Clear Sky Science · ar
مقارنة التعلم الموزع والنماذج السريرية القائمة على الذكاء الاصطناعي بالبدائل المحلية والمركزة: مراجعة منهجية
لماذا يهم مشاركة الرؤى الطبية دون مشاركة البيانات
تعتمد الطب الحديث بشكل متزايد على الذكاء الاصطناعي لاكتشاف الأمراض مبكراً، واختيار العلاج المناسب، والتنبؤ بمن هم الأكثر عرضة للخطر. ومع ذلك تحتاج أفضل أدوات الذكاء الاصطناعي إلى كميات هائلة من بيانات المرضى، ولا يمكن للمستشفيات ببساطة تجميع سجلاتها بسبب قوانين الخصوصية الصارمة والاعتبارات الأخلاقية. تراجع هذه المقالة أكثر من عقد من البحث حول «التعلّم الموزّع»—وهي طرق تمكّن المستشفيات من تدريب الذكاء الاصطناعي معاً دون مشاركة بيانات المرضى الخام—وتطرح سؤالاً عملياً: ما مدى فعالية هذه الأساليب المحافظة على الخصوصية مقارنة بالنهج التقليدية؟
أساليب جديدة للتعلم من المرضى مع حماية الخصوصية
في التعلّم المركزي التقليدي، تنسخ المستشفيات كل بياناتها إلى قاعدة بيانات كبيرة واحدة وتدرّب نموذجاً واحداً هناك. في التعلّم المحلي، يبني كل مؤسسة نموذجه الخاص على بياناته دون تعاون. يقدم التعلّم الموزّع مساراً وسطاً. في التعلّم الفدرالي، على سبيل المثال، يدرب كل مستشفى نموذجاً محلياً ثم تُرسل فقط إعدادات النموذج (مثل «مقابض» الشبكة العصبية) لتُدمج في نموذج مشترك؛ تبقى سجلات المرضى في المواقع الأصلية. يزيل التعلم الجماعي (Swarm learning) المنسق المركزي ويسمح للمؤسسات بتبادل تحديثات النموذج مباشرة. وتجمع نهج موزعة أخرى بين توقعات نماذج محلية متعددة، أو تقسم النموذج عبر المواقع. اختُبرت هذه الطرق في مشكلات تتراوح من اكتشاف السرطان وتشخيص كوفيد‑19 إلى أمراض القلب والسكري واضطرابات الدماغ والحالات النفسية.
ما الذي فحصه الباحثون
بحث المؤلفون بشكل منهجي في 11 قاعدة بيانات رئيسية وفرزوا 165,010 دراسة نُشرت بين 2012 ومارس 2024. بعد إزالة التكرارات والدراسات التي لم تتضمن قرارات سريرية حقيقية، بقي 160 مقالة. أبلغت هذه الأوراق مجتمعة عن 710 نماذج موزعة و8,149 مقارنة أداء مباشرة مقابل نماذج مركزية أو محلية. ركزت معظم الدراسات على التشخيص، لكن كانت هناك أيضاً العديد من الدراسات حول تجزئة الصور (مثل تحديد محيط الأورام)، والتنبؤ بالنتائج المستقبلية مثل البقاء أو المضاعفات، والمهام المركبة. شملت أنواع البيانات تقريباً كل مصدر رئيسي مستخدم في الطب: السجلات الصحية الإلكترونية، الأشعة المقطعية والرنين المغناطيسي، الأشعة السينية، شرائح الباثولوجيا الرقمية، إشارات القلب والدماغ، وحتى البيانات الجينية.
كيف تقارن النماذج المحافظة على الخصوصية بالنماذج المركزية
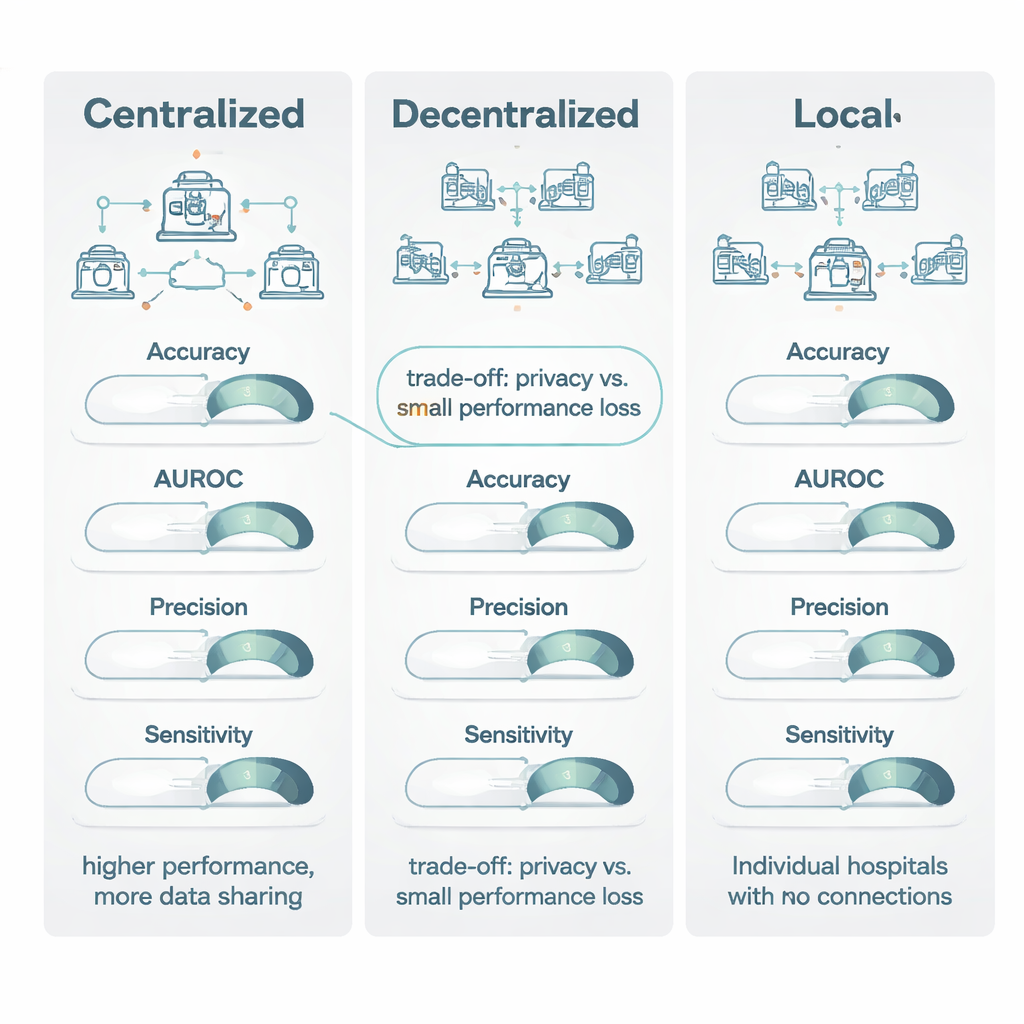
عند مقارنة النماذج الموزعة مع النماذج المركزية المدربة على بيانات مدمجة، تفوقت التعلم المركزي عادةً بفارق طفيف. كان أداؤه أفضل بشكل خاص في المقاييس القائمة على العتبة مثل الدقة ومقياس تصوير شائع يُدعى معامل Dice، حيث فاز في حوالي ثلاثة أرباع الحالات وبفارق يُعتبر فائدة متوسطة إلى كبيرة. ومع ذلك، بالنسبة لمقاييس الترتيب—مثل المساحة تحت منحنى ROC (AUROC)، التي تقيس مدى قدرة النموذج على ترتيب المرضى من مخاطرة أقل إلى أعلى—كانت النماذج الموزعة والمركزية أقرب كثيراً، مع أفضلية طفيفة للتدريب المركزي. ومن المهم أن نلاحظ أنه عندما بلغ كلا النموذجين أداءً «مناسباً سريرياً» بحسب مؤلفي الدراسة (درجة لا تقل عن 0.80)، كان مكسب النموذج المركزي النمطي ضئيلاً: غالباً أقل من 1–1.5 نقطة مئوية. في مواقف كثيرة كان هذا يعني «ممتاز مقابل مقبول»، لا «قابل للاستخدام مقابل عديم الفائدة».
لماذا يتفوق التعلّم الموزّع على العمل منفرداً
برزت أقوى إشارة في المراجعة عند مقارنة النماذج الموزّعة بالنماذج المحلية الخالصة. عبر كل المقاييس الرئيسية—الدقة، AUROC، مقياس F1، الحساسية، النوعية، وخاصة الدقة الإيجابية—تفوقت الطرق الموزعة تقريباً دائماً، وغالباً بفارق واسع. في الاختبارات المباشرة، تفوق التعلم الموزع على النماذج المحلية في أكثر من 80% من المقارنات للمقاييس الأساسية مثل الدقة والدقة الإيجابية وAUROC. في كثير من الحالات فشلت النماذج المحلية في الوصول إلى عتبة 0.80 للاستخدام السريري، بينما تجاوز النموذج الموزّع المقابلها هذه العتبة بسهولة، محققاً تحسناً في الحساسية يصل إلى 27 نقطة مئوية. يعزو المؤلفون ذلك إلى خبرة أوسع تكتسبها النماذج متعددة المواقع: من خلال «رؤيتها» لأنماط من مستشفيات عديدة، تصبح أقل خضوعاً لتحيّزات خاصة بمعدات أو سياسات سجلّات مستشفى معين وأكثر قدرة على التقاط علامات المرض التي تعمم فعلاً.
موازنة الأداء والخصوصية والقابلية العملية
تخلص المراجعة إلى أن التعلّم المركزي يظل المعيار الذهبي عندما تسمح قواعد الخصوصية واللوجستيات بدمج البيانات وعندما يكون كل جزء من نقطة مئوية في الأداء مهماً، كما في الأمراض النادرة جداً. ومع ذلك، يقدم التعلم الموزّع بديلاً قوياً ومقبولاً سريرياً في الحالات التي تقيّد فيها قوانين مثل النظام العام لحماية البيانات (GDPR) وقانون الذكاء الاصطناعي في الاتحاد الأوروبي مشاركة البيانات، أو عندما تمنع السياسات المؤسسية ذلك. بالمقارنة مع الاحتفاظ بالنماذج محلياً فقط، توفر الأساليب الموزعة مكاسب كبيرة في كل من الدقة والموثوقية مع إبقاء البيانات داخل جدران المستشفى. ويجادل المؤلفون بأن الأعمال المستقبلية يجب أن تتضمن تقارير أوضح عن تقنيات الخصوصية وتكاليف الحوسبة، حتى تتمكن أنظمة الصحة من اتخاذ قرارات مستنيرة حول متى تستحق مقايضات الأداء الطفيفة الفوائد الكبيرة في الخصوصية والتعاون.
الاستشهاد: Diniz, J.M., Vasconcelos, H., Rb-Silva, R. et al. Comparing decentralized machine learning and AI clinical models to local and centralized alternatives: a systematic review. npj Digit. Med. 9, 174 (2026). https://doi.org/10.1038/s41746-025-02329-z
الكلمات المفتاحية: التعلم الفدرالي, الذكاء الاصطناعي في الرعاية الصحية, خصوصية البيانات الطبية, التعلم الآلي الموزع, نماذج التنبؤ السريرية