Clear Sky Science · ar
KM-DBSCAN: إطار محسّن لاكتشاف الحواف قائم على الكثافة والمراكز للحد من البيانات نحو ذكاء اصطناعي أخضر
لماذا قد يجعل تصغير نماذج الذكاء الاصطناعي منها أكثر صداقة للبيئة
للذكاء الاصطناعي تكلفة خفية: الكهرباء. تدريب نماذج تعلم الآلة الحديثة غالباً ما يتطلب معالجة ملايين نقاط البيانات على أجهزة تستهلك طاقة عالية، ما يؤدي بدوره إلى انبعاثات كربونية. تقدم هذه الورقة إطار KM-DBSCAN، أسلوبًا جديدًا لتقليص مجموعات البيانات قبل التدريب دون فقدان المعلومات التي تحتاجها النماذج فعلًا. من خلال الاحتفاظ فقط بأكثر نقاط البيانات إفادةً، يسرِّع الأسلوب التعلم، ويقلل استهلاك الطاقة، ويظل يحقق تنبؤات دقيقة لمهام تتراوح من تمييز الأرقام المكتوبة بخط اليد إلى الكشف المبكر عن سرطان الجلد.
البيانات الكثيرة، الطاقة الكثير
لسنوات كان الاعتقاد السائد في مجال الذكاء الاصطناعي أن المزيد من البيانات يؤدي تقريبًا دائمًا إلى نماذج أفضل. بينما قد يحسن ذلك الدقة، فإنه يعني أيضًا أوقات تدريب أطول، وأجهزة أكبر، وفواتير كهرباء أعلى. بدأ الباحثون يميزون بين «الذكاء الأحمر»، الذي يطارد الدقة مهما كلف الثمن، و«الذكاء الأخضر»، الذي يحاول موازنة الأداء مع الأثر البيئي. إحدى الطرق الواعدة لتحقيق ذكاء اصطناعي أكثر استدامة هي تقليل البيانات: بدلاً من تزويد النموذج بكل عينة متاحة، يتم تحديد مجموعة أصغر بكثير من الحالات التي لا تزال تعرف المشكلة جيدًا، وبالأخص حالات الحدود الصعبة التي تحدد قرارات المصنف.
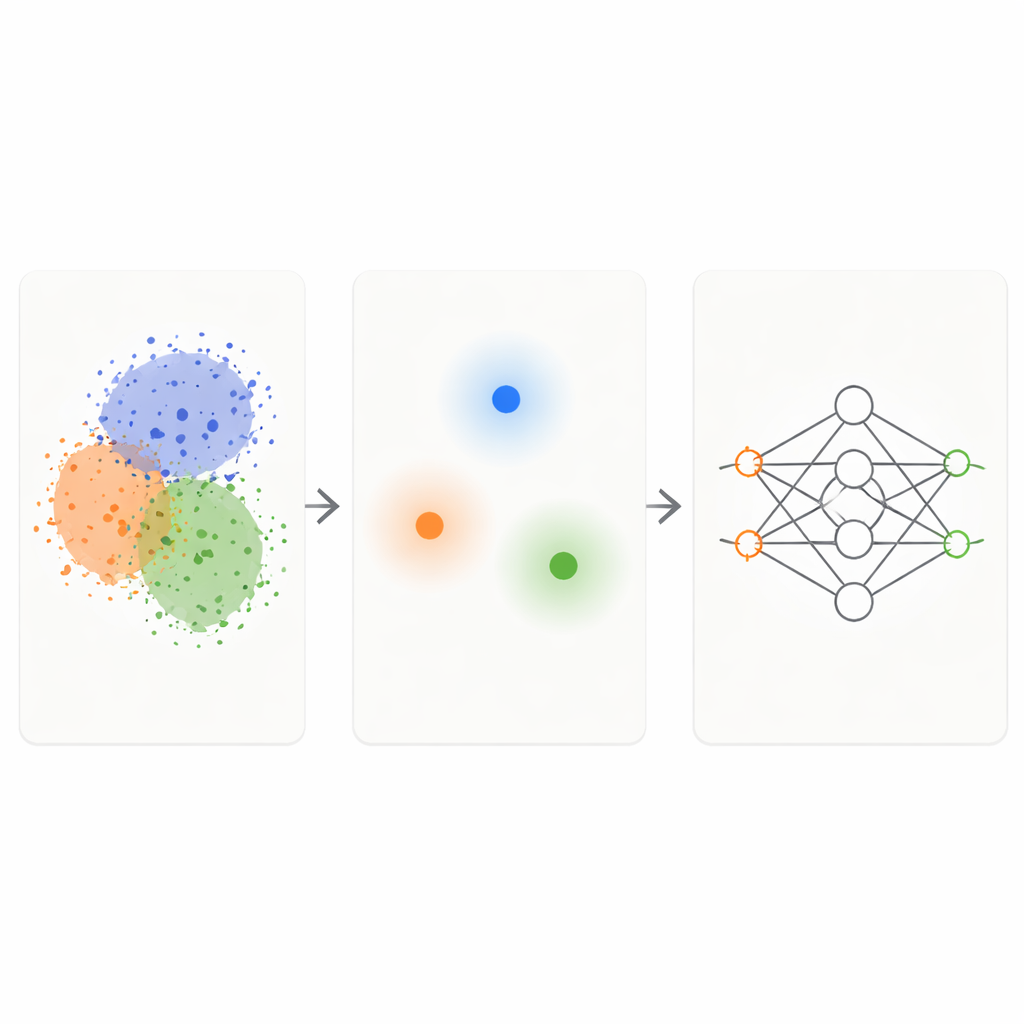
دمج فكرتين بسيطتين في مرشح ذكي واحد
يجمع إطار KM-DBSCAN بين تقنيتي تجميع معروفتين ليعمل كمرشح ذكي للبيانات الخام. أولًا، طريقة سريعة تُسمى K-Means تجمع النقاط في عُناقيد مدمجة وتستبدل كل مجموعة بمركز ممثل، أو متوسط. هذا يقلص المشكلة من آلاف أو ملايين النقاط إلى بضع مئات من النماذج الممثلة. بعد ذلك، تُطبق طريقة قائمة على الكثافة (DBSCAN) على تلك المراكز لتكتشف أي المناطق تقع عند حدود العناقيد وأيها داخليات كثيفة متجانسة أو ضوضاء معزولة. بالعمل على مستوى المراكز، تصبح DBSCAN أسرع بكثير وأقل حساسية لاختيارات المعاملات الدقيقة مقارنة بتطبيقها مباشرة على جميع نقاط البيانات.

