Clear Sky Science · ar
المرآة السحرية ثلاثية الأبعاد: إعادة بناء الملابس من صورة واحدة عبر منظور سببي
تجريب الملابس بدون غرفة قياس
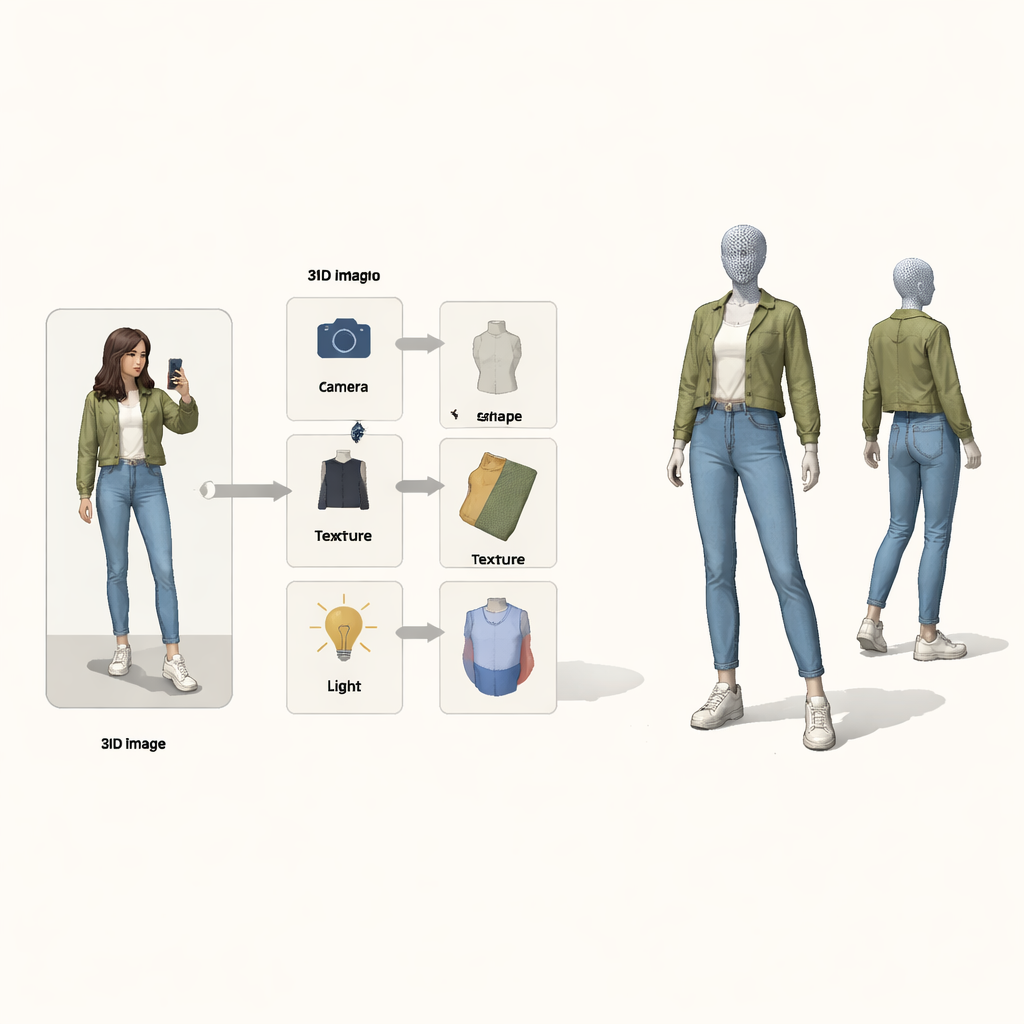
تخيل أن تلتقط صورة كاملة للجسم بهاتفك لترى نفسك فورًا في شكل ثلاثي الأبعاد، قادرًا على تدوير الصورة، تغيير زاوية المشاهدة، أو حتى تبديل الملابس مع صديق. تتناول هذه الورقة العلمية المشكلة التقنية الأساسية وراء تلك «المرآة السحرية ثلاثية الأبعاد»: تحويل صورة ثنائية الأبعاد عادية لشخص مرتدٍ ملابس إلى نموذج ثلاثي الأبعاد مفصّل لملابسه، دون الاعتماد على مسح ثلاثي الأبعاد مكلف أو صور ستوديو مضبوطة.
