Clear Sky Science · ar
دور نماذج اللغة الكبيرة في الرعاية الطارئة: دراسة تقييم شاملة
لماذا هذا مهم لأي شخص قد يزور غرفة الطوارئ
غرف الطوارئ أصبحت أكثر ازدحامًا من أي وقت مضى، مع فترات انتظار أطول وطاقم أقل للاعتناء بعدد متزايد من المرضى الحرجين. تطرح هذه الدراسة سؤالًا يمس تقريبًا الجميع: هل يمكن لأنظمة الذكاء الاصطناعي الحديثة، المعروفة بنماذج اللغة الكبيرة، أن تساعد الأطباء والممرضات بأمان ليعملوا أسرع وأكثر ذكاءً في قسم الطوارئ؟ من خلال إخضاع عدة نظم ذكاء اصطناعي رائدة لسلسلة من الاختبارات الطبية وحالات محاكاة للطوارئ، يستكشف الباحثون مدى قرب هذه الأدوات من أن تصبح «مساعدين مشاركين» موثوقين في الرعاية العاجلة.
غرف الطوارئ تحت ضغط شديد
تبدأ الورقة بتوضيح أزمة متصاعدة في رعاية الطوارئ، لا سيما في الولايات المتحدة. السكان المتقدمون في العمر والازدياد في الأمراض المزمنة يدفعان أعداد زيارات غرفة الطوارئ إلى مستويات قياسية، حيث تجاوزت نحو 155 مليون زيارة في عام 2022 وحده. في الوقت نفسه، تواجه المستشفيات نقصًا حادًا في الممرضين والأطباء، وانخفض عدد الأسرّة لكل شخص على مدى العقود الأخيرة. يُصعّب نظام صحي مجزأ تنسيق الرعاية، مما يزيد خطر التأخير والأخطاء. في ظل هذا السياق، يجادل المؤلفون بأن هناك حاجة ملحة لأدوات جديدة لمساعدة الأطباء في فرز المرضى، واتخاذ قرارات سريعة، وتوثيق الرعاية دون زيادة العبء عليهم.
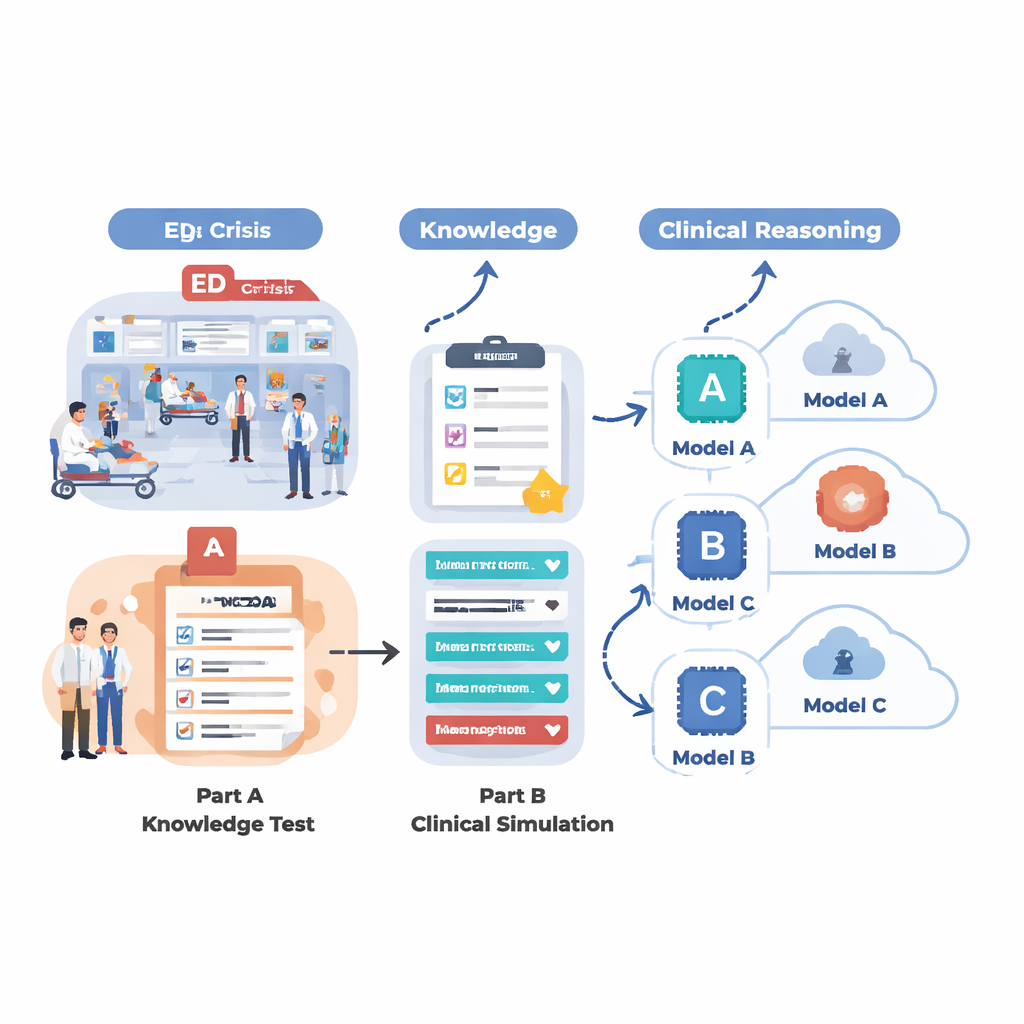
كيف اختبر الباحثون الذكاء الاصطناعي الطبي
