Clear Sky Science · ar
ADMM العشوائي غير الدقيق مع تهيئة مسبقة للنماذج العميقة
تدريب أذكى لذكاء اصطناعي أذكى
أنظمة الذكاء الاصطناعي الحديثة، من الروبوتات الحوارية إلى مولدات الصور، تعمل بواسطة شبكات عصبية هائلة يصعب تدريبها وتكلفته مرتفعة عادةً. ومع توزيع البيانات عبر أجهزة وخوادم متعددة، غالبًا ما تتباطأ طرق التدريب القياسية الحالية أو تصبح غير مستقرة أو تفشل ببساطة في التعامل مع فوضى بيانات العالم الحقيقي. يقدم هذا المقال عائلة جديدة من خوارزميات التدريب، تتمحور حول طريقة تسمى PISA، التي تعد بتعلم أسرع وأكثر موثوقية لمجموعة واسعة من النماذج العميقة مع افتراضات رياضية أقل صرامة حول البيانات.
لماذا تتعثر طرق التدريب الحالية
تُدرّب معظم نماذج التعلم العميق بواسطة متغيرات تقنية النزول العشوائي في التدرج، وهي طريقة تحرك معلمات النموذج تدريجيًا في اتجاه تقليل الخطأ. على مر السنين، حاولت تحسينات مثل Adam وRMSProp وغيرها جعل هذه الحركات أكثر ذكاءً عن طريق تعديل أحجام الخطوات أو إضافة زخْم. ومع ذلك، تفترض هذه الطرق عادةً أن بيانات التدريب مخلوطة بشكل جيد ومتجانسة إحصائيًا عبر الآلات، وأن بعض الكميات الرياضية محدودة. في التطبيق العملي، وبخاصة في إعدادات مثل التعلم الفدرالي حيث تحتفظ الهواتف أو أجهزة الطرف بنماذج بيانات مختلفة جدًا، غالبًا ما تُنتهك هذه الافتراضات، مما يؤدي إلى تباطؤ التقارب أو ضعف الأداء.
طريقة جديدة لتنسيق العديد من المتعلمين
يبني المؤلفون على إطار تحسين مختلف يعرف بطريقة الاتجاه المتبادل لمضاعفات المقسمات (ADMM)، وهي جيدة في تقسيم مشكلة كبيرة إلى عدة مشاكل أصغر يمكن حلها بالتوازي. المساهمة الرئيسية لهم، PISA (ADMM العشوائي غير الدقيق مع تهيئة مسبقة)، تحافظ على نقاط قوة ADMM بينما تتجنب مساوئها المعتادة — مثل الحاجة إلى حساب التدرجات الكاملة على كل البيانات أو إجراء عمليات انعكاس مصفوفية مكلفة. بدلاً من ذلك، تسمح PISA لكل عميل أو عقدة عامل بتحديث نسخته من النموذج باستخدام دفعة صغيرة فقط من البيانات، ثم تنسق هذه التحديثات عبر متغير مركزي. تقوم مصفوفات "التهيئة المسبقة" المصممة بعناية بإعادة تشكيل اتجاهات التحديث بحيث يتقدم التعلم بشكل أكثر سلاسة وكفاءة. 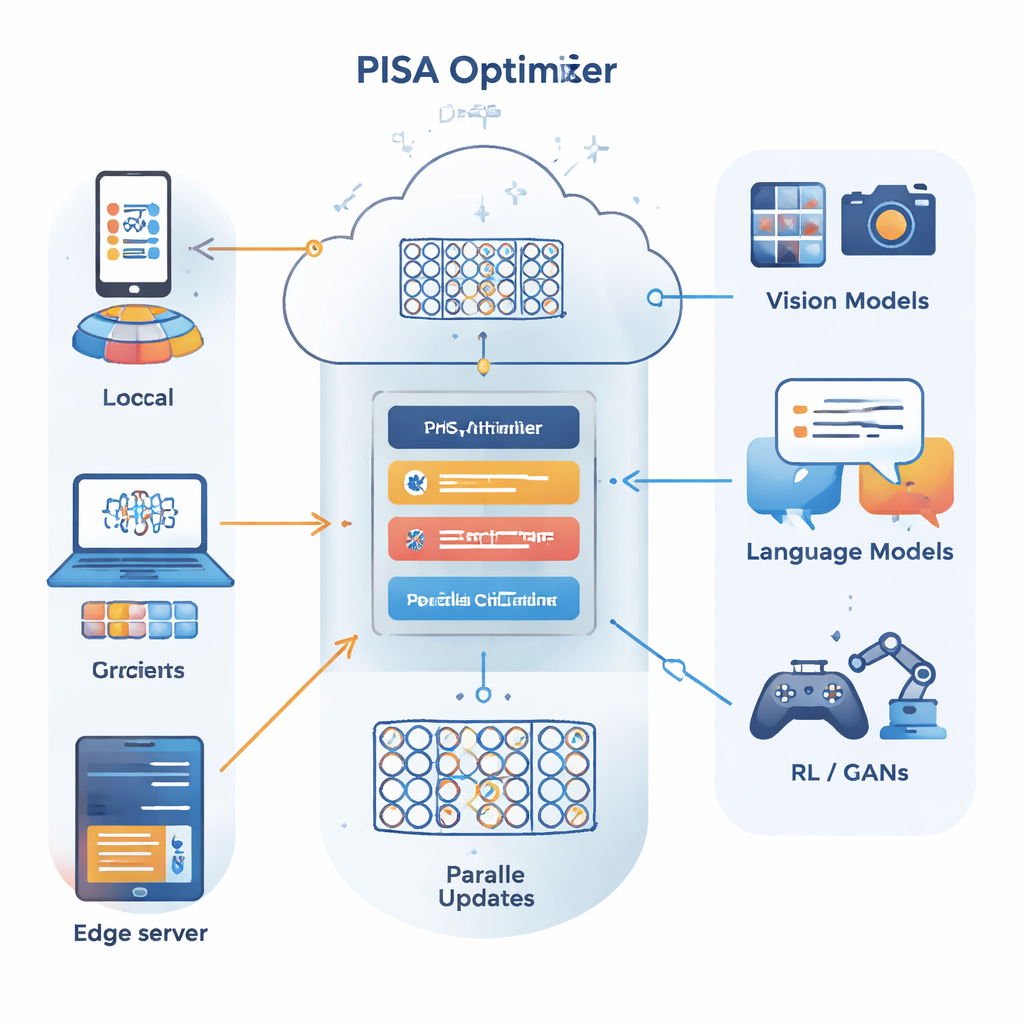
ضمانات أقوى بافتراضات أخف
من سمات PISA المميزة أساسها النظري. يبرهن المؤلفون أن خوارزميتهم تتقارب تحت افتراض واحد نسبيًا ومعتدل: أن تدرج دالة الخسارة مستمر ليبشيتز داخل نطاق محدود، وهو شرط تستوفيه العديد من خسائر الشبكات العصبية الشائعة. على خلاف معظم الطرق العشوائية، لا تتطلب PISA أن تكون التدرجات غير متحيزة أو ذات تباين محدود أو مأخوذة من بيانات مخلوطة تمامًا. على الرغم من هذا الإعداد الأكثر ارتخاءً، تحقق الطريقة معدل تقارب خطيًا من حيث سرعة استقرار قيم الدالة وتحديثات المعلمات، مما يضعها بين أفضل الخوارزميات في جدول المقارنة المقدم. هذا يجعل PISA جذابة بشكل خاص لتوزيعات البيانات غير المتجانسة وغير المنتظمة الشائعة في التطبيقات الواقعية.
