Clear Sky Science · ar
نماذج تعلّم الآلة لتنبؤ التفاعلات بين الأدوية: من الاكتشاف الحاسوبي إلى التطبيق السريري
لماذا قد يكون دمج الأدوية محفوفًا بالمخاطر
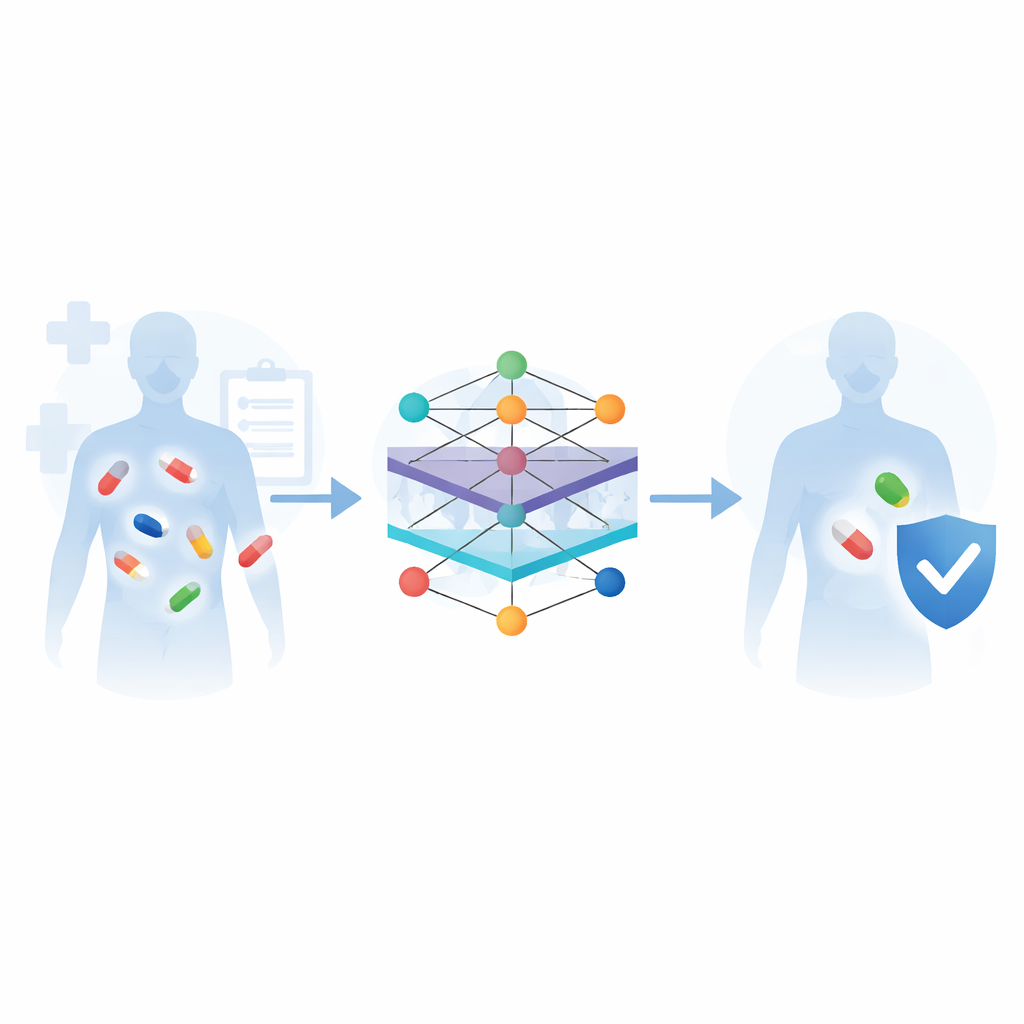
تعتمد الطب الحديث كثيرًا على تناول عدة أدوية في آن واحد—لعلاج السرطان وأمراض القلب والعدوى، أو لإدارة الحالات المتعددة المصاحبة للتقدّم في العمر. لكن عندما تلتقي الأدوية داخل الجسم، قد تُغيّر كل منها أثر الآخر، مما يجعل العلاج أقل فعالية أو حتى خطيرًا. تستعرض هذه المراجعة كيف يُستخدم الذكاء الاصطناعي، وبخاصة أساليب تعلّم الآلة الحديثة، لتوقع هذه التفاعلات بين الأدوية مسبقًا؛ بحيث يمكن للأطباء اختيار تركيبات أكثر أمانًا وتكييف العلاجات مع خصائص المريض الفردية.
