Clear Sky Science · ar
نماذج اللغة الكبيرة تُحسِّن قابلية نقل التنبؤات المبنية على السجلات الصحية الإلكترونية عبر البلدان وأنظمة الترميز
لماذا يهم تبادل البيانات الطبية بذكاء أكبر
المستشفيات والعيادات حول العالم تملك كنزاً من المعلومات: سجلات صحية إلكترونية توثّق تشخيصات المرضى وعلاجاتهم ونتائجهم عبر سنوات طويلة. نظرياً، يمكن أن تساعد هذه المعلومات الأطباء على اكتشاف من هم عُرضة للإصابة بأمراض خطيرة مبكراً، قبل أن تتضح الأعراض. عملياً، تواجه نماذج الحاسوب الحالية صعوبة في «الانتقال» من بلد أو نظام صحي إلى آخر لأن كل مكان يسجّل البيانات الصحية بطريقة مختلفة. تقدم هذه الدراسة نهجاً جديداً اسمه GRASP، يستخدم تقدمات في الذكاء الاصطناعي لسد هذه الفجوات بحيث يعمل نموذج مدرّب في نظام صحي واحد بشكل موثوق في أنظمة أخرى.
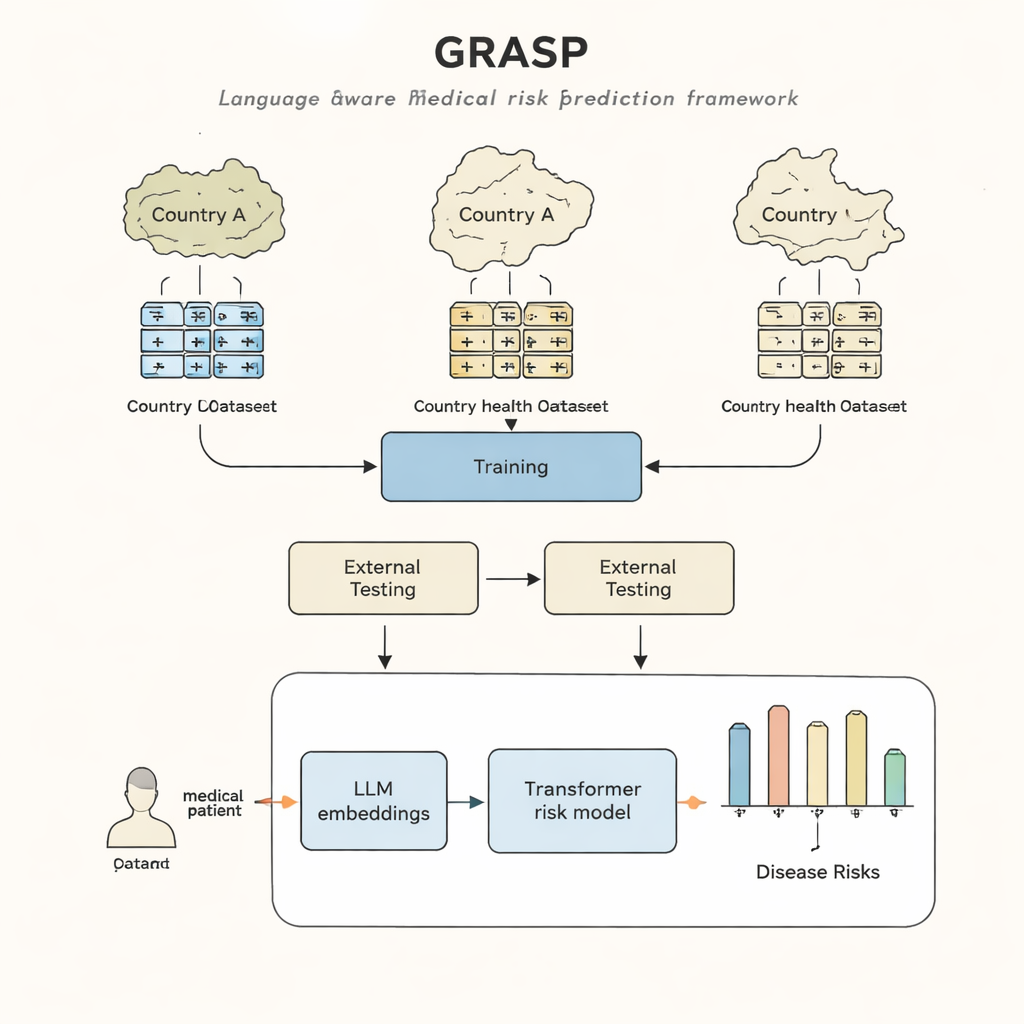
مستشفيات مختلفة، لغات مختلفة
حتى عندما يعالج الأطباء نفس المرض، غالباً ما يستخدمون أنظمة ترميز وعادات محلية مختلفة لتسجيله في السجل الطبي. قد يخزن مستشفى واحد «ارتفاع سكر الدم» تحت رمز معين، بينما يستخدم آخر رمزاً مختلفاً لـ«فرط سكر الدم»، وثالث نظاماً آخر تماماً. المحاولات لفرض معيار مشترك واحد—مثل مخططات الترميز الدولية الكبيرة—مفيدة لكنها بطيئة ومكلفة، وما تزال تترك فروقاً مهمة. نتيجة لذلك، قد يفقد نموذج حاسوبي يتنبأ بالأمراض من سجلات بلد ما دقته عند تطبيقه في مكان آخر، مما يحدّ من من يستفيد من هذه الأدوات.
السماح للذكاء الاصطناعي بقراءة المعنى، لا الرمز فقط
يبدأ نهج GRASP بفكرة بسيطة: بدلاً من التعامل مع كل رمز طبي كرقم هوية عديم المعنى، دَع نموذج لغة كبير يقرأ الوصف البشري وراءه، مثل «التهاب الجهاز التنفسي العلوي الحاد»، ويحوّل ذلك المعنى إلى «تمثيل عددي» أو تضمين (embedding). تضع هذه التضمينات المفاهيم ذات الصلة قريبة من بعضها في فضاء مشترك، حتى لو جاءت من أنظمة ترميز أو بلدان مختلفة. يحسب GRASP هذه التضمينات مسبقاً لملايين المصطلحات الطبية القياسية ويخزنها في جدول بحث. ثم يُمثّل تاريخ المريض الطبي كسلسلة من هذه المتجهات الغنية، التي تُمرّر إلى شبكة تحويل (ترانسفورمر)—نوع من الشبكات العصبية المناسب لمعالجة مجموعات المدخلات المتنوعة—لتقدير خطر هذا الشخص لـ21 مرضاً رئيسياً بالإضافة إلى تقدير المخاطر الإجمالية للوفاة.
الاختبار عبر البلدان وأنظمة السجلات
درّب الباحثون GRASP باستخدام بيانات من ما يقرب من 400,000 مشارك في قاعدة بيانات UK Biobank، ثم اختبروه دون إعادة تدريب في بيئتين مختلفتين جداً: مشروع FinnGen في فنلندا وشبكة مستشفيات كبيرة في مدينة نيويورك. حقّق GRASP أداءً مساوياً أو متفوقاً على بدائل قوية، بما في ذلك طريقة شائعة تُسمى XGBoost ونموذج ترانسفورمر مماثل لم يستخدم تضمينات مبنية على اللغة. في فنلندا، كان أداء GRASP جيداً بشكل خاص، وأظهر مكاسب واضحة لحالات مثل الربو، مرض الكلى المزمن، وفشل القلب. ومن اللافت أنه حتى عندما تُركت بيانات المستشفيات الأمريكية في نظام ترميز مختلف بدلاً من تحويلها إلى معيار مشترك، قدّم GRASP توقعات أفضل من الاعتماد على البيانات الديموغرافية فقط، لأنه استطاع محاذاة الرموز فقط من خلال فهم صياغة أوصافها.
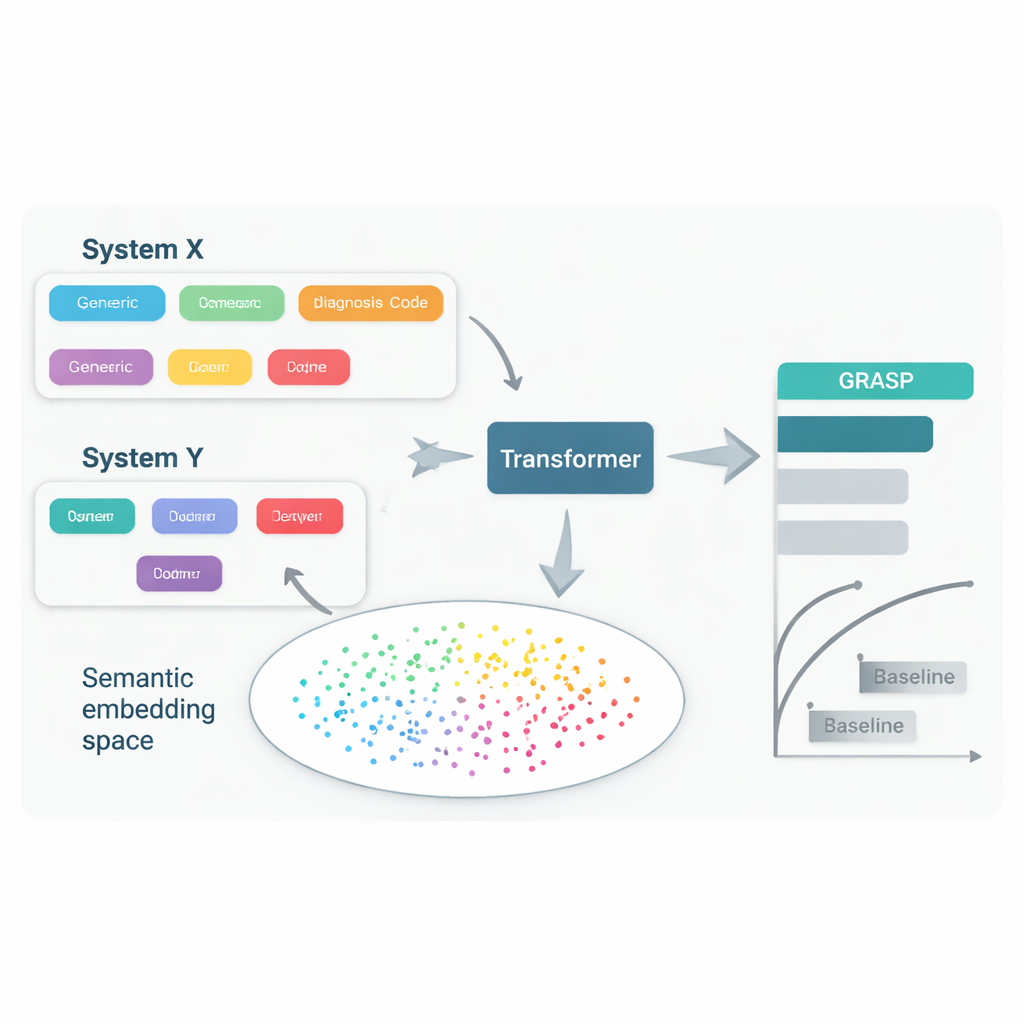
الحصول على المزيد من بيانات أقل
ميزة أخرى لـGRASP هي الكفاءة. لأن نموذج اللغة قد تعلّم بالفعل أن العديد من المفاهيم الطبية مترابطة، فإن شبكة التنبؤ لا تحتاج لإعادة اكتشاف هذه الروابط من الصفر. عندما درّب المؤلفون GRASP على مجموعات أصغر بكثير من بيانات المملكة المتحدة—حتى عند حد 10,000 شخص فقط—ظل يتفوق على النماذج المنافسة التي درِّبت على نفس العينات المحدودة، سواء في المملكة المتحدة أو عند نقلها إلى الخارج. كما كانت درجات الخطر التي أنتجها GRASP أكثر انسجاماً مع المخاطر الوراثية الموروثة للأشخاص لعدة أمراض، ما يشير إلى أنه يلتقط جوانب أعمق من القابلية للإصابة بالأمراض بدلاً من مجرد حفظ أنماط مجموعة بيانات واحدة.
ماذا يعني هذا لرعاية المرضى في المستقبل
للغير متخصصين، الرسالة الأساسية هي أن GRASP يُظهر كيف يمكن للذكاء الاصطناعي المعتمد على اللغة الحديثة أن يساعد الأنظمة الصحية المختلفة «على التحدث بلغة واحدة» دون إجبارها على تبنّي مخطط ترميز جامد واحد. بقراءة معنى المصطلحات الطبية، يمكن لـGRASP أن يقدم تنبؤات مخاطر أمراض تعمّم أفضل عبر البلدان وصيغ السجلات، ويمكنه القيام بذلك بعدد أقل من أمثلة المرضى. بينما لا يزال النهج بحاجة إلى اختبارات دقيقة وإعادة معايرة وفحوصات للعدالة قبل استخدامه في الرعاية اليومية، فإنه يشير إلى مستقبل يمكن فيه مشاركة أدوات المخاطر القوية المطوّرة في مكان واحد بأمان وكفاءة مع مستشفيات وعيادات حول العالم.
الاستشهاد: Kirchler, M., Ferro, M., Lorenzini, V. et al. Large language models improve transferability of electronic health record-based predictions across countries and coding systems. npj Digit. Med. 9, 177 (2026). https://doi.org/10.1038/s41746-026-02363-5
الكلمات المفتاحية: السجلات الصحية الإلكترونية, تنبؤ مخاطر الأمراض, نماذج اللغة الكبيرة, مشاركة البيانات الطبية, الذكاء الاصطناعي في الرعاية الصحية