Clear Sky Science · ar
متى تكون النماذج اللغوية الكبيرة موثوقة في تقييم التواصل المتعاطف
لماذا يهمك التعاطف الآلي
يتجه الناس بشكل متزايد إلى الدردشات الآلية والمساعدين الرقميين عندما يكونون مضغوطين أو وحيدين أو أمام قرارات صعبة. قد تبدو هذه الأنظمة متعاطفة ومتفهمة—لكن هل يمكنها أيضاً الحكم ما إذا كانت رسالة ما داعمة ولطيفة بالفعل؟ يستكشف هذا المقال متى يمكن للنماذج اللغوية الكبيرة (LLMs)، التقنية وراء العديد من الدردشة الآلية، أن تُقيّم بشكل موثوق مدى شعور الرد المكتوب بالتعاطف، وماذا يعني ذلك لتطبيقات يومية مثل تطبيقات العافية، والمعالجين الافتراضيين، وروبوتات خدمة العملاء. 
دراسة المحادثات الداعمة
حلل الباحثون 200 محادثة نصية حقيقية وصف فيها شخص مشكلة شخصية—مثل ضغوط العمل، أو صراع عائلي، أو قلق مالي، أو صعوبات نفسية—حيث حاول شخص آخر الرد بشكل داعم. جاءت هذه المحادثات من أربعة مجموعات بيانات موجودة مسبقاً، كل منها مرتبطة بمجموعة مختلفة من الأسئلة لتقييم التعاطف. ركزت بعض المجموعات على ما إذا كان المستجيب أظهر تفهماً أو قدّم مواساة عاطفية؛ وسألت مجموعات أخرى ما إذا كان قدّم نصيحة عملية، أو شجّع المتحدث على الكلام أكثر، أو مال إلى جعل المحادثة تدور حول نفسه. معاً، تفكك هذه الأطر «كونك متعاطفاً» إلى 21 سلوكاً محدداً يمكن تقييمها على مقاييس، على غرار استبيان رضا العملاء.
الخبراء، الحشود والآلات
لمعرفة مدى قدرة النماذج اللغوية الكبيرة على تقييم التعاطف، قارن الفريق ثلاثة أنواع من الحكّام: خبراء الاتصالات، والعمال المشاركين عبر الإنترنت، والنماذج اللغوية الحديثة. قيّم ثلاثة علماء متمرسون في التواصل التعاطفي كل محادثة بشكل مستقل على جميع السلوكيات الـ21. كان العمال المشاركون—مستخدمون عاديون على الإنترنت—قد قدّموا بالفعل تقييماتهم لنفس الرسائل في دراسات سابقة. أخيراً، تم توجيه ثلاث نماذج لغوية رائدة بعناية باستخدام إرشادات بلغة بسيطة وأمثلة لتقييمات الخبراء، ثم طُلِب منها تسجيل كل محادثة على نفس المقاييس. سمح هذا الإعداد للمؤلفين بقياس مدى اتفاق كل مجموعة، ليس فقط مع «الإجابة الصحيحة»، بل مع بعضها البعض. 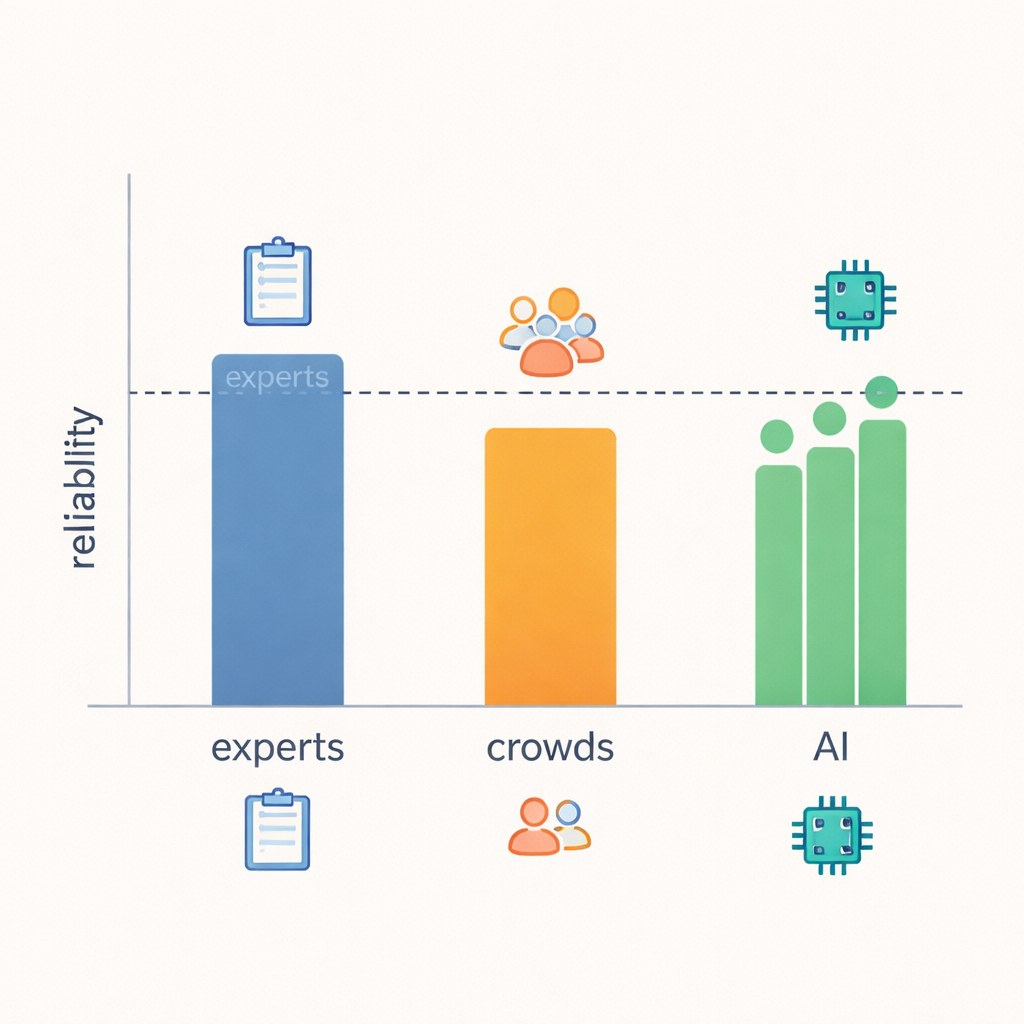
إلى أي مدى يتفقون؟
النتيجة الأساسية هي أن النماذج اللغوية الكبيرة اقتربت بشكل مفاجئ من موثوقية مستوى الخبراء. عندما قاس الباحثون مدى تزامن التقييمات وحجم الاختلافات، طابقت النماذج أو كادت تطابق الخبراء في معظم السلوكيات الـ21، وتفوقت بوضوح على العمال المشاركين. في المجالات التي تتوفر فيها إشارات واضحة وملموسة—مثل ما إذا كان الرد قدم نصيحة عملية، أو طرح أسئلة متابعة، أو أعاد التركيز إلى المتحدث—كان الخبراء والنماذج وحتى الحشود يميلون إلى الاتفاق أكثر. لكن عند الحكم على مفاهيم أكثر غموضاً، مثل ما إذا كان الرد «أظهر تفهماً» فعلاً أو ما كانت عليه نوايا المستجيب، اختلف حتى الخبراء بشكل أكبر، وانخفضت موثوقية النماذج تبعاً لذلك. وهذا يشير إلى أن بعض جوانب التعاطف أصعب ببساطة في التحديد من النص وحده، بغض النظر عن من يقوم بالتقييم.