من التجربة والخطأ إلى السلامة المدفوعة بالبيانات
تقليديًا، كانت التركيبات الدوائية المثيرة للقلق تُكتشف بالطريقة الصعبة—أثناء التجارب السريرية المتأخرة أو بعد وصول الدواء إلى السوق وحدوث أضرار للمرضى. تبقى الاختبارات المخبرية على الخلايا والحيوانات والمتطوعين المعيار الذهبي، لكنها بطيئة ومكلفة ومن المستحيل تطبيقها على العدد الهائل من أزواج الأدوية المحتملة. يرى المؤلفون أن التنبؤ الحاسوبي يوفر مخرجًا من عنق الزجاجة هذا. عبر تعلّم الأنظمة من مجموعات رقمية ضخمة من معلومات الأدوية—مثل الهياكل الكيميائية، والأهداف الحيوية، والآثار الجانبية المعروفة، وتقارير العالم الحقيقي عن تفاعلات ضارة—يمكن لأنظمة تعلّم الآلة تحديد الأزواج الخطرة بعيدًا قبل أن تصل إلى عدد كبير من المرضى.
كيف تتعلّم الآلات من أنواع متعددة من بيانات الأدوية
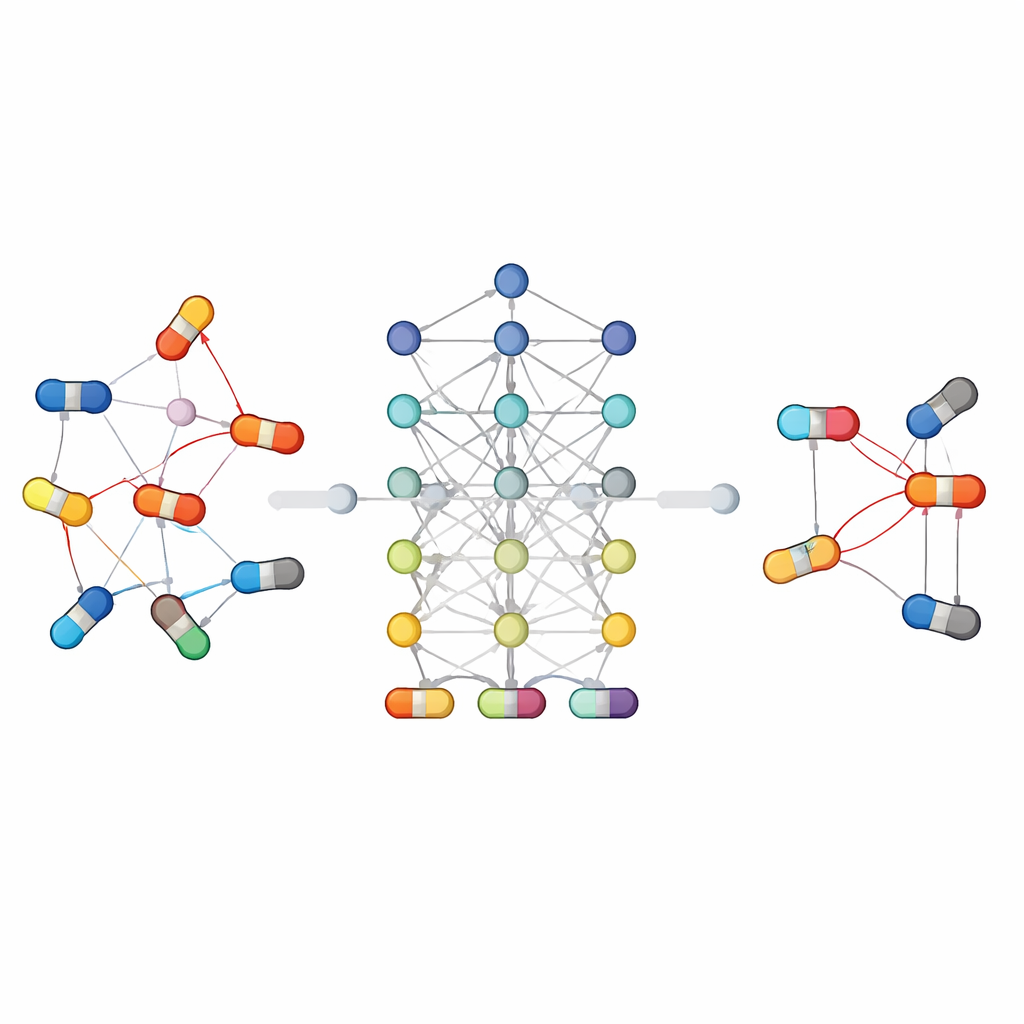
تشرح المراجعة سير عمل شائعًا لهذه الأنظمة التنبؤية. أولًا، تُجمَع المعلومات من قواعد بيانات طبية حيوية رئيسية: مكتبات كيميائية تصف شكل كل جزيء، وخرائط مسارات توضّح كيف تُعالَج الأدوية في الجسم، وقوائم مُنقّحة للتفاعلات والآثار الجانبية المعروفة. بعد ذلك، تُحوِّل الخوارزميات هذه المعلومات الخام إلى أنماط رقمية يمكن للحواسيب فهمها—مثل قياس مدى