Clear Sky Science · ar
التنبؤ والنحو والتأصيل الدلالي في الدماغ ونماذج اللغة الكبيرة
كيف يخمن دماغك الكلمة التالية
عندما تستمع إلى قصة، يبدو أحيانًا أن متابعة السرد سهلة وبديهية—لكن تحت السطح، يظل دماغك يخمن باستمرار ما الذي سيأتي بعده. في الوقت نفسه، تسرّ الأنظمة الحديثة للذكاء الاصطناعي مثل نماذج اللغة الكبيرة الكلمات القادمة لتوليد نص متدفق. تجمع هذه الدراسة بين هذين العالمين، سائلةً كيف يتوقع الدماغ البشري الكلمات في الزمن الحقيقي وكيف تقارن هذه العمليات بطريقة عمل نموذج ذكاء اصطناعي متقدّم.
الاستماع إلى قصة في المختبر
لدراسة فهم اللغة الطبيعية، تجاوز الباحثون قوائم الكلمات المصطنعة أو الجمل القصيرة المعزولة. استمع 29 متطوّعًا شابًا إلى حوالي 50 دقيقة من كتاب صوتي خيالي علمي بالألمانية بينما سُجل نشاط أدمغتهم. استُخدمت تقنيتان مكمّلَتان في الوقت نفسه: تسجيل كهربية الدماغ (EEG)، الذي يقيس تغيرات جهد صغيرة على فروة الرأس، وتسجيل المجال المغناطيسي للدماغ (MEG)، الذي يكتشف الحقول المغناطيسية الناتجة عن نشاط الدماغ. معًا، تسمح هاتان الطريقتان بتتبّع استجابة الدماغ لكل كلمة بدقة ميلي ثانية بينما يتابع الأشخاص سردًا مستمرًا.
متابعة أنواع مختلفة من الكلمات
قُسّم الكتاب الصوتي تلقائيًا إلى كلمات منفردة ووُسمت بحسب النوع النحوي: أسماء (مثل «كوكب»)، أفعال (مثل «جرى»)، صفات (مثل «مظلم»)، وأسماء علم. لكل كلمة في القصة، اقتطع العلماء نافذة زمنية قصيرة من إشارات EEG وMEG قبل وبعد نطق الكلمة ثم وسّطوا هذه المقاطع داخل كل فئة كلمات. كُشفت بذلك «بصمات» كهربائية ومغناطيسية موثوقة لأنواع الكلمات المختلفة، بما في ذلك مكونات معروفة مرتبطة بالمعنى وتركيب الجملة. ومن المهم أن الفريق وجد أن النشاط المتعلق بالأسماء بدأ يتراكم حتى قبل بدء الكلمة فعليًا، ما يشير إلى أن الدماغ كان أكثر استعدادًا لهذا النوع من الكلمات في السياق.
حيث يلتقي المعنى بالحركة
لمعرفة أين نشأت هذه الإشارات في الدماغ، استخدم الباحثون نماذج حسابية لتقدير المصادر المحتملة لأنماط MEG وEEG داخل الرأس. لم تُنَشّط الأسماء مناطق اللغة الكلاسيكية في الفصوص الصدغية فقط؛ بل أظهرت أيضًا مشاركة مناطق تتوافق مع أجزاء من النظام الحسي-حركي، بالقرب من مناطق متورطة في الحركة والإحساس الجسدي. بالمقابل، أظهرت الأفعال نمطًا مختلفًا وأكثر محدودية. يدعم هذا فكرة اللغة «المتجسّدة»، التي ترى أن فهم كلمة—وخاصة اسم ملموس—يعيد جزئيًا تنشيط شبكات مرتبطة بالإدراك والفعل، مؤسسًا المعنى على تجارب حسية سابقة بدلاً من قواعد مجردة فقط.
مقارنة الأدمغة ونماذج اللغة الكبيرة
انتقل الفريق بعد ذلك إلى نموذج Llama 3.2 من شركة Meta ليكون نقطة مرجعية حسابية. أولًا، اختبروا «التنبؤ الدلالي» بإدخال السياق السابق من الكتاب الصوتي إلى النموذج وسؤالهم عن احتمالية الكلمة الحقيقية التالية حسب تقدير النموذج. تبين أن الأسماء كانت أسهل ما يمكن للنموذج التنبؤ به، ما يتوافق مع دورها المركزي في بناء السرد. بعد ذلك، استكشف الباحثون «التنبؤ النحوي» بفحص التنشيطات الداخلية، أو التضمينات، داخل Llama. حتى دون تدريب إضافي، جمّعت طبقات النموذج الداخلية الكلمات تلقائيًا بحسب نوع الكلمة النحوي الذي سيأتي بعدها، وغالبًا ما كان بإمكان شبكة مراقبة بسيطة تحديد فئة الكلمة التالية. عبر الطبقات، أصبحت البنية الداخلية للأسماء والأسماء العلمية أكثر تمايزًا، مما يعكس التمايز المتزايد للأدوار الذي لوحظ في أنماط نشاط الدماغ.
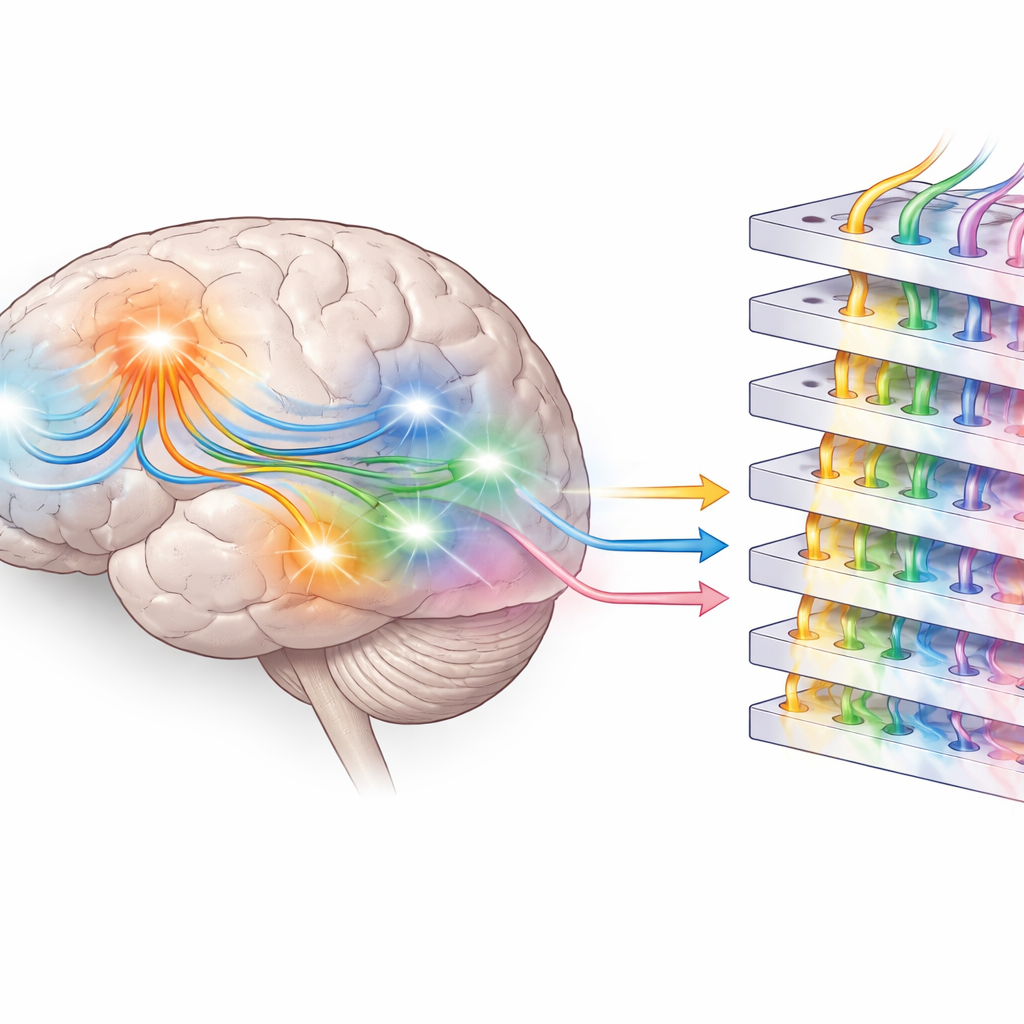
نوعان من الجاهزية للكلمات
معًا، تشير النتائج إلى أن الدماغ يستعد للغة القادمة على مستوىَين على الأقل. في المناطق الصدغية، يبدو أن النشاط قبل بدء الكلمة يعكس نوعًا من الجاهزية النحوية أو «التركيبية»—معرفة حول أماكن ظهور أنواع كلمات معينة في الجملة. في المناطق الجبهية والنظام الحسي-الحركي، تبدو أنماط الاستعداد حاملةً توقّعات دلالية أغنى مرتبطة بالمعنى والتجربة، لا سيما للأسماء والأسماء العلمية. تطور نماذج اللغة الكبيرة، المدربة فقط على توقع الكلمة التالية، هياكل داخلية متعددة الطبقات تعكس جزئيًا هذه الفروق، لكنها تفتقر إلى التأصيل المباشر في العالم المادي. من خلال الجمع بين تسجيلات دماغية فائقة السرعة وتحليلات لذكاء اصطناعي متقدم، تساعد هذه الدراسة في توضيح كيف يتوقع البشر الكلمات أثناء الاستماع اليومي وإلى أي مدى اقتربت الآلات اليوم من محاكاة هذه الخاصية الأساسية لفهم اللغة البشرية.
الاستشهاد: Kölbl, N., Rampp, S., Kaltenhäuser, M. et al. Prediction, syntax and semantic grounding in the brain and large language models. Sci Rep 16, 8728 (2026). https://doi.org/10.1038/s41598-026-41532-0
الكلمات المفتاحية: تنبؤ اللغة, الدماغ والذكاء الاصطناعي, نماذج اللغة الكبيرة, التأصيل الدلالي, EEG MEG اللغة