Clear Sky Science · ar
تصحيح أخطاء ضرب-جمع في المعالجة داخل الذاكرة باستخدام رموز LDPC
لماذا يهم تصحيح أخطاء الحساب داخل الذاكرة
تستخرج شرائح الذكاء الاصطناعي الحديثة مزيداً من السرعة والكفاءة من العتاد عن طريق إجراء الحسابات مباشرة داخل الذاكرة، بدلاً من نقل البيانات ذهاباً وإياباً باستمرار إلى معالجات منفصلة. هذه المقاربة «المعالجة داخل الذاكرة» توفر الطاقة لكنها تطرح مشكلة خطيرة: قد تقلب عيوب كهربائية صغيرة بتات مخزنة أو تشوّه إشارات تمثيلية، مما يضعف بهدوء دقة مهام مثل تمييز الصور. تصف الورقة طريقة جديدة لاكتشاف هذه الأخطاء وتصحيحها تلقائياً أثناء التشغيل، مما يساعد عتاد الذكاء الاصطناعي المستقبلي على البقاء سريعاً وموثوقاً في الوقت نفسه.
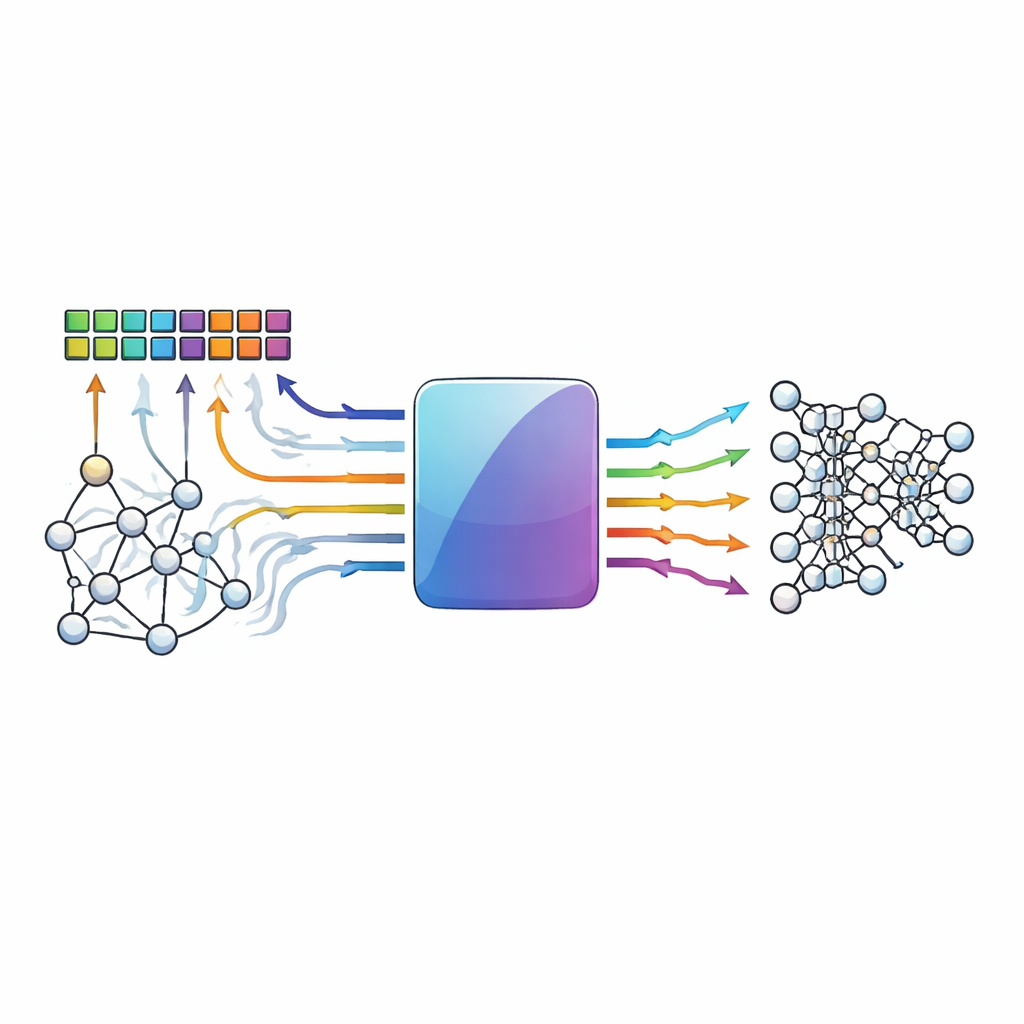
الحوسبة حيث توجد البيانات
تتباطأ الحواسيب التقليدية بسبب الحاجة إلى نقل البيانات بين الذاكرة والمعالج. تتجنب تصاميم المعالجة داخل الذاكرة عنق الزجاجة هذا عن طريق إجراء عمليات الضرب والجمع—العمود الفقري للشبكات العصبية—داخل مصفوفات كثيفة من خلايا الذاكرة. الأجهزة الناشئة مثل الذاكرة المقاومة وعناصر الميمريستيف الأخرى جذابة بشكل خاص لأنها قادرة على تخزين قيم متعددة وأداء حسابات بأسلوب تمثيلي بكفاءة عالية. ومع ذلك، فإن الطبيعة التمثيلية وتباين الأجهزة التي تمنحها قوتها تجعلها أيضاً صاخبة: التقلبات الحرارية، وعدم تطابق الأجهزة، وانخفاضات الفولتية يمكن أن تدفع القيم المخزنة أو النتائج المحسوبة بعيداً عما يجب أن تكون عليه.
