Clear Sky Science · ar
نموذج أساس لِفيديوهات الجراحة يعتمد على التعلم الذاتي واسع النطاق
مساعدة أذكى في غرفة العمليات
يعتمد الجراحون المعاصرون بشكل متزايد على الكاميرات والحواسب لتوجيه عملهم، إلا أن الذكاء الاصطناعي الحالي لا يزال يواجه صعوبة في فهم ما يحدث أثناء العملية بشكل كامل. تعرض هذه الورقة طريقة جديدة لتدريب الذكاء الاصطناعي على آلاف فيديوهات الجراحة حتى يتمكن من متابعة خطوات الإجراء بدقة أكبر، والتعرف على الأدوات والأنسجة، وتقييم مدى سلامة ومهارة تقدم العملية. وعلى المدى الطويل، قد تدعم هذه النوعية من التكنولوجيا الجراحين في الوقت الحقيقي، وتحسّن التدريب، وتساهم في زيادة سلامة المرضى أثناء الجراحة.
لماذا تعليم الآلات عن الجراحة صعب
ليس تعليم الحواسب فهم الجراحة مهمة بسيطة يمكن اختصارها في تزويدها ببعض الصور الموسومة. كل إجراء ينطوي على كاميرات متحركة، ووجهات نظر متغيرة، ودخان، ودم، وأيدي وأدوات تحجب بعضها البعض باستمرار. إضافة إلى ذلك، هناك آلاف أنواع العمليات المختلفة، يرتبط العديد منها بندرة عالية. يتطلب وضع وسوم دقيقة على الفيديو إطارًا بإطار خبرة ثمينة ونادرًا ما تكون متاحة، ويصبح ذلك مكلفًا بسرعة. حاولت أنظمة الذكاء الاصطناعي السابقة تخفيف هذا العبء باستخدام حيل تتعلم من الصور غير الموسومة، لكنها كانت تنظر في الغالب إلى إطارات ثابتة وأضفت لاحقًا بعدًا زمنياً. نتيجة لذلك، كانت غالبًا ما تُفوّت سردية العملية المتطورة: ما الذي حدث سابقًا، وما الذي يجري الآن، وما المتوقع أن يحدث لاحقًا.
التعلّم مباشرة من أفلام الجراحة
يجادل المؤلفون بأن الذكاء الاصطناعي المصمم لمساعدة في الجراحة يجب أن يُدرَّب على الفيديوهات بدلاً من الصور المعزولة. لتحقيق ذلك جمعوا واحدة من أكبر مجموعات فيديوهات التنظير الجراحي حتى الآن: 3650 تسجيلًا تضم 3.55 مليون إطار، مأخوذة من مجموعات بيانات بحثية عامة ومن مجموعة واسعة من مقاطع الجراحة المنشورة على الإنترنت. تغطي هذه الفيديوهات أكثر من 20 نوعًا من الإجراءات وأكثر من 10 مناطق تشريحية، من استئصال المرارة إلى جراحات الكبد والعمليات النسائية. تتيح هذه التنوعات للذكاء الاصطناعي رؤية العديد من مظاهر الإجراء في الحياة الواقعية، بما في ذلك اختلاف المستشفيات، والأدوات، وأنماط الكاميرا.
خريطة تعلم جديدة مخصصة للفيديو
بناءً على هذا الكنز من البيانات، صمّم الفريق نموذجًا أساسيًا أطلقوا عليه SurgVISTA، مخصّصًا بشكل خاص لفيديوهات الجراحة. بدلًا من محاولة وسم كل إطار، يتعلم SurgVISTA عن طريق ملء الأجزاء المفقودة. أثناء التدريب تُخفى أجزاء من كل مقطع فيديو، ويجب على النموذج إعادة بناء المناطق المفقودة. هذا يجبره على الانتباه إلى كيفية تغير الأنسجة والأدوات والحركات مع الزمن. في الوقت نفسه، يُدرَّب فرع ثانٍ من النظام على مطابقة الإشارات البصرية التفصيلية التي يستحضرها نموذج خبير قائم على الصور وذو أداء قوي يعرف الكثير عن مشاهد الجراحة. تساعد هذه التركيبة SurgVISTA على استيعاب كل من التفاصيل الدقيقة داخل كل إطار والتدفق الأوسع للعملية بأكملها، ضمن شبكة موحّدة واحدة.