لماذا تحويل الصور ثنائية الأبعاد إلى ثلاثية الأبعاد صعب للغاية
تحويل صورة مسطحة إلى كائن ثلاثي الأبعاد يمثّل لغزًا كلاسيكيًا. تبدأ الأنظمة الحالية غالبًا من قالب جسدي رقمي ثابت وتقوم بتشكيله ليتلاءم مع الصورة. هذا ينجح إلى حد ما مع أجزاء الجسم الصلبة مثل الذراعين والساقين، لكنه يفشل مع الفساتين المتدفقة والمعاطف المتدلية والشعر أو الحقائب، التي لا تتبع شكلًا قياسيًا بسيطًا. عائق آخر هو البيانات: هناك ملايين صور الموضة على الويب، لكن لا توجد مجموعات ضخمة من الملابس ثلاثية الأبعاد المقاسة بدقّة للتدريب عليها. وأخيرًا، تخفي الصورة الواحدة معلومات مهمة. فمعطف صغير قريب من الكاميرا قد يبدو مطابقًا لمعطف أكبر أبعد منها، كما أن الإضاءة ونقوش القماش قد تضلّل خوارزمية التعلم. هذه الالتباسات تجعل من الصعب على الشبكة العصبية «تخمين» البنية ثلاثية الأبعاد الصحيحة.
تعليم الذكاء الاصطناعي فصل السبب عن التأثير
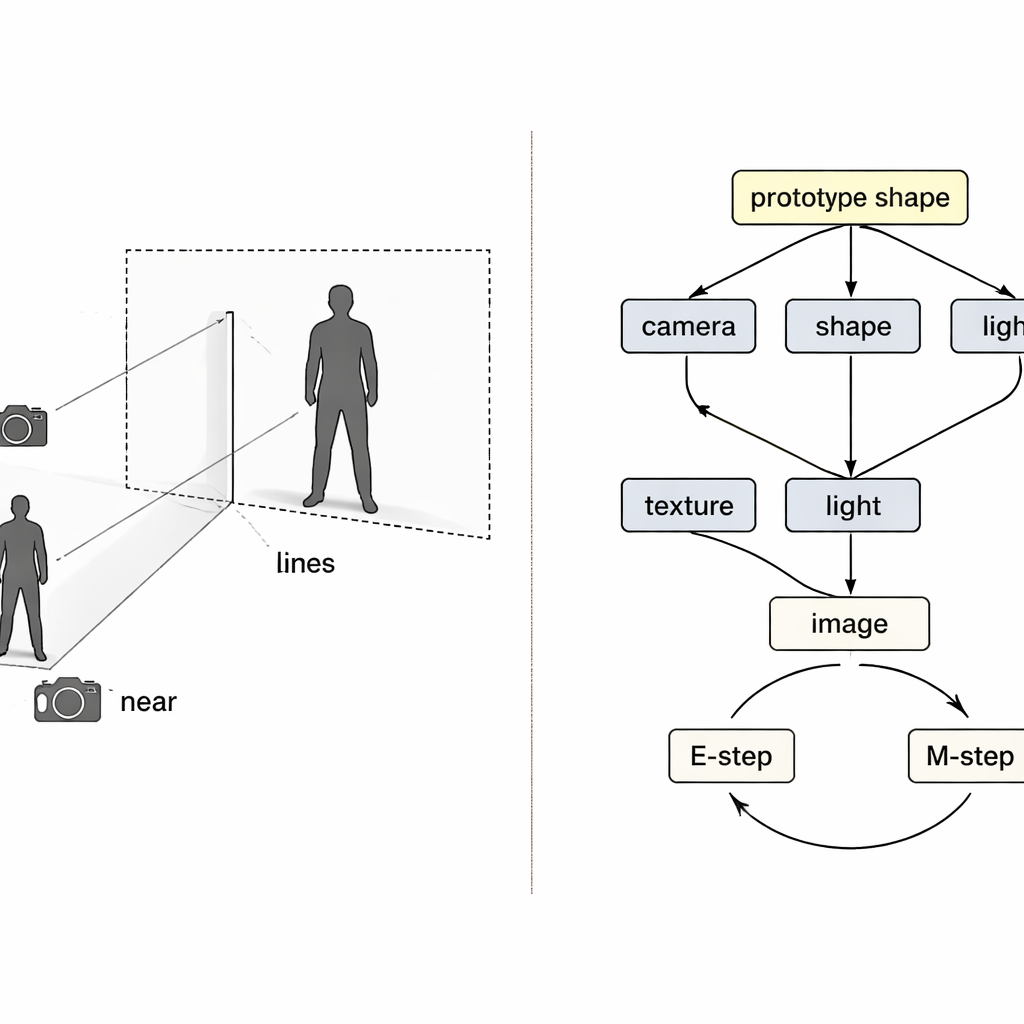
بدلًا من التعامل مع المشكلة كتحويل صندوق أسود من البكسلات إلى ثلاثي الأبعاد، يستعير المؤلفون أفكارًا من التفكير السببي—رياضيات السبب والنتيجة. فهم يرون الصورة النهائية كنتيجة لأربع أسباب خفيّة: وضعية الكاميرا، وشكل الملابس، وكيفية تلوينها (ألوانها ونقوشها)، وكيفية الإضاءة. يرسم «خريطة سببية بنيوية» خاصة كيفية تلازم هذه العوامل لإنتاج الصورة المرصودة. استرشادًا بهذه الخريطة، يستخدم النظام أربعة مشفرات عصبية منفصلة، كل منها مسؤول عن عامل واحد. ومع عارض ثلاثي الأبعاد مستوحى من الفيزياء، تشكّل هذه المكونات حلقة: تدخل الصورة وقناع المقدمة، يخرج شبكة ثلاثية الأبعاد ملونة، ثم تُسقط مرة أخرى إلى صورة يمكن مقارنتها بالأصلية.