عندما تتراكم الخلل الصغيرة
في هذه المصفوفات داخل الذاكرة، تُنشط العديد من الصفوف معاً وتُجمع مساهماتها على طول أسلاك مشتركة. كلما شاركت صفوف أكثر، جمعت عيوبها الفردية فتشكّل أنماطاً من الأخطاء المتكررة والمعقدة. بدلاً من بتٍ واحد خاطئ، غالباً ما يرى المصممون أخطاء متعددة متجمعة في نفس عمود المصفوفة أو ممتدة عبر أعمدة عدة بطريقة تُحيّل تقنيات تصحيح الأخطاء التقليدية إلى غير مجدية. تفترض الشيفرات القياسية عادة أنماط أخطاء بسيطة وطول كلمات قصير؛ قد تفوتها العيوب متعددة البتات أو تفتقر إلى مدخلات في جداول البحث لحالات نادرة لكنها مدمرة. نتيجة لذلك، قد تنهار دقة النماذج العميقة للشبكات العصبية بشدة بمجرد أن يصبح العتاد الأساسي غير موثوق حتى إلى حد متواضع.
شبكة أمان رقمية جديدة
يقدّم المؤلفون شيفرة منخفضة الكثافة وغير ثنائية (NB-LDPC) مصممة خصيصاً لعتاد المعالجة داخل الذاكرة. بدلاً من العمل فقط مع أصفار وواحدات، تعمل خطتهم على مجموعات صغيرة من البتات تُعامل كرموز داخل بنية رياضية تسمى حقل منتهي مبني على عدد أولي (هنا الثلاثة). يتيح ذلك للشيفرة نفسها حماية كل من التخزين الثنائي العادي والتمثيلات متعددة المستويات أو التفاضلية المستخدمة شائعاً في المعجلات التمثيلية. يضيف النظام عدداً متواضعاً من الرموز الإضافية—رموز تحقق—إلى كل كتلة من البيانات. أثناء قراءات الذاكرة العادية وعمليات الضرب-الجمع داخل الذاكرة، يحسب العتاد النتائج للبيانات ورموز التحقق معاً، بحيث يُنسج اكتشاف الأخطاء بشكل طبيعي في عملية الحساب.
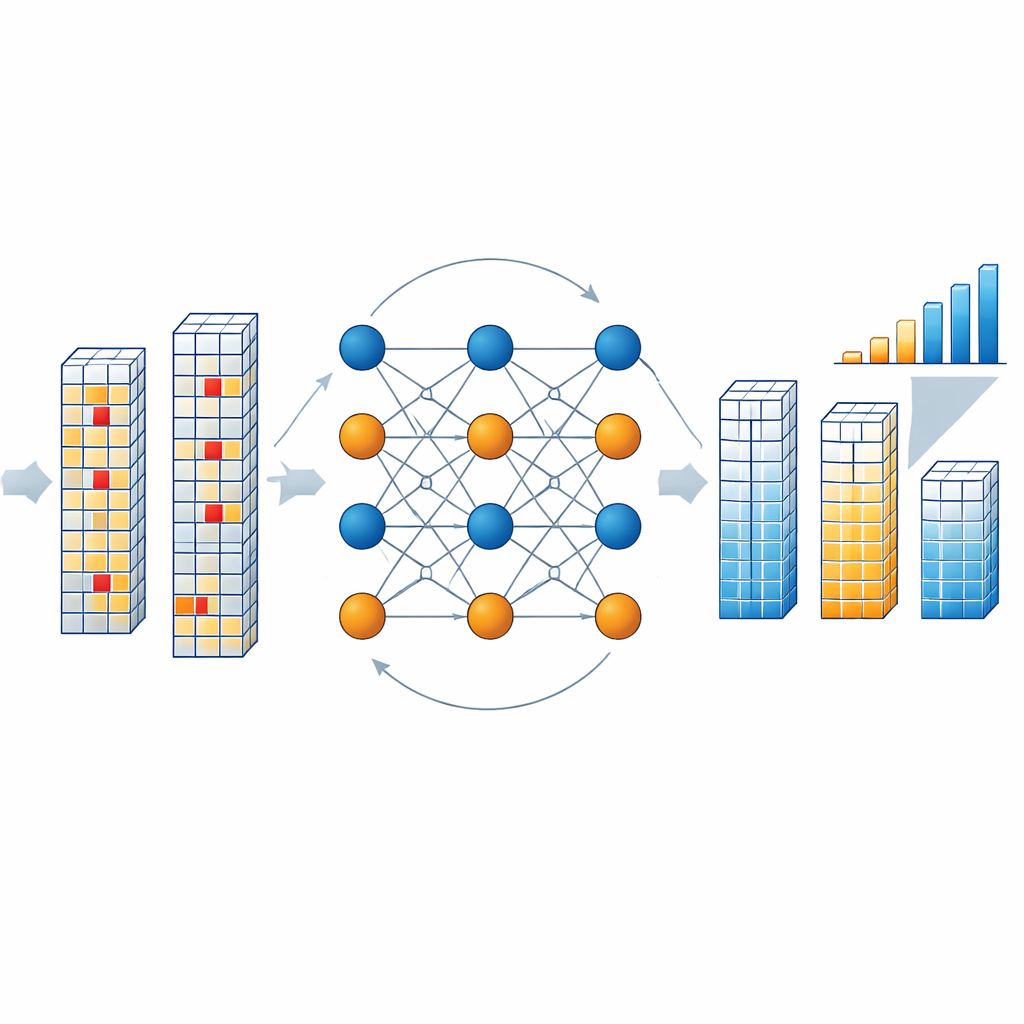
كيف يعمل محرك التصحيح داخل الشريحة
عندما تقرأ الشريحة كتلة من النتائج، يفحص مفكك ترميز مخصص ما إذا كانت البيانات ورموز التحقق المجمعة تفي بعلاقات التماثل (البارتي) المعرفة بواسطة الشيفرة. إذا كانت كذلك، تُفترض الكتلة خالية من الأخطاء. إذا لم تكن كذلك، يطلق المفكك عملية تكرارية تتبادل فيها «عُقد متغيرة» مجردة تمثّل كل رمز و«عُقد تحقق» تمثّل شروط التماثل رسائل احتمالية. تقدر هذه الرسائل مدى احتمال أن يأخذ كل رمز كل قيمة مسموح بها، بناءً على المخرجات المرصودة ومعدل تقلب البت المتوقع في الذاكرة. يبسط المؤلفون هذا التفكير الثقيل رياضياً باستخدام تقريب مسافة مانهاتن، مما يقلص بشكل كبير تكلفة العتاد مع الحفاظ على أداء عالٍ. بعد عدة جولات—عادة ثلاث—يتقارب المفكك على النسخة المصححة الأكثر احتمالاً من متجه النتائج، دون الحاجة لإعادة قراءة الذاكرة أو إيقاف مجرى الحساب.
دليل سيليكون وتأثيره على دقة الذكاء الاصطناعي
لاختبار الفكرة عملياً، بنى الفريق شريحة نموذجية بتقنية 40 نانومتر تجمع بين مصفوفة ذاكرة مقاومية، ومحولات خفيفة تمثيلية-إلى-رقمية، والمفكك NB-LDPC الجديد. بتكوين يحمي 256 رمز معلومات باستخدام 32 رمز تحقق، يحقق المفكك معدل شيفرة مرتفعاً (حوالي 0.8)، وكفاءة طاقة مقاسة تصل إلى نحو 88 تيرابت من البيانات المصححة لكل ثانية لكل واط، وبزيادة مساحة متواضعة يمكن تقليلها أكثر بمشاركة مفكك واحد بين عدة وحدات ذاكرة. تُظهر المحاكاة عبر أحجام شيفرة متعددة أنه عند حماية 1024 رمز بيانات باستخدام 128 رمز تحقق، يمكن للمخطط تحسين معدل خطأ البت بحوالي 60 ضعفاً تقريباً. عند تطبيقه على نموذج تصنيف الصور ResNet-34 يعمل على عتاد المعالجة داخل الذاكرة، يستعيد التصحيح أكثر من 20 نقطة مئوية من الدقة المفقودة في ظروف أخطاء صعبة.
ماذا يعني هذا لشرائح الذكاء الاصطناعي المستقبلية
بعبارات بسيطة، يوفر العمل لعتاد المعالجة داخل الذاكرة «مدقق إملائي» قوي لحساباته، يفهم مجموعات رموز أغنى وأنماط أخطاء معقدة من دون تبطيء تدفق البيانات. من خلال توحيد الحماية لكل من البيانات المخزنة والحسابات الجارية، وبإظهار تنفيذ سيليكوني فعال، تُبيّن الدراسة أن المعجلات ذات الكثافة العالية والطاقة المنخفضة لا تضطر للتضحية بالموثوقية. قد تصبح مثل هذه الطريقة المتخصصة في تصحيح الأخطاء مكوّناً أساسياً لجعل المعجلات النيورومورفية ومعجلات الذكاء الاصطناعي المستقبلية موفرة للطاقة وموثوقة بما يكفي للتطبيقات الواقعية، من الأجهزة المحمولة إلى مراكز البيانات واسعة النطاق.
الاستشهاد: Shi, D., Fu, Y., Zhu, Y. et al. Correcting processing-in-memory multiply-accumulate arithmetic errors with LDPC. npj Unconv. Comput. 3, 14 (2026). https://doi.org/10.1038/s44335-026-00061-9
الكلمات المفتاحية: المعالجة داخل الذاكرة, تصحيح الأخطاء, رموز LDPC, ذاكرة مقاومية, عتاد الشبكات العصبية