الاحتفاظ فقط بالحالات الصعبة والمفيدة
بمجرد أن يحدد KM-DBSCAN أماكن تماس أو تداخل المجموعات المختلفة، يحتفظ فقط بنقاط البيانات القريبة من هذه الحدود ويتخلص من نقاط الداخل العميق والقيعان الواضحة. نقاط الداخل متكررة إلى حدٍ كبير: تبدو متشابهة وتبعث للنموذج نفس الرسالة حول فئتها. نقاط الحدود، بالمقابل، تخبر النموذج تحديدًا أين تنتهي فئة وتبدأ أخرى. على مجموعات بيانات اصطناعية بسيطة، يعيد هذا الأسلوب نفس حدود القرار التي يتعلمها المصنف من البيانات الكاملة، حتى عند إزالة معظم النقاط. على مجموعات بيانات واقعية مثل Banana وUSPS للأرقام، ومجموعة بيانات دخل البالغين، وبيانات حوادث المركبات، وأنواع الفاصوليا الجافة، وصور الميلانوما الجلدية، تحافظ المجموعات المختزلة على البنية الأساسية للمشكلة بينما تصبح أصغر بحجم مرتبة عددية.
السرعة، وخفض الكربون، والتطبيقات الحقيقية
اختبر المؤلفون KM-DBSCAN كمقدمة لعدة نماذج شائعة، بما في ذلك آلات الدعم الناقلة، والشبكات متعددة الطبقات، والشبكات العصبية الالتفافية. في كثير من الحالات كان التدريب على البيانات المختزلة أسرع بعشرات إلى آلاف المرات مع الحفاظ على دقة قريبة جدًا—وأحيانًا حتى تحسنت قليلًا. على سبيل المثال، في تمييز الأرقام المكتوبة بخط اليد قلصت الطريقة مجموعة التدريب إلى 1.4% فقط من حجمها الأصلي وما تزال ترفع الدقة قليلًا، بينما جعلت التدريب أسرع 284 مرة. في مهمة توقع الدخل ذات الفئات غير المتساوية، حققت تسريعًا بمقدار 6907 مرة باستخدام حوالي 3% من البيانات مع فقدان ضئيل في الدقة. في تجربة كشف الميلانوما، وصلت شبكة عصبية عميقة إلى دقة تزيد عن 90% أثناء التدريب على أقل من ثلث مجموعة صور الجلد الأصلية، مع تقليل انبعاثات الكربون بأكثر من 70%.
ماذا يعني هذا لذكاء اصطناعي يومي
بالنسبة لغير المختصين، الرسالة الأساسية هي أن الاختيار الأذكى قد يتفوق على الكمية الصرفة. يبيّن KM-DBSCAN أن اختيار الأمثلة التي يراها النموذج بعناية—مع التركيز على حالات الحدود الأكثر إفادة—يمكن أن يقلص زمن الحوسبة واستهلاك الطاقة مع الحفاظ على موثوقية التنبؤات. ينسجم هذا النهج بسلاسة مع الدفع الأوسع نحو الذكاء الاصطناعي الأخضر، حيث تكتسب جودة البيانات والتصميم المدروس لخطوط أنابيب التدريب أهمية مساوية لحجم النموذج الخام. إذا تم تبنيه على نطاق واسع، يمكن لمثل هذا الترشيح الواعي بالبيانات أن يجعل كل شيء من تحليل الصور الطبية إلى أنظمة السلامة المرورية أكثر استدامة، ويجعل أدوات الذكاء القوية في متناول منظمات تفتقر إلى موارد حوسبة هائلة.
الاستشهاد: AboElsaad, M.Y., Farouk, M. & Khater, H.A. KM-DBSCAN: an enhanced density and centroid based border detection framework for data reduction towards green AI. Sci Rep 16, 10349 (2026). https://doi.org/10.1038/s41598-026-40062-z
الكلمات المفتاحية: الذكاء الاصطناعي الأخضر, تقليل البيانات, التجميع (clustering), كفاءة تعلم الآلة, كشف الميلانوما