ausmachen. Die Daten zeigen außerdem, welche Wörter tendenziell zusammen auftreten — zum Beispiel Strukturen, die Beamte, Armeen oder diplomatische Missionen beschreiben. Durch den Vergleich der Tags in den Alt‑Moderne‑Paaren verfolgte das Team, wie sich Funktionen über die Zeit verschoben haben: Einige alte Präpositionen und Adverbien entsprechen heute vollen Verben, und manche Verben verfestigten sich zu festen Titeln oder Rechtstermen. Eine Fallstudie extrahierte alle Ortsnamen und kartierte ihre Häufungen in verschiedenen Dynastien, wobei sichtbar wurde, wie sich politische und wirtschaftliche Zentren vom Nordwesten in die untere Yangtze‑Region und darüber hinaus verlagerten. 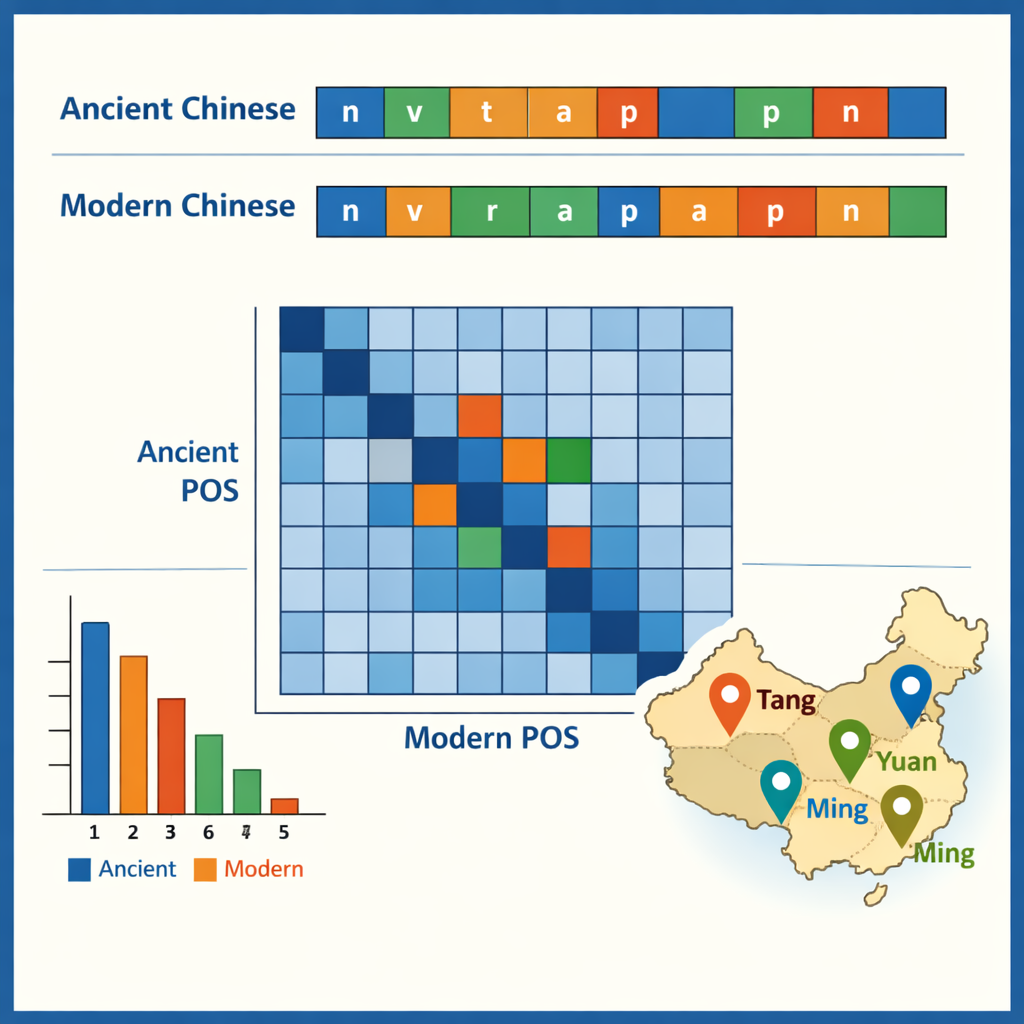
Die Vergangenheit in die digitale Zukunft überführen
Einfach gesagt verwandelt dieses Projekt eine gewaltige Wand klassischer Prosa in strukturierte Daten, die sowohl Menschen als auch Maschinen durchdringen können. Für Historikerinnen und Linguistinnen bietet es ein leistungsfähiges Werkzeug, um zu verfolgen, wie Wörter, Grammatik und sogar Staatsgrenzen sich über Jahrhunderte entwickelten. Für KI‑Entwickler liefert es hochwertiges Trainingsmaterial, um Sprachmodelle zu bauen, die klassisches Chinesisch tatsächlich bewältigen können, statt es als bloße Zeichenansammlung zu behandeln. Und für Studierende sowie allgemeine Leser senkt die Satz‑für‑Satz‑Gegenüberstellung von Alt- und Neutext die Hürde beim Lesen der Klassiker. Durch die sorgfältige Kennzeichnung und Ausrichtung der Zweiundzwanzig Historien haben die Autorinnen und Autoren eine Brücke von den handgeschriebenen Schriftrollen der Vergangenheit zu den intelligenten Systemen der Gegenwart und Zukunft geschaffen.
Zitation: Ye, W., Xu, Q., Zhao, X. et al. Construction of the twenty-four histories ancient-modern part-of-speech tagged corpus. npj Herit. Sci. 14, 97 (2026). https://doi.org/10.1038/s40494-026-02309-w
Schlüsselwörter: altchinesisches Korpus, Wortartannotation, digitale Geisteswissenschaften, parallele Texte, historischer Sprachwandel