تشابه دوائين، أو تمثيل كل دواء كعقدة في شبكة مرتبطة بأهدافه ومساراته وتفاعلاته السابقة. تُدرّب نماذج تعلّم الآلة المختلفة بعد ذلك على التعرف على الأزواج التي تميل إلى التسبب في مشكلات، وتُقيّم أداؤها مقابل مجموعات بيانات معيارية باستخدام مقاييس الدقة القياسية.
عائلات خوارزمية مختلفة تتعامل مع المشكلة بطريقتها الخاصة
نظرًا لتعقّد تفاعلات الأدوية، لا يوجد نوع نموذج واحد يفوق الجميع في كل الحالات. تعتمد بعض المقاربات على مصنّفات تقليدية تعمل بميزات مصمَّمة يدويًا، في حين يتعلم غيرها مباشرة من بنية الجزيئات أو من شبكة العلاقات بين الأدوية والكيانات البيولوجية. كانت الأساليب القائمة على الرسوم البيانية والتعلّم العميق ناجحة بشكل خاص: فهي تتعامل مع الأدوية وعلاقاتها كشبكة، مما يسمح للخوارزمية "بالاستدلال" عبر سلاسل من الاتصالات التي قد تكون خفية على النماذج الأبسط. تشارك استراتيجيات أخرى المعلومات عبر مهام ذات صلة، مثل التنبؤ ليس فقط بما إذا كان دواءان يتفاعلان ولكن أيضًا بنوع الأثر الناتج، مما يساعد عندما تكون البيانات نادرة. يبرز المقال أيضًا اتجاهات جديدة مثل نماذج اللغة الكبيرة التي تقرأ النصوص العلمية والملاحظات السريرية، والنماذج المُولِّدة التي تستكشف أنماط تداخل محتملة في مجموعات بيانات شاسعة ومشتّتة.