للتحقق مما تستطيع أنظمة الذكاء الاصطناعي الحالية فعلاً القيام به في بيئة شبيهة بالطوارئ، صمم الفريق تقييمًا من جزأين. أولًا، اختبروا 18 نموذج لغة مختلفًا على مجموعة كبيرة من أسئلة الاختيار من متعدد مأخوذة من MedMCQA، وهو مجموعة بيانات على نمط الامتحانات الطبية تغطي 12 شكوى طبية شائعة في الطوارئ مثل ألم الصدر، وضيق التنفس، والصداع، وألم البطن. قاس هذا المرحلة المعرفة الطبية الأساسية: هل يستطيع الذكاء الاصطناعي اختيار الإجابة الصحيحة من بين أربع خيارات عبر آلاف الأسئلة؟ ثانيًا، اختاروا أقوى خمسة نماذج من تلك الجولة وطلبوا منها التعامل مع 12 حالة طوارئ واقعية خطوة بخطوة، كما يفعل الطبيب. في كل حالة، كان على الذكاء الاصطناعي تلخيص حالة المريض، وتعيين درجة استعجال للفرز، واقتراح أسئلة متابعة رئيسية، وتقديم خطوات إدارة مقترحة، وإدراج التشخيصات المحتملة بينما تُكشف معلومات جديدة تدريجيًا (علامات حيوية، والتاريخ المرضي، ونتائج الفحص، ونتائج المختبر والتصوير).
أي النماذج كانت تعرف الحقائق — وأيها استطاعت الاستدلال
في الاستدعاء الحقائقي البحت، قدمت عدة نماذج أداءً مثيرًا للإعجاب. سجل نظام متخصص يدعى LLaMA 4 Maverick دقة إجمالية تقارب 91 في المئة في أسئلة الطب، تلاه عن كثب LLaMA 3.1 وGPT-4.5 وGPT-5 وClaude 4. كانت هذه النماذج المتقدمة قوية باستمرار عبر شكاوى رئيسية مختلفة، ما يوحي بأن نماذج الطليعة قد تقترب من حد في المعرفة الطبية بنمط الكتاب المدرسي. تخلّفت الأنظمة المتوسطة المستوى بشكل واضح، حيث سجل بعضُها نحو 60 في المئة فقط وواجه صعوبات في مجالات رئيسية مثل رعاية الجروح ومشاكل التنفس. ومع ذلك، عندما تحول الاختبار من الإجابة عن أسئلة معزولة إلى الاستدلال خلال قصص مرضى غنية ومتطوّرة، ازدادت الفروق حدة. في هذه المحاكاة السريرية، تميّز GPT-5 بوضوح: فقدّم أكثر الملخصات دقة واكتمالًا، وطرح أكثر أسئلة المتابعة فائدة، أوصى بخطوات تالية معقولة وآمنة، وقدم أكثر قوائم الاحتمالات التشخيصية شمولًا وتنظيمًا.