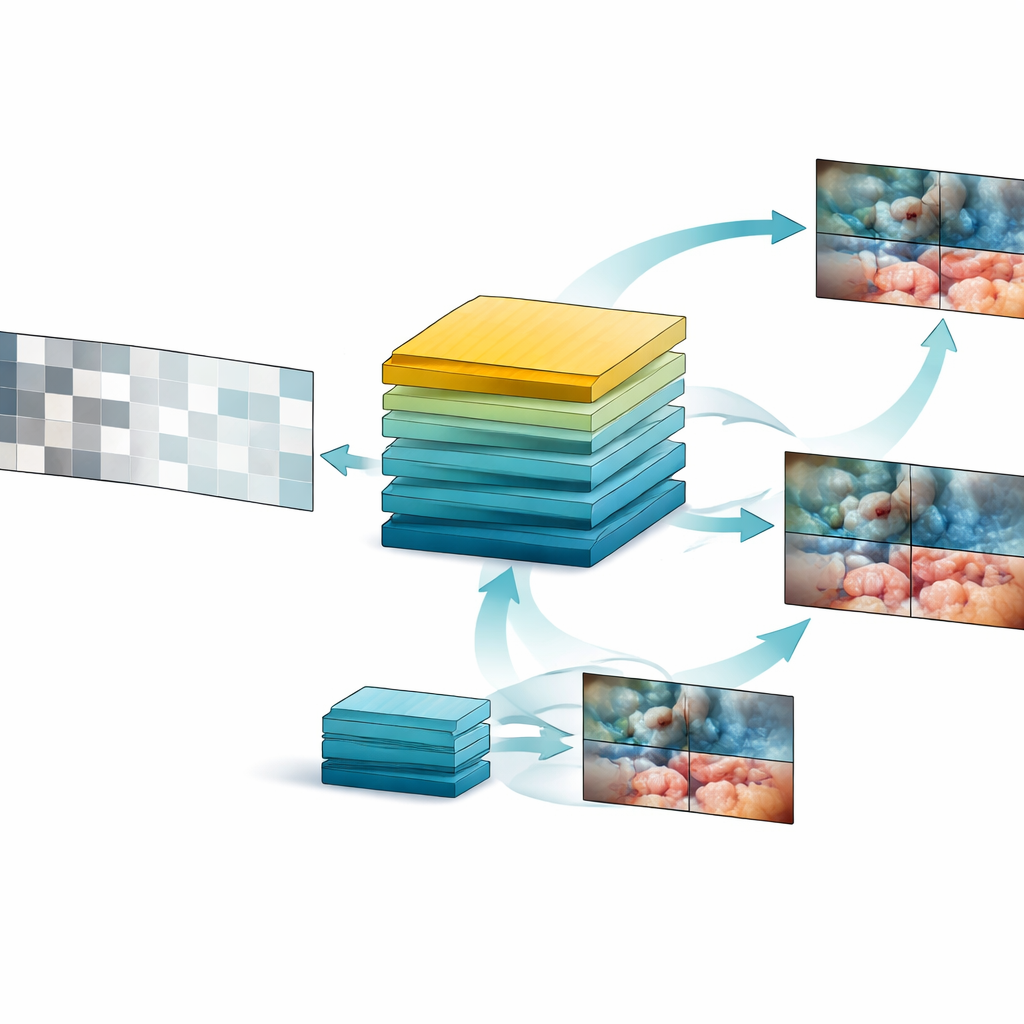
اختبار النموذج
لاختبار ما إذا كانت هذه المقاربة تؤتي ثمارها فعلاً، اختبر المؤلفون SurgVISTA على 13 مجموعة بيانات مختلفة تغطي ستة أنواع من الجراحات وأربع مهام تطبيقية. شملت هذه المهام التعرف على مرحلة العملية الجارية، وتحديد أعمال جراحية محددة، والتقاط العلاقة الثلاثية بين الأداة، والفعل، والنسج المستهدفة، وتقييم مدى سلامة تنفيذ خطوات رئيسية. في كل الحالات، تفوّق SurgVISTA على النماذج الرائدة التي دُرِّبت على فيديوهات يومية، وكذلك على أفضل الأنظمة المخصصة للجراحة التي اعتمدت أساسًا على الإطارات الثابتة. أداؤه كان قويًا حتى في إجراءات لم يرها أثناء التدريب، مما يدل على أن الأنماط التي تعلّمها ليست مرتبطة بعضو واحد أو مجموعة أدوات أو مستشفى محدد.