ربط تنبؤات الحاسوب بالمرضى الحقيقيين
بعيدًا عن الأساليب نفسها، يؤكد المقال كيف يمكن لهذه الأدوات دعم الرعاية الواقعية. يناقش المؤلفون كيف أن النماذج المدربة على قواعد بيانات مُنقّحة وسجلات سريرية يمكن أن تنبه الأطباء إلى التركيبات الخطيرة عند السرير، وتساعد في تصميم أنظمة علاجية متعددة الأدوية أكثر أمانًا في مجالات مثل السرطان وطب القلب والأمراض المعدية، وتحديد الأولويات للتفاعلات المتوقعة التي تستحق اختبارًا مخبريًا. كما يستعرضون أمثلة سريرية كلاسيكية—مثل المضادات الحيوية التي تغيّر مستويات أدوية خافضة للكوليسترول، أو مسكنات الألم التي تمنع آثار بعضها البعض، أو عصائر الفاكهة التي تزيد بصورة غير متوقعة تركيز بعض الأدوية—لإظهار المسارات الكثيرة التي تنشأ منها التفاعلات. يمكن لأنظمة تعلّم الآلة التي تلتقط هذه الأنماط أن تعمل كأجهزة إنذار مبكرة، لا سيما لدى المرضى المسنين الذين يتناولون أدوية متعددة.
تحدّيات في طريق الذكاء الاصطناعي الموثوق للأدوية
رغم الدقة المثيرة للإعجاب على مجموعات الاختبار، يؤكد المؤلفون أن النماذج الحالية لا تزال تواجه عقبات مهمة قبل أن يُعتمد عليها على نطاق واسع في العيادات. كثير منها "صندوق أسود" يقدم رؤية قليلة حول سبب اعتبار زوج معين خطيرًا، مما يصعّب على الأطباء تقييم التوصية أو شرحها. قد تتعثر النماذج عندما تكون البيانات ضوضائية أو غير متوازنة—على سبيل المثال، عندما تكون التفاعلات الضارة نادرة مقارنة بالأزواج الآمنة. إن دمج المعلومات عبر الكيمياء، والوراثة، والسجلات الصحية الإلكترونية، والأدبيات المنشورة أمر معقّد تقنيًا، وتتطلب الأطر التنظيمية دليلًا قويًا قبل أن تؤثر هذه الأدوات على وصف الأدوية. يجادل المؤلفون بأن الأبحاث المستقبلية يجب أن تركز على نماذج أكثر قابلية للتفسير، ومعالجة أفضل للتحيز والبيانات الناقصة، وأنظمة يمكنها التعلم المستمر من الخبرة السريرية الجديدة مع احترام قواعد الخصوصية والسلامة.
ما يعنيه هذا لعلاج المرضى يوميًا
بعبارة مبسطة، تُظهر هذه المراجعة أن الذكاء الاصطناعي يصبح حليفًا قويًا في الحفاظ على أمان تركيبات الأدوية. عبر غربلة جبال من البيانات الرقمية التي تتجاوز قدرة أي خبير بشري، يمكن لنماذج تعلّم الآلة تسليط الضوء على الأزواج الخطرة، واقتراح بدائل أكثر أمانًا، ودعم وصفات أكثر تخصيصًا. هذه الأدوات لن تحلّ محلّ الحكم السريري أو الاختبارات المخبرية الدقيقة، لكنها يمكن أن تساعد في ضمان ألا تؤدي تعقيدات العلاج العصري المتزايدة إلى المساس بسلامة المرضى.
الاستشهاد: Lu, Y., Chen, J., Fan, N. et al. Machine learning models for drug-drug interaction prediction from computational discovery to clinical application. npj Digit. Med. 9, 198 (2026). https://doi.org/10.1038/s41746-026-02400-3
الكلمات المفتاحية: تفاعلات الأدوية, تعلّم الآلة في الطب, الشبكات العصبية الرسومية, الدواء السريري, سلامة الذكاء الاصطناعي