Clear Sky Science · ar
تقييم نماذج اللغة الكبيرة لتوليد الانطباعات التشخيصية من نتائج تقارير رنين الدماغ المغناطيسي: معيار متعدد المراكز ودراسة قرَّاء
لماذا تهم تقارير الرنين المغناطيسي الأكثر ذكاءً المرضى
عندما تخضع لفحص دماغي، يحتاج أخصائي الأشعة إلى تحويل آلاف درجات الرمادي إلى بيان واضح لما الذي يعيبك — أو إلى أن كل شيء يبدو طبيعياً. توجه هذه «الانطباعات» النهائية قرارات حاسمة تتعلق بعلاج السكتة الدماغية، وأورام الدماغ، والالتهابات، وغير ذلك. لكن قراءة فحوصات رنين الدماغ مغناطيسي معقَّدة وتستغرق وقتاً، والأطباء المرهقون قد يرتكبون أخطاء، خصوصاً في المستشفيات المزدحمة. تستكشف هذه الدراسة ما إذا كانت نماذج لغة اصطناعية متقدمة يمكنها موثوقاً مساعدة أخصائيي الأشعة على تحويل نتائج الرنين المكتوبة إلى انطباعات تشخيصية دقيقة وسريعة ومتسقة.
تحويل أوصاف الفحوصات الخام إلى إجابات واضحة
تنتج فحوصات رنين الدماغ سلسلة من الصور يصفها أخصائيو الأشعة في قسم «النتائج» كتابةً، ملاحظين أموراً مثل موقع الآفة، ومدى سطوعها، وما إذا كان هناك وذمة. التحدي الحقيقي هو جمع كل تلك التفاصيل في انطباع تشخيصي، مثل «احتشاء حاد» أو «خراج دماغي». جمع الباحثون 4293 تقرير رنين مغناطيسي للدماغ من ثلاثة مستشفيات في الصين، تغطي 16 فئة تشخيصية تشمل أكثر من 95% من حالات الدماغ اليومية. ثم اختبروا 10 نماذج لغة كبيرة مختلفة — أنظمة ذكاء اصطناعي متقدمة قائمة على النص — لمعرفة مدى قدرة كل منها على تحويل النتائج المكتوبة إلى التشخيص الصحيح.
نماذج الذكاء الاصطناعي الكبيرة والمتغذِّية جيداً كانت الأفضل
قارن الفريق نماذج نطاق معلماتها الداخلية من حوالي 8 مليارات إلى 671 مليار، وهو تمثيل تقريبي للانتقال من معرفة طالب طب إلى معرفة فريق خبراء. النموذج الأكبر، المسمى DeepSeek-R1، قدّم أداءً ممتازاً باستمرار عندما وُفِّق بين إصدارات مُنظَّمة من النتائج ومعلومات سريرية رئيسية مثل عمر المريض، والأعراض، أو تاريخ الإصابة. في هذه الظروف، حدَّد DeepSeek-R1 بموثوقية وجود أو غياب حالات دماغية محددة بحساسية ونوعية عاليتين، وحقق دقة مستوى المريض بأكثر من 87%. النماذج الأصغر، خصوصاً تلك التي تقل عن 10 مليارات معلمة، واجهت صعوبات كبيرة، وغالباً ما كانت تصحح نحو 30% فقط من الحالات — وهو مستوى أقل بكثير مما يُقبل في الممارسة السريرية الحقيقية.
لماذا تجعل البنية والسياق الذكاء الاصطناعي أذكى
لم يقدّم الباحثون للنماذج نصاً حرّاً فحسب. استخدموا أيضاً نظام ذكاء اصطناعي آخر لإعادة هيكلة التقارير إلى عناصر واضحة وموحَّدة: موقع كل آفة، وعددها، ومظهرها على تسلسلات الرنين المختلفة. أدت إضافة هذه البنية، ودمجها مع ملاحظات سريرية قصيرة، إلى فرق ملحوظ. بالنسبة لـ DeepSeek-R1، أدى الانتقال من نص النتائج الخام إلى نتائج مُنظَّمة مع سياق سريري إلى زيادة الحساسية والدقة العامة ومقاييس الأداء الملخصة. ببساطة، آداء الذكاء الاصطناعي تحسّن بشكل كبير عندما نزوّده بمعلومات أنظف وأكثر تنظيماً وقليل من الخلفية عن المريض — وهو ما يعكس كيف يعمل أخصائيو الأشعة البشريون بشكل أفضل عندما تكون التقارير مرتبة والسؤال السريري واضحاً.
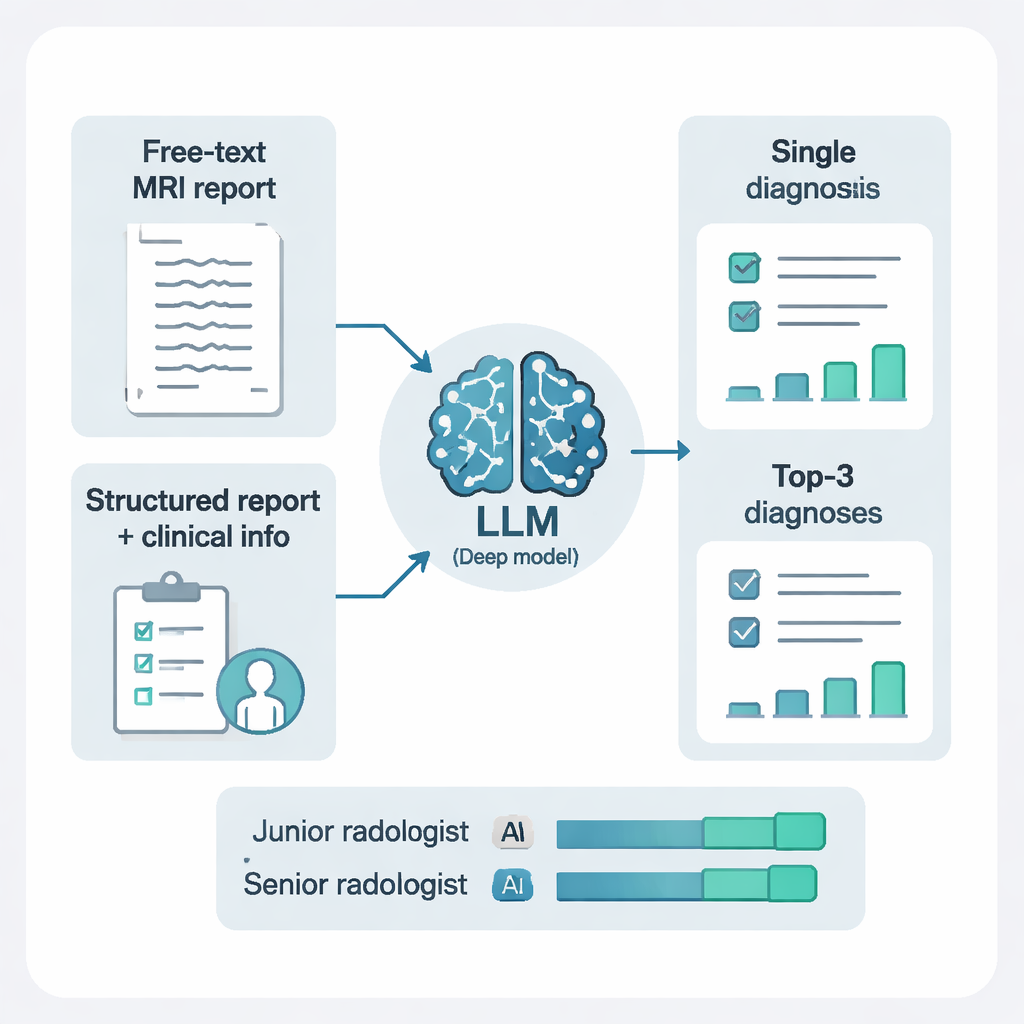
من تخمين واحد إلى قائمة قصيرة مرتَّبة
في الحياة الواقعية، يقدم أخصائيو الأشعة غالباً أكثر من تشخيص محتمل للحالات المعقَّدة. اختبرت الدراسة أسلوبَيْن في التحفيز: طلب تشخيص واحد فقط من الذكاء الاصطناعي، أو طلب أفضل ثلاث احتمالات، مع تفسير موجز لكل منها. سمح وجود ثلاث تشخيصات مرتّبة بتحسن كبير في الأداء. مع نهج «التشخيص التفاضلي» هذا، ظهر التشخيص الصحيح ضمن أعلى ثلاث اقتراحات لأكثر من 97% من المرضى. كان هذا مفيداً بشكل خاص في الحالات المعقّدة مثل الأورام، والنزوف، أو الأمراض الالتهابية، حيث يمكن أن يكون التخمين القسري الواحد مضلِّلاً، بينما تساعد قائمة قصيرة ومبرَّرة في توجيه الاختبارات والعلاج بشكل فعّال.
التأثير في العالم الحقيقي على أخصائيي الأشعة المزدحمين
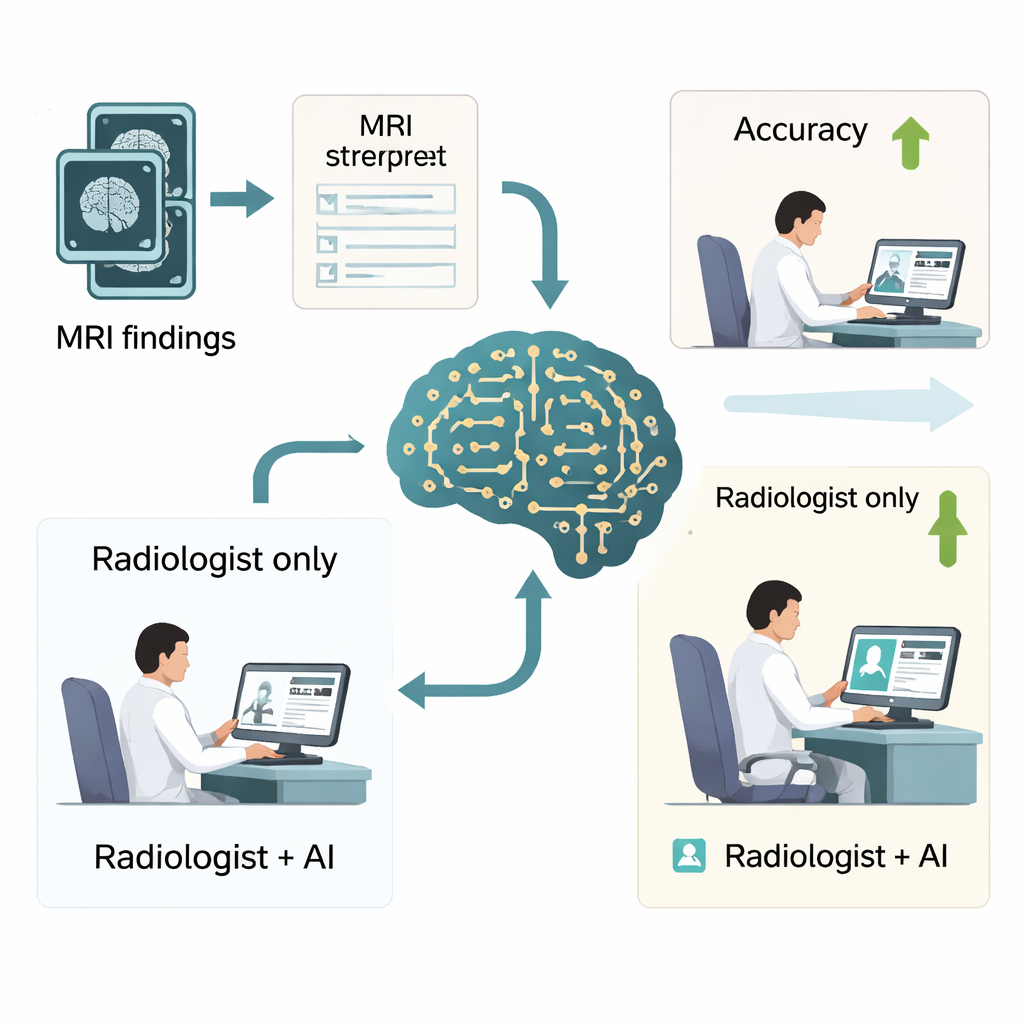
لاختبار ما إذا كانت هذه المكاسب مهمة عملياً، أجرى المؤلفون دراسة قراءة بمشاركة ستة أخصائيي أشعة — ثلاثة مبتدئين وثلاثة كبار — الذين فسَّروا 500 تقرير رنين دماغي مع وبدون مساعدة DeepSeek-R1. مع مساعدة الذكاء الاصطناعي، ارتفعت دقة التشخيص الإجمالية من نحو ثلاثة أرباع الحالات إلى أكثر من 90%، كما تحسّن مقياس جودة رئيسي يقيس الدقة والاسترجاع بشكل كبير. انخفض وقت القراءة كذلك، من نحو دقيقة لكل حالة إلى أقل من دقيقة، ما قد يترجم إلى عشرات الساعات الموفرة لكل أخصائي أشعة سنوياً. لوحظت أكبر الفوائد بين الأطباء المبتدئين، حيث تقاربت أداؤهم مع خبراء متمرسين، مع التأكيد أيضاً في الدراسة على ضرورة أن يظل الأطباء حذرين ولا يثقوا بالذكاء الاصطناعي بشكل أعمى، خصوصاً في الحالات الدقيقة جداً مثل بعض أنواع نزف الدماغ.
ماذا يعني هذا لتقارير فحوصات الدماغ في المستقبل
