Clear Sky Science · ar
R-GAT: تصنيف مستندات السرطان باستخدام شبكة متبقية قائمة على الرسم البياني لسيناريوهات البيانات المحدودة
لماذا يهم تصنيف أوراق السرطان
ينشر العلماء يومياً مئات الدراسات الجديدة حول السرطان، من الكشف المبكر إلى الأدوية الواعدة. تظهر معظم هذه الأعمال أولاً كمُلخّصات قصيرة تُعرف بالمستخلصات. لا يستطيع الأطباء والباحثون وصناع السياسات قراءتها كلها، ومع ذلك فإن تفويت ورقة مهمة قد يبطئ التقدم. تتناول هذه الدراسة سؤالاً بسيطاً لكنه قويّ: هل يمكننا بناء نظام حاسوبي سريع وخفيف يفرز تلقائياً مستخلصات الأبحاث المتعلقة بالسرطان حسب نوع السرطان، حتى عندما تتوفر كمية متواضعة فقط من البيانات الموسومة وموارد الحوسبة؟
طريقة أذكى لقراءة أبحاث السرطان
يركز المؤلفون على أربعة أنواع من المستخلصات الموجودة في قاعدة بيانات PubMed: مستخلصات عن سرطان الغدة الدرقية، وسرطان القولون، وسرطان الرئة، ومواضيع طبية حيوية أكثر عمومية. أنشأوا مجموعة مدققة بعناية تضم 1875 مستخلصاً حديثاً، موزعة تقريباً بالتساوي بين هذه المجموعات الأربع. يساعد هذا التوازن على تجنّب التحيز نحو نوع واحد من السرطان. قبل أي نمذجة، نُقّيت النصوص: قُسِّمت الكلمات إلى رموز، فُحِصت الإملاء، دُمجت صيغ الكلمات ذات الصلة، وأُزيلت المصطلحات غير المعلِّمة بالمعلومات. ثم حُوِّلت المستخلصات المنقّحة إلى شكل عددي باستخدام عدة طرائق معيارية حتى يمكن مقارنة أنواع النماذج بشكل عادل.
