Clear Sky Science · ar
نظام استرجاع متعدد المستخدمين يحافظ على الخصوصية للذكاء الاصطناعي متعدد الوسائط
لماذا تهمنا خصوصية عمليات البحث الذكية
يعتمد الكثير منا اليوم على ذكاء اصطناعي مستضاف في السحابة لفرز صورنا ومستنداتنا وحتى صور الأشعة الطبية. هذه الأنظمة قوية لأنها تفهم الصور والكلمات معاً، لكنها تثير سؤالاً صعباً: كيف نتمتع بهذه الراحة دون تسليم معنى أكثر بياناتنا حساسية إلى خوادم بعيدة؟ يقدم هذا البحث نظام PMIRS، وهو نظام جديد يهدف إلى تمكين العديد من المستخدمين من البحث عبر مجموعات مختلطة من الصور والنصوص مع إبقاء معلوماتهم مخفية عن آلات السحابة التي تشغل هذه العمليات.
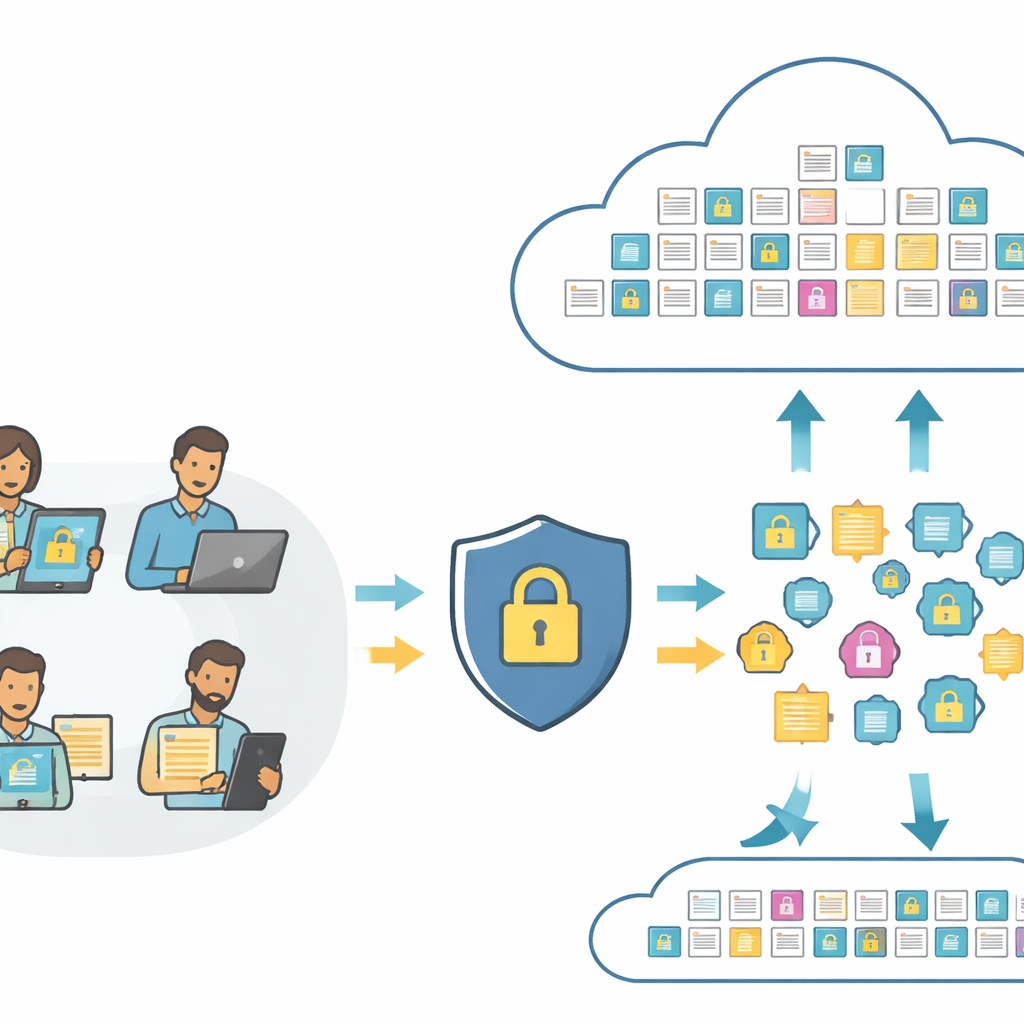
البحث في الصور والنصوص من دون كشف معناها
في صميم أدوات البحث الحديثة توجد «التعابير الضمنية» — بصمات رقمية تلتقط محتوى صورة أو جملة بحيث يمكن للحاسوب مقارنتها. ترسل الأنظمة التقليدية هذه البصمات مباشرة إلى السحابة حيث يمكن تحليلها أو حتى إساءة استخدامها. يعيد PMIRS ترتيب هذا المسار. يرسِل المستخدمون أولاً صورهم ونصوصهم الخام إلى طبقة محلية، التي تحولها إلى بصمات باستخدام نموذج صغير للرؤية واللغة. قبل أن يغادر أي شيء جهة المستخدم، تُشوَّه هذه البصمات بطريقة مُتحكَّم بها ثم تُشفّر. لا ترى السحابة سوى هذه البصمات المحمية ونسخاً مشفرة تماماً من البيانات المخزنة، ومع ذلك يمكنها تنفيذ المطابقة وإرجاع أفضل النتائج.
التعلم من عدة مستخدمين دون تجميع بياناتهم
عادةً يتطلب تدريب نموذج جيد للصورة والنص جمع كميات هائلة من الأمثلة المصنفة في مكان واحد — وهو خطر خصوصية واضح. بدلاً من ذلك يستخدم PMIRS التعلم الفيدرالي. في هذا الإعداد يُرسَل النموذج الأساسي، المستمد من بنية CLIP المعروفة، إلى العديد من الأجهزة. يدرب كل جهاز النموذج محلياً على أزواج الصورة-النص الخاصة به ويُرسِل فقط أوزان النموذج المُحدّثة، والتي تكون مشفرة أيضاً. يجري خادم مركزي متوسط هذه التحديثات لتحسين نموذج مشترك دون أن يرى أي صور أو أوصاف خام لمستخدم. كما يقلّص المؤلفون النموذج ويضبطونه عبر عملية تقطير مرحلية تُقصي الأجزاء غير الضرورية مع الحفاظ على الدقة، مما يجعل النظام خفيف الوزن بما يكفي للتشغيل العملي.
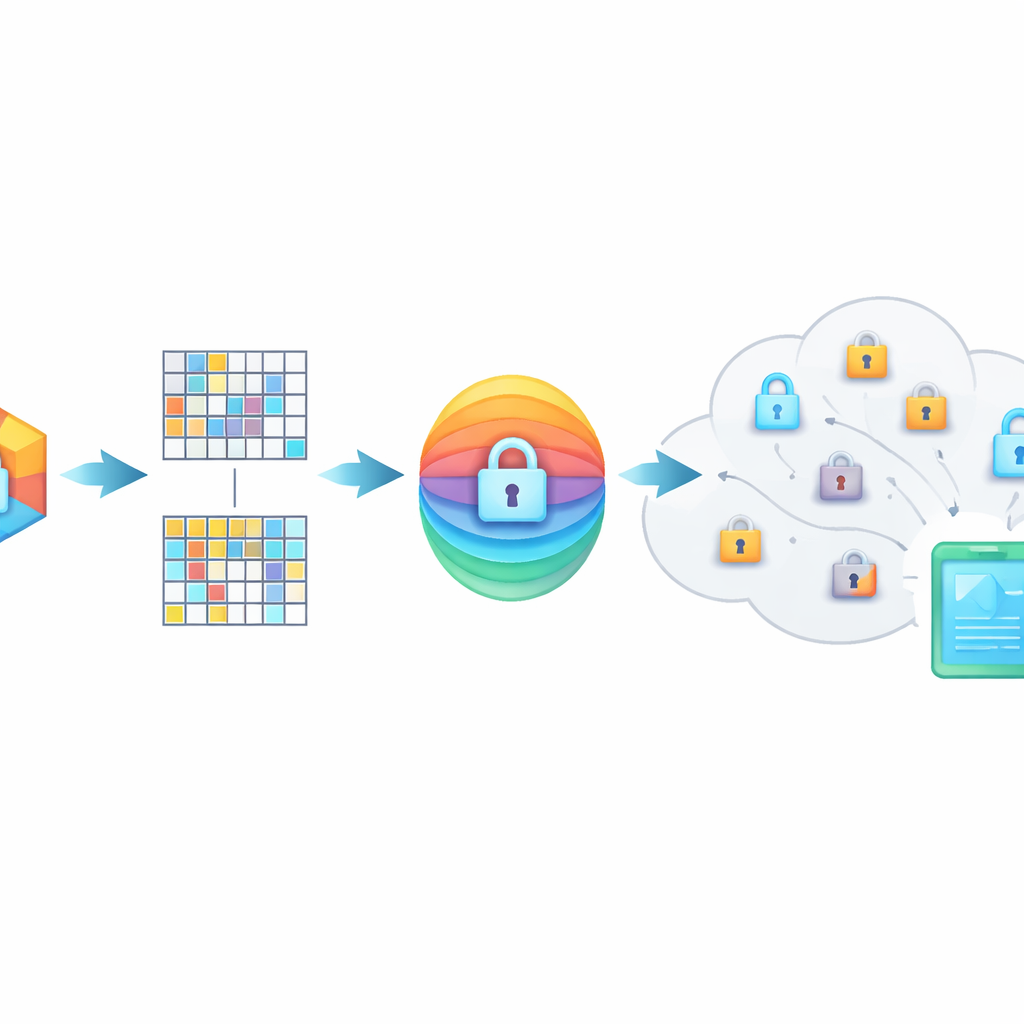
إخفاء المعنى داخل بصمات مشوشة
يحمي PMIRS الاستفسارات بدرع ذو طبقتين. أولاً، تُقسَم كل بصمة إلى كتل ويُحوَّل كل كتلة بواسطة مصفوفة سرية، بالإضافة إلى نمط ضوضاء مُصمَّم بعناية. تُخفي هذه التشويشات البنية الأصلية للبيانات لكنها مُهيَّأة بحيث عندما يتحول عنصران مرتبطان، تبقى درجة تشابههما ثابتة. ثانياً، يُشفَّر الناتج باستخدام طريقة AES المألوفة، بمفاتيح لا تُرسل أبداً بشكل مكشوف عبر الشبكة. وفي الحالات التي يحتاج فيها شخص للبحث في بيانات شخص آخر — مثل طبيب يستشير أخصائياً — يستخدم النظام بروتوكول تبادل المفاتيح Diffie–Hellman حتى يتفقوا على أسرار مشتركة من دون كشفها للمستنصتين.
مدى كفاءة النظام عملياً