للمرضى، الخلاصة الرئيسية هي أن أنظمة الذكاء الاصطناعي القوية القائمة على النصوص يمكن أن تساعد بالفعل أخصائيي الأشعة على تحويل أوصاف الرنين المعقدة إلى انطباعات تشخيصية أوضح وأكثر دقة، خصوصاً عند تزويدها بمعلومات منظَّمة جيداً وتفاصيل سريرية أساسية. هذه الأدوات ليست بديلاً عن الخبرة البشرية لكنها يمكن أن تكون بمثابة نظرة ثانية متأنية، تقدّم اقتراحات مبرَّرة وتوفّر الوقت. إذا أمكن التحقق من فعاليتها على نطاق أوسع ودمجها بأمان في أنظمة المستشفيات، فقد تساعد هذه الدعَمات بالذكاء الاصطناعي في جعل تقارير فحوصات الدماغ أسرع وأكثر موثوقية واتساقاً — مما يحسّن الرعاية للأشخاص المصابين بالسكتات الدماغية، والأورام، والالتهابات، والعديد من حالات الدماغ الأخرى.
الاستشهاد: Wang, ML., Zhang, RP., Wu, WJ. et al. Evaluation of large language models for diagnostic impression generation from brain MRI report findings: a multicenter benchmark and reader study. npj Digit. Med. 9, 187 (2026). https://doi.org/10.1038/s41746-026-02380-4
الكلمات المفتاحية: تشخيص رنين مغناطيسي للدماغ, الذكاء الاصطناعي في الأشعة, نماذج اللغة الكبيرة, دعم القرار السريري, DeepSeek-R1