نسخ عملية للشبكات العميقة الحقيقية
لجعل الإطار عمليًا للشبكات العصبية الكبيرة، يقدم المؤلفون نسختين فعاليتين، SISA وNSISA. يستخدم SISA معلومات اللحظة الثانية — أي تتبع مدى كبر التحديثات السابقة في كل اتجاه معلمة — لتشكيل مهيئات مسبقة قطرية بسيطة، شبيهة بأفكار Adam وRMSProp ولكن مدمجة داخل بنية ADMM. يذهب NSISA خطوة أبعد بإدماج تقنية تعرف بتعميم نيوتن–شولتز للتنعيم المتعامد، مستلهمة من المحسّن Muon، لمحاذاة الزخم بشكل أفضل مع الاتجاهات المفيدة في فضاء المعلمات. تحتفظ كلتا النسختين بضمانات تقارب PISA مع إبقاء الحساب خفيفًا بما يكفي لوحدات معالجة الرسوميات الحديثة والنماذج الكبيرة.
الأداء عبر مهام الرؤية واللغة والنماذج التوليدية
يختبر المؤلفون SISA وNSISA عبر مجموعة واسعة من مهام التعلم العميق. في تجارب التعلم الفدرالي مع توزيعات تسميات متحيزة عمدًا — وهي بيئة صعبة حيث يرى كل عميل فئة فرعية فقط من الفئات — يتفوق SISA بشكل كبير على طرق شهيرة مثل FedAvg وFedProx وFedNova وScaffold، محققًا دقة اختبار أعلى بكثير على معايير مثل MNIST وCIFAR-10. بالنسبة لتصنيف الصور القياسي مع نماذج مثل ResNet وDenseNet على CIFAR-10 وImageNet، يضاهي SISA أو يتجاوز محسنين أقوياء مثل SGD مع الزخم وAdaBelief وAdamW. عند تعديل نماذج اللغة GPT2 بأحجام متزايدة، يقدم NSISA خسارة تحقق أقل في زمن ساعة فعلي أقل من المحسنين المتخصصين مثل Shampoo وSOAP وAdam-mini وMuon، مع تزايد الفارق لصالحه في النماذج الأكبر. كما يثبت استقرار تدريب الشبكات التوليدية التنافسية، محققًا درجات أقل في مسافة فرِشِيهت للاستدلال (Fréchet inception distance)، التي تقيس جودة وتنوع الصور المُولَّدة. 
ماذا يعني هذا للذكاء الاصطناعي اليومي
بعبارة بسيطة، تُظهر هذه الورقة أنه من الممكن تدريب نماذج ذكاء اصطناعي قوية بسرعة وموثوقية أكبر، حتى عندما تكون البيانات فوضوية أو غير متوازنة أو مبعثرة عبر أجهزة متعددة. من خلال إعادة تصميم عملية التحسين الأساسية بدلًا من مجرد تعديل معدلات التعلم، توفر PISA ونظائرها أداة موحدة تعمل جيدًا لمهام الرؤية واللغة والتعلم التعزيزي والتوليد. للمستخدمين النهائيين، قد يعني ذلك تخصيصًا أذكى على الهواتف، ونماذج لغة وصورة أكثر قدرة، واستخدامًا أكثر كفاءة لموارد الحوسبة في مراكز البيانات الكبيرة — كل ذلك ممكن بواسطة خوارزمية تدريب تتماشى بشكل أفضل مع واقع أنظمة الذكاء الاصطناعي الحديثة.
الاستشهاد: Zhou, S., Wang, O., Luo, Z. et al. Preconditioned inexact stochastic ADMM for deep models. Nat Mach Intell 8, 234–245 (2026). https://doi.org/10.1038/s42256-026-01182-3
الكلمات المفتاحية: تحسين التعلم العميق, التعلم الفدرالي, ADMM العشوائي, نماذج اللغة الكبيرة, بيانات غير متجانسة