لماذا قد تضلّل الدرجات البسيطة
تبلغ العديد من دراسات الذكاء الاصطناعي عن نجاح باستخدام مقاييس تصنيف مألوفة—معاملة كل تقييم خبير كحقيقة غير قابلة للنقاش وقياس مدى توافق النموذج معها. يوضح المؤلفون أن هذا النهج يمكن أن يرسم صورة مشوّهة عند التعامل مع أحكام بشرية دقيقة. على سبيل المثال، يمكن لنظام أن يحقق درجات جيدة من خلال التخمين غالباً بتقييم الأغلبية على مقياس غير متوازن، حتى لو كان يكافح في الحالات النادرة لكنها مهمة. وبالمثل، يمكن لطريقة تعطي في الغالب درجات «قريبة جداً من الصحيحة»—بفارق نقطة واحدة فقط—أن تبدو ضعيفة على مقياس المطابقة الصارم، رغم أنها تتصرف إلى حد كبير كخبير بشري. من خلال التركيز على موثوقية التقييم بين المقيمين—مدى اتساق حكم مختلف المقيمين على نفس الشيء—يقدّم البحث صورة أكثر صدقاً لما يمكن لكل من البشر والآلات تقييمه بشكل موثوق.
ماذا يعني هذا للذكاء الاصطناعي اليومي
بالنسبة للشخص العادي، المخلص والخلاصة مزيج من التفاؤل والتحذير. يمكن للنماذج اللغوية الكبيرة المهيأة جيداً الآن أن تساعد في فحص ما إذا كانت الردود المكتوبة—من مساعدين بشريين أو روبوتات أخرى—تفي بمعايير الخبراء في التواصل التعاطفي، وغالباً ما تفعل ذلك باستمرار أكبر من المقيمين البشريين غير المدربين. قد يسهل ذلك مراقبة وتحسين الدردشات المستخدمة في الرعاية الصحية والتعليم وخدمة العملاء. في الوقت نفسه، يحذّر البحث من أن ليست كل «اختبارات التعاطف» متساوية: الأسئلة الغامضة أو المتداخلة تقود إلى اتفاق بشري مترنح ومن ثم أحكام آلية غير مستقرة. قبل أن نثق بالذكاء الاصطناعي لتقييم شيء حساس مثل الدعم العاطفي، يجب أولاً التأكد من أن الخبراء أنفسهم يمكنهم الاتفاق على شكل «الجيد»—واستخدام هذا المعيار لتحديد الأماكن التي يمكن للآلات أن تساعد فيها بأمان وأين يظل الحكم البشري ضرورياً.
الاستشهاد: Kumar, A., Poungpeth, N., Yang, D. et al. When large language models are reliable for judging empathic communication. Nat Mach Intell 8, 173–185 (2026). https://doi.org/10.1038/s42256-025-01169-6
الكلمات المفتاحية: التواصل التعاطفي, النماذج اللغوية الكبيرة, الرفقاء الذكاء الاصطناعي, دعم الصحة النفسية, التفاعل بين الإنسان والذكاء الاصطناعي