نقاط القوة والضعف ومخاوف السلامة
قيّم الأطباء بعناية مخرجات كل ذكاء اصطناعي من حيث الدقة والملاءمة والسلامة. لم يحقق GPT-5 أعلى الدرجات فحسب، بل كان أيضًا النموذج الوحيد الذي ظل أداؤه مستقرًا أو تحسّن مع تعقّد الحالات، مع الحفاظ على الهلوسات والأخطاء الجسيمة أقل من نحو 2 في المئة. أظهرت نماذج أخرى أنماطًا مميزة من الضعف. بعضُها كان يميل إلى تفويت التشخيصات الثانوية أو إعطاء مسائل طفيفة أولوية على أخطار حقيقية. أصبحت نماذج أخرى متحفظة أو غامضة بشكل مفرط، أو تركزت بسرعة على تشخيص واحد. عمومًا، قللت معظم الأنظمة من تقدير شدة المرضى عند تعيين مستويات الفرز، وهو انحياز تحفظي قد يؤخر الرعاية العاجلة إذا لم يُصحّح. تبرز النتائج نقطة جوهرية: معرفة الحقائق الطبية ليست هي نفسها القدرة على نسج تلك الحقائق بشكل موثوق إلى قرارات آمنة خطوة بخطوة عندما تكون المعلومات ناقصة أو فوضوية ومتغيرة.

ما الذي قد يعنيه هذا لزيارات الطوارئ في المستقبل
خاتمة المؤلفين أن عدة أنظمة ذكاء اصطناعي حديثة أضحت تنافس بعضها البعض في المعرفة الطبية، وأن GPT-5 على وجه الخصوص يظهر مستوى جديدًا من قدرة الاستدلال قد يجعله مفيدًا كأداة دعم قرار في أقسام الطوارئ. يؤكدون أن هذه الأنظمة غير جاهزة لاستبدال الممارسين أو العمل بمفردها. بدلًا من ذلك، يكون الدور الأقرب للتطبيق قصير الأجل كمساعد خاضع للإشراف — يساعد ممرضات الفرز في تقدير الاستعجال، ويصوغ ملخصات المرضى، ويقترح أسئلة أو فحوصات، ويتحقق مما إذا كانت التشخيصات الخطيرة قد أُخذت بعين الاعتبار. كما تؤكد الدراسة الحاجة إلى مزيد من البحث في بيئات سريرية مباشرة، مع ضوابط سلامة قوية وقواعد واضحة للاستخدام. بالنسبة للمرضى، الرسالة هي تفاؤل حذر: الذكاء الاصطناعي يتحسن في التفكير عبر المشاكل الطبية، لكن استخدامه الآمن في الطوارئ سيعتمد على تصميم دقيق، وإشراف واضح، وتركيز مستمر على دعم — وليس استبدال — الحكم البشري للأطباء والممرضات.
الاستشهاد: Naderi, B., Liu, L., Ghandehari, A. et al. The role of large language models in emergency care: a comprehensive benchmarking study. npj Artif. Intell. 2, 24 (2026). https://doi.org/10.1038/s44387-026-00078-2
الكلمات المفتاحية: الطب الطارئ, نماذج اللغة الكبيرة, دعم القرار الإكلينيكي, الفرز (الترياج), تقييم أداء الذكاء الاصطناعي الطبي