حلقة تعلم تصلح شيئًا واحدًا في كل مرة
حتى مع وجود مشفرات منفصلة، قد يخطئ التدريب. إذا كانت إعادة البناء غير مثالية، فمن غير الواضح أي مشفِّر يتحمّل الخطأ، وتميل طرق التعلم العادية إلى ضبطها جميعًا معًا. يعالج المؤلفون هذا كمشكلة «التصادم» الكلاسيكية في السببية، حيث قد تعوّض الأسباب المختلفة عن بعضها بشكل خاطئ. حلّهم هو نسج حلقتين من نوع التوقع–التقصي داخل التدريب. في الحلقة الأولى، تُجمَّد ثلاثة مشفرات مؤقتًا بينما يُحدَّث الرابع بمفرده، بحيث تُنسب الأخطاء بوضوح ويتعلم ذلك المكوّن دورًا أنقى. في الحلقة الثانية، يُحدَّث «شكل نموذجي» ثلاثي الأبعاد مشترك—يبدأ ككرة بسيطة—ببطء ليصبح متوسط شكل الإنسان أو الطائر في البيانات. تتعلّم الأمثلة الفردية انحرافات صغيرة فقط عن هذا النموذج، بينما يتولّى مُكوّن الكاميرا المسؤولية الكاملة عن مدى ظهور الكائن كبيرًا أو قريبًا، مهاجمًا مباشرة لبس الحجم مقابل المسافة.
من صور الأزياء إلى الطيور، وما بعدها
لاختبار منهجهم، درّب الباحثون النموذج على مجموعتي أزياء كبيرتين تحتويان على صور شارع عادية وعلى مجموعة معيارية من صور الطيور. والأهم أنهم استخدموا أقنعة مقدمة ثنائية الأبعاد فقط، دون شبكات ثلاثية الأبعاد حقيقية كمرجع. على الملابس البشرية، تفوق نظامهم على طرق القوالب الجسدية الشائعة في مطابقة المحيط الحقيقي للقطع وتعامل بشكل أفضل مع العناصر غير الصلبة مثل الشعر والحقائب. على الطيور، بلغ أو تجاوز جودة طرق إعادة البناء ثلاثي الأبعاد من صورة واحدة الرائدة بينما أنتج زوايا رؤية جديدة أكثر واقعية. النماذج ثلاثية الأبعاد مرنة بما يكفي لدعم تطبيقات مرحة، مثل تبادل أنسجة الملابس بين الأشخاص أو توليد بيانات تدريب اصطناعية لتعزيز أنظمة إعادة تعرف الأشخاص المستخدمة في أبحاث المراقبة.
ماذا يعني هذا لعوالمنا الرقمية اليومية
بالنسبة لغير المتخصصين، الرسالة الأساسية هي أن الصُّوَر المتقنة للواجهات ثلاثية الأبعاد وأدوات التجريب الافتراضي لم تعد تتطلب ماسحات ثلاثية الأبعاد مكلفة أو قوالب جامدة. من خلال نمذجة السبب والنتيجة صراحة—فصل الكاميرا والشكل والملمس والضوء وربطها بنموذج أولي مشترك—يُظهر المؤلفون كيف يمكن للنظام أن «يشرح» صورة واحدة كمشهد ثلاثي الأبعاد. ومع أن الطريقة لا تزال تواجه صعوبات مع زوايا لم ترها من قبل، مثل ظهر شخص التُقِطَت له صورة من الأمام فقط، فإنها تمثل خطوة مهمة نحو مرايا ثلاثية الأبعاد عملية تعمل على الصور الفوضوية الملتقطة في العالم الحقيقي.
الاستشهاد: Zheng, Z., Zhu, J., Ji, W. et al. 3D Magic Mirror: clothing reconstruction from a single image via a causal perspective. npj Artif. Intell. 2, 29 (2026). https://doi.org/10.1038/s44387-026-00082-6
الكلمات المفتاحية: التجريب الافتراضي للملابس, إعادة البناء ثلاثي الأبعاد, التعلم السببي, رؤية الحاسوب, الذكاء الاصطناعي في الموضة