لماذا تزداد أهمية المزيد من بيانات الفيديو والأكثر تنوعًا
كما بحثت الدراسة كيف يتغير الأداء مع إضافة المزيد من بيانات التدريب. مع توسيع حجم وتنوّع مجموعة الفيديوهات تدريجيًا، تحسّن أداء SurgVISTA في معظم المجالات، بما في ذلك على إجراءات لم تظهر مطلقًا في مجموعة التدريب. من اللافت أن النموذج استفاد ليس فقط من المزيد من أمثلة نفس الإجراء، بل أيضًا من أنواع جراحات مختلفة: فالتعرّض لسرديات جراحية متنوعة ساعده في اكتشاف أنماط بصرية وحركية عامة يمكن نقلها عبر التخصصات. أظهرت تجارب إضافية أن التوجيه الإضافي من الخبير القائم على الصور صقل قدرة النموذج على الحفاظ على التفاصيل التشريحية الدقيقة، وهو أمر بالغ الأهمية لتمييز بنية حيوية عن الأنسجة المحيطة، على سبيل المثال.
ما الذي يعنيه هذا للمستقبل الجراحي
بعبارات بسيطة، تُظهر هذه الدراسة أن ذكاءً اصطناعيًا مُدرَّبًا على كميات كبيرة من فيديوهات الجراحة الحقيقية، مع مراعاة البعدين المكاني والزماني، يمكنه بناء فهم أعمق بكثير لما يحدث في غرفة العمليات. SurgVISTA ليس بعد أداة تتخذ قرارات بمفردها، لكنه يوفر عمودًا فقريًا قويًا يمكن لتطبيقات أخرى أن تتكامل معه—سواء لتعقّب تقدم الجراحة، أو الإشارة إلى لحظات خطرة، أو دعم التدريب، أو مقارنة التقنيات بين المستشفيات. يشير المؤلفون إلى أن هناك حاجة إلى بيانات أوسع وتجارب سريرية إضافية، لكن نتائجهم توحي بأن النماذج الأساسية المبنية على الفيديو قد تصبح مكوّنًا رئيسيًا في أنظمة الجراحة الذكية المستقبلية التي تهدف إلى جعل الإجراءات أكثر أمانًا واتساقًا ومصممة بشكل أفضل لكل مريض.
الاستشهاد: Yang, S., Zhou, F., Mayer, L. et al. Large-scale self-supervised video foundation model for intelligent surgery. npj Digit. Med. 9, 220 (2026). https://doi.org/10.1038/s41746-026-02403-0
الكلمات المفتاحية: ذكاء اصطناعي لفيديوهات الجراحة, التعلم الذاتي, سير العمل الجراحي, الجراحة بمساعدة الحاسوب, النمذجة المكانية والزمانية