لاختبار ما إذا كانت هذه الحمايات تكلف ثمناً باهظاً، بنى الباحثون معيار تقييم يقرن صوراً يومية بعبارات قصيرة باللغة الطبيعية — أقرب إلى كيفية وصف الناس للأشياء فعلياً مقارنةً بتسميات كلمة مفردة. قارَنوا PMIRS مع بحث قائم على CLIP القياسي عبر ثلاث سمات: المشاهد الطبيعية، والأشياء المصنعة، والأنشطة أو المناظِر. عبر أحجام مستودعات متعددة، وجد PMIRS توازناً أفضل باستمرار بين القبض على كل النتائج الصحيحة (الاستدعاء) وتفادي المطابقات الخاطئة (الدقة)، مما أدى إلى متوسط مقياس F1 — مقياس دقة مجمع — أعلى بنحو 7.7% من الأساس. والأهم أن أزمنة الاستجابة بقيت دون نحو 180 مللي ثانية، سريعة بما يكفي للاستخدام التفاعلي، وغالباً ما كانت أسرع قليلاً من الأساس غير المؤمَّن رغم خطوات الحماية الإضافية.
ماذا يعني هذا لمستخدمي الحياة اليومية
ببساطة، يُظهر PMIRS أنه من الممكن بناء أدوات بحث سحابية تفهم الصور والنصوص جيداً، تخدم العديد من المستخدمين في آن واحد، وتظل في الوقت نفسه تحول دون وصول مزود السحابة إلى معنى بيانات كل شخص. عبر الجمع بين التدريب المحلي، وتشويش البصمات بذكاء، والتشفير القوي، وتبادل المفاتيح الآمن، يقدم النظام خط أنابيب شامل يحفظ الخصوصية بدلاً من حماية مرحلة واحدة فقط. ومع أنه لا يزال لا يغطي كل هجوم ممكن ويحتاج مزيداً من التحسين والاختبارات الواقعية، فإن العمل يشير إلى خدمات مستقبلية — مثل البحث في الصور الطبية، وروبوتات دعم العملاء، أو أرشيفات المؤسسات — حيث يمكن للناس التمتع ببحث ذكاء اصطناعي متعدد الوسائط مع قلق أقل من كشف أو إساءة استخدام محتواهم الشخصي.
الاستشهاد: Gao, Y., Luo, W., Wang, C. et al. A privacy-preserving multi-user retrieval system for multimodal artificial intelligence. Sci Rep 16, 10348 (2026). https://doi.org/10.1038/s41598-026-40734-w
الكلمات المفتاحية: الذكاء الاصطناعي المحمي بالخصوصية, استرجاع متعدد الوسائط, التعلم الفيدرالي, البحث المشفر, الحوسبة السحابية الآمنة