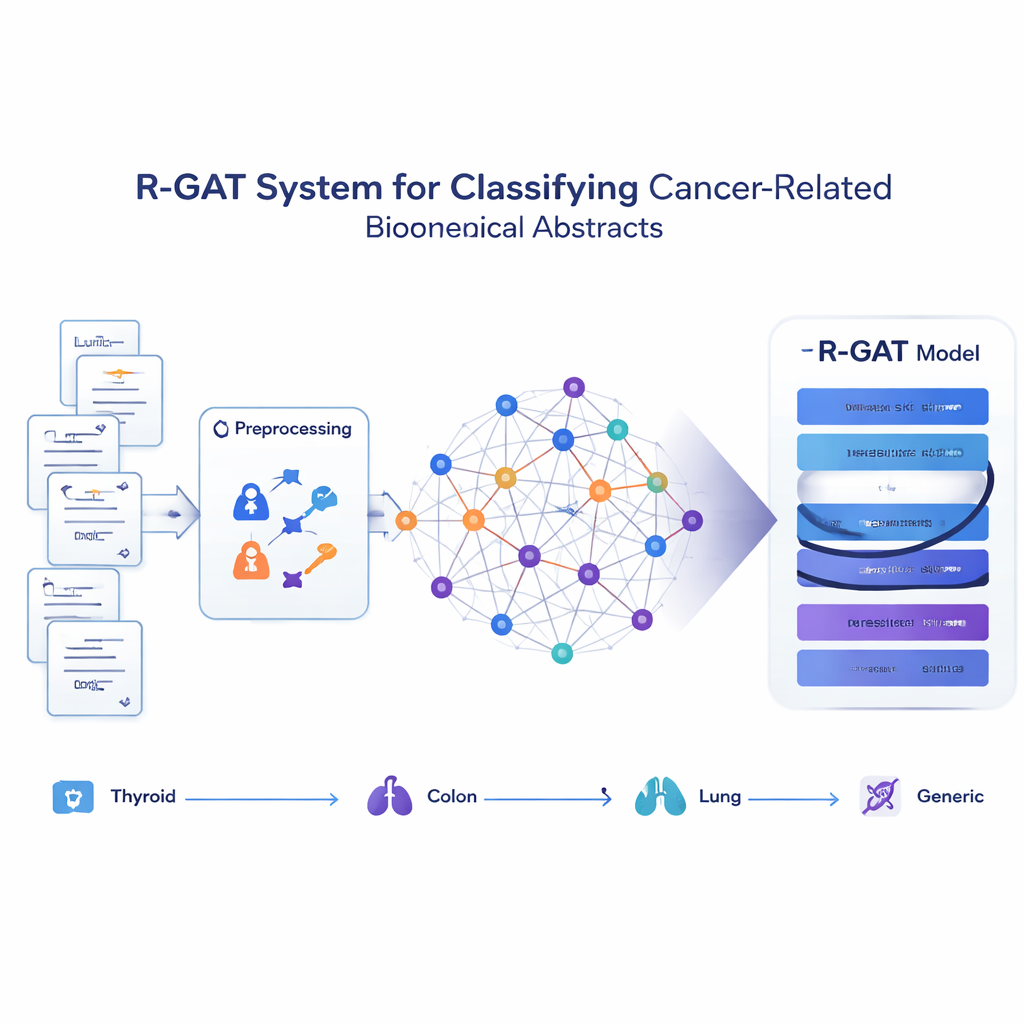
تحويل المقالات إلى شبكة أفكار
بدلاً من التعامل مع كل مستخلص كسلسلة معزولة من الكلمات، ترى الطريقة المقترحة، المسماة R-GAT (شبكة الانتباه البياني المتبقية)، المجموعة بأكملها كشبكة. في هذه الشبكة، كل مستخلص هو عقدة، والروابط تمثل مدى تشابه محتوى مستخلصين. إذا ناقشت ورقتان مواضيع متقاربة، تكون العلاقة بينهما قوية؛ وإذا لم تكن كذلك، فالعلاقة ضعيفة أو غائبة. يتيح ذلك للنموذج النظر إلى المستخلص في سياق جيرانه، محاكياً كيف قد يفهم القارئ البشري دراسة أفضل عندما يعرف ما تقوله الأعمال ذات الصلة.
كيف يتعلم النموذج الجديد من الجيران
يبني R-GAT على فكرتين أساسيتين من الذكاء الاصطناعي الحديث: الانتباه والروابط المتبقية. يتيح الانتباه للنموذج التركيز أكثر على المستخلصات المجاورة الأكثر صلة في الشبكة، بدلاً من معاملة جميع الجيران على قدم المساواة. تبحث عدة "رؤوس" انتباه عن أنماط مختلفة في الوقت نفسه. تعمل الروابط المتبقية كاختصارات تمرر المعلومات عبر طبقات الشبكة الأعمق، مما يساعد النموذج على تجنّب فقدان الإشارات المهمة أثناء التعلم. بعد معالجة الرسم البياني عبر عدة طبقات انتباه وهذه المسارات الاختصارية، يلخّص النظام المعلومات من الشبكة بأكملها في تمثيل مضغوط يُزوَّد إلى مُصنِّف نهائي يتنبأ بأي من الفئات الأربع ينتمي إليها كل مستخلص.
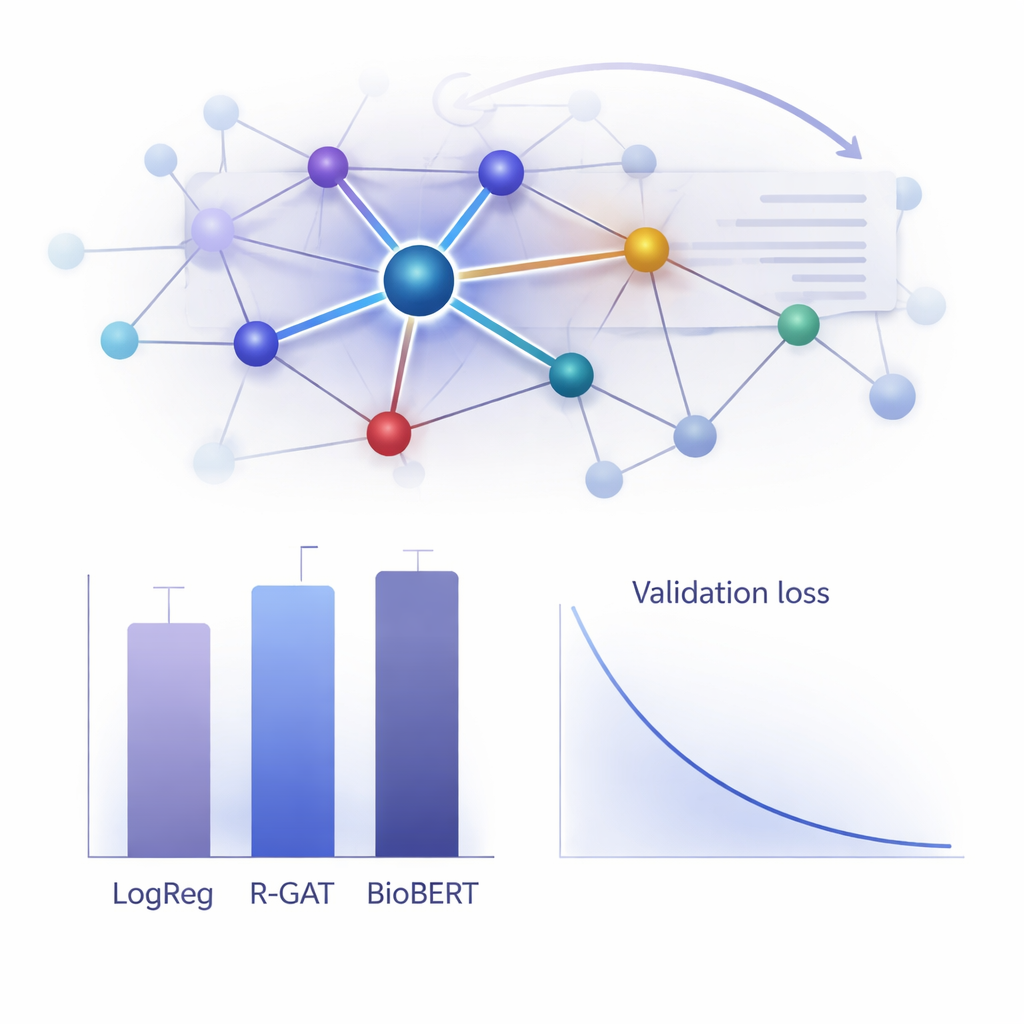
ما مدى فعاليته عملياً؟
لتقييم قيمة R-GAT، قارن المؤلفون أدائه بمجموعة واسعة من البدائل، من النماذج الخطية الكلاسيكية إلى أنظمة المحولات المتقدمة مثل BioBERT، الشائعة لكنها مكلفة حسابياً. وبشكل مفاجئ، حقق نموذج الانحدار اللوجستي البسيط باستخدام ميزات عدد الكلمات أعلى نتيجة خام على مجموعة البيانات هذه، كما قدّم BioBERT أداءً ممتازاً أيضاً—لكن كلاهما له عيوب، بما في ذلك الاعتماد على اختيارات ميزات محددة أو الحاجة إلى موارد حوسبة كبيرة. وصل R-GAT إلى مقياس F1 ماكرو بنحو 0.96، قريباً من أفضل النماذج، مع إظهار نتائج مستقرة جداً عبر تقسيمات تدريب–اختبار مختلفة. أظهرت اختبارات متأنية حيث أُزيل الانتباه أو الروابط المتبقية هبوطاً واضحاً في الأداء، مؤكدة أن العنصرين ضروريان لصلابة النموذج عند وجود بيانات محدودة.
ماذا يعني هذا لأبحاث السرطان المستقبلية
بالنسبة للقارئ العادي، الخلاصة واضحة: R-GAT أداة عملية تساعد على فرز أوراق أبحاث السرطان حسب النوع بدقة عالية ومتسقة، دون الحاجة إلى مجموعات بيانات ضخمة أو أجهزة مكلفة. لا يحل محل أقوى نماذج اللغة المتاحة، لكنه يوفر حلاً وسطاً موثوقاً—مفيداً خصوصاً للمستشفيات وفرق البحث أو فرق الصحة العامة التي تحتاج إلى نتائج قابلة للاعتماد وقابلة للتكرار تحت قيود البيانات والميزانية. عبر إتاحة كل من نموذجهم ومجموعة البيانات المنقَّحة علناً، يقدّم المؤلفون أيضاً معياراً مشتركاً يمكن للآخرين استخدامه لبناء واختبار أنظمة محسّنة. على المدى الطويل، قد تجعل مثل هