Clear Sky Science · ar
نسبة المصدر الكاميرا باستخدام شبكة عصبية تلافيفية قابلة للتفسير قائمة على قواعد
لماذا صورك قد تكشف أكثر مما تعتقد
كل صورة تلتقطها تحمل دلائل خفية عن الكاميرا التي صورتها. بالنسبة للمحققين الرقميين، يمكن أن تساعد هذه الدلائل في التأكد من أصالة الصورة أو تتبع الجهاز الذي جاءت منه أو ربط صور بمشاهد جرائم مختلفة. اليوم، تستطيع أدوات الذكاء الاصطناعي القوية اكتشاف هذه الأنماط أفضل من البشر—لكنها غالبًا ما تعمل كـ«صناديق سوداء» غامضة. يقدم هذا البحث طريقة لفتح تلك الصندوق: منهج قائم على قواعد يشرح كيف يقرر نموذج التعلم العميق أي كاميرا التقطت الصورة، بصيغة يمكن للمُحقق البشري فهمها والثقة بها.
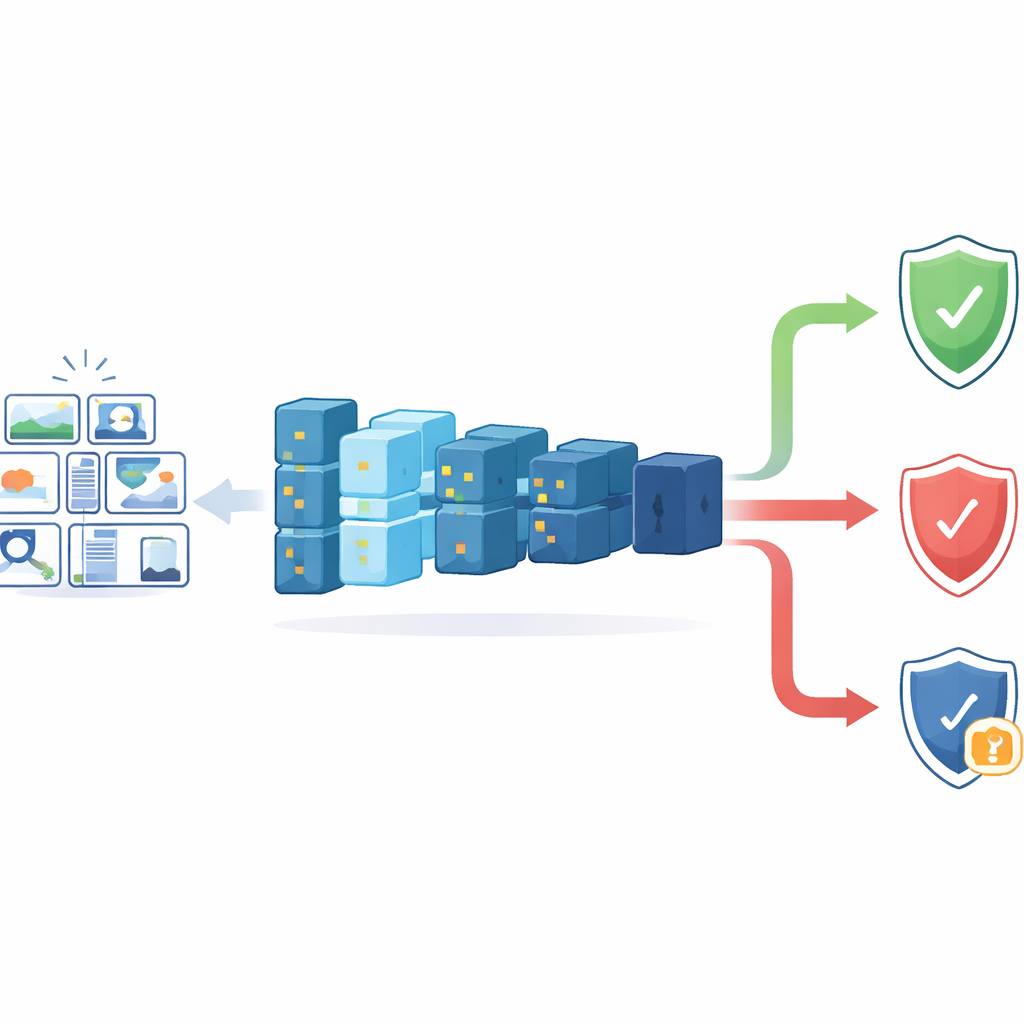
تحدي الثقة في أدوات الطب الشرعي الذكية
على الطب الشرعي الرقمي الحديث أن ينخل كميات هائلة من البيانات—من الهواتف الذكية ونسخ السحابة ووسائل التواصل الاجتماعي—بما يفوق ما يستطيع المحللون البشر فحصه يدويًا. يمكن لأنظمة التعلم العميق أن تحدد بسرعة الصور أو تشير إلى المهم منها، لكن آلياتها الداخلية مشهورة بالغموض. في بيئات حساسة مثل قاعات المحكمة، لا يكفي قول «الشبكة العصبية ترى ذلك». أدوات التفسير الحالية عادةً ما تُبرِز مناطق في الصورة وجدها النموذج مهمة، وهو ما يفيد مهامًا مثل التعرف على الوجوه أو الأشياء. ومع ذلك، في تحديد مصدر الكاميرا، الإشارة الحاسمة ليست سمة مرئية بل بصمة حساسية خفيفة—أنماط ضوضاء دقيقة لا يراها البشر. نتيجة لذلك، لا توضح أدوات التفسير البصرية الحالية بجلاء لماذا يعتقد النموذج أن الصورة من كاميرا معينة، ولا تساعد الفاحصين على اكتشاف متى يخطئ النموذج.
طريقة جديدة لمراقبة تفكير الشبكة العصبية
يقدم المؤلفون xDFAI، إطارًا مصممًا خصيصًا للطب الشرعي الرقمي يشرح كيف تتوصل الشبكة العصبية التلافيفية (CNN) إلى قراراتها دون تغيير النموذج الأصلي. بدلاً من اعتبار الشبكة صندوقًا واحدًا معتمًا، ينظر xDFAI داخلها طبقة بطبقة. لكل طبقة ولكل فئة كاميرا، يحدد مجموعة من الأنماط الداخلية المتكررة، تُسمى «آثار»، تتوهج باستمرار عندما يعتقد النموذج أن الصورة تخص تلك الكاميرا. تُستخرج هذه الآثار من نموذج مُدَرَّب باستخدام طرق إسناد موجودة، ثم تُفلتر للاحتفاظ فقط بالأنماط التي تظهر بشكل موثوق عبر العديد من صور التدريب. تشكل هذه الآثار معًا خريطة منظمة لكيفية تطور دلائل هوية الكاميرا مع مرور الصورة خلال الشبكة.
ترك الطبقات تصوّت وتحويل الأصوات إلى قواعد
بمجرد معرفة الآثار، يستخدم xDFAI هذه الآثار لفحص صور جديدة غير مرئية سابقًا. بالنسبة لصورة اختبار معينة، يقيس الإطار مدى تشابه التنشيطات الداخلية للصورة مع الآثار المخزنة لكل كاميرا في كل طبقة. كل طبقة تصوّت فعليًا لنماذج الكاميرات التي تتطابق آثارها معها على أقرب وجه. ثم يلخص «التصويت بالأغلبية» عبر الطبقات مدى دعم الشبكة ككل لكل كاميرا مرشحة. والأهم من ذلك، أن المؤلفين لا يستخدمون هذا التصويت ليحل محل توقُّع النموذج؛ بل يستخدمونه كتحقق. تقارن قواعد منطقية بسيطة تصويت الأغلبية مع التوقُّع الأصلي: إذا حصلت الكاميرا المتوقعة أيضًا على دعم قوي من العديد من الطبقات، تُؤكَّد القرار؛ أما إذا تَشتتَت الأصوات أو فضَّلت كاميرا مختلفة، فيُعلَم السلوك على أنه شاذ ويُعرض للمُحقق كخطأ محتمل للنموذج.
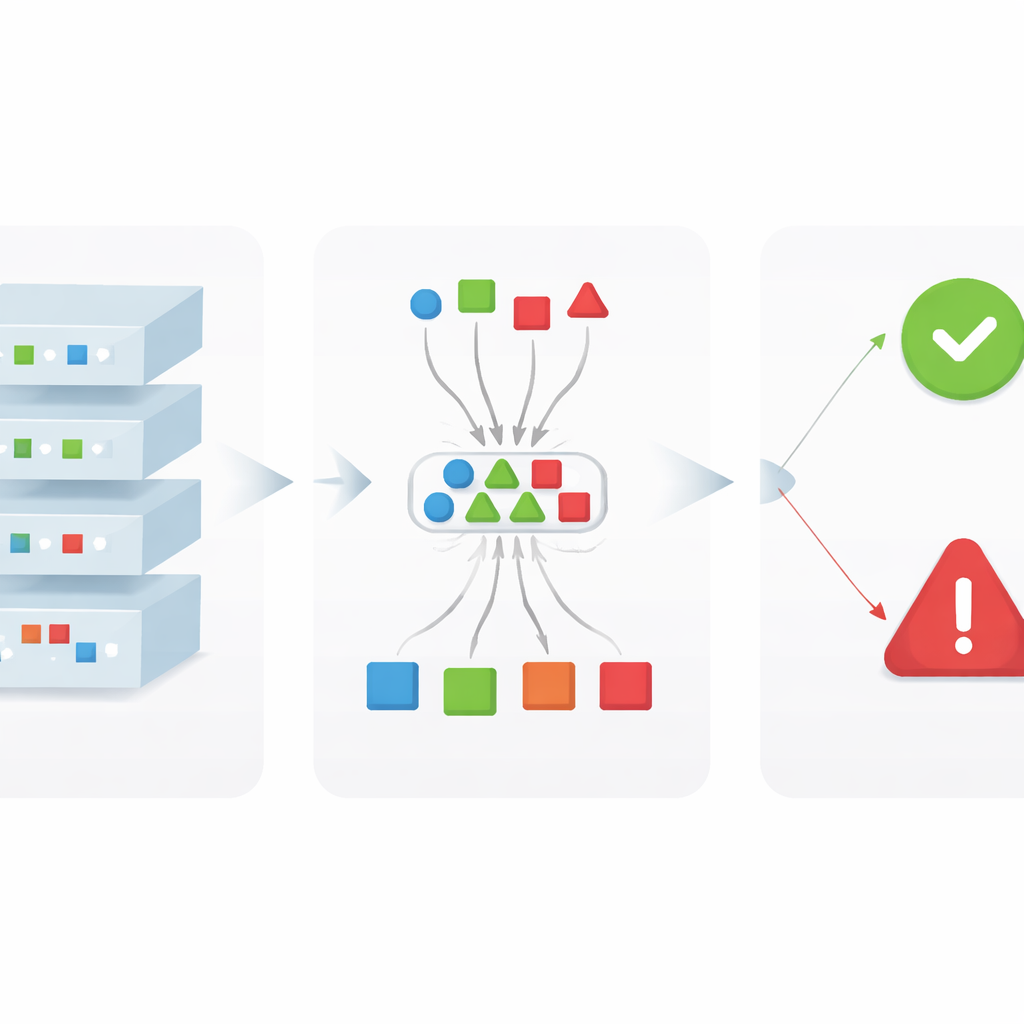
تجريب الإطار
لإظهار عمل xDFAI، يطبّقه المؤلفون على شبكة CNN ذات سبع طبقات مدرَّبة لتحديد أي من 27 نموذج كاميرا التقط الصورة، باستخدام مجموعة بيانات جنائية معروفة. أداء شبكة الأساس وحدها جيد جدًا بالفعل، حيث تصنّف حوالي 97% من صور الاختبار بشكل صحيح. عندما تُطبَّق قواعد xDFAI فوقها، يعلم النظام تلقائيًا 27 من أصل 37 توقُّعًا خاطئًا باعتبارها مريبة. تلك الحالات المعلمة لا تُحتسب بعد الآن كمنتجات تحديد واثقة، مما يرفع الدقة—نسبة القرارات المقبولة التي هي صحيحة بالفعل—من 97.33% إلى 99.2%، مع تقليل طفيف فقط في الدقة الكلية. لعمل الطب الشرعي، حيث قد يترتب على نسبة خطأ واحدة عواقب وخيمة، فإن هذا المقايضة مرغوب فيها للغاية: إنّ عدد الإنذارات الكاذبة بين الاستنتاجات التي يختار المحللون الثقة بها يقل.
ماذا يعني هذا للتحقيقات الواقعية
يبين هذا العمل أنه من الممكن الاحتفاظ بالقوة الكاملة لنموذج تعلم عميق حديث مع إضافة تفسيرات صديقة للإنسان تحترم قواعد سلامة العمل الجنائي—من دون إعادة تدريب أو العبث بالنموذج الأصلي أو الاعتماد فقط على خرائط الحرارة المبهمة. من خلال الكشف عن آثار داخلية مستقرة، وتجميعها عبر آلية تصويت شفافة، والتعبير عن النتيجة كقواعد بسيطة، يمنح xDFAI الفاحصين وسيلة لتأكيد أو التشكيك في نسب الكاميرا التي يولدها الذكاء الاصطناعي. وعلى الرغم من أن الدراسة تركز على تحديد مصدر الكاميرا، يمكن توسيع نفس الأفكار إلى مهام نسب جنائية أخرى. على المدى الطويل، قد تساعد نهج مماثلة في سد الفجوة بين أنظمة الذكاء الاصطناعي عالية الدقة ومستوى الشفافية والموثوقية المطلوب في المحاكم والممارسات التحقيقية.
الاستشهاد: Nayerifard, T., Amintoosi, H. & Ghaemi Bafghi, A. Source camera attribution using a rule-based explainable convolutional neural network. Sci Rep 16, 9137 (2026). https://doi.org/10.1038/s41598-026-40387-9
الكلمات المفتاحية: الطب الشرعي الرقمي, الذكاء الاصطناعي القابل للتفسير, تحديد الكاميرا, الشبكات العصبية التلافيفية, الطب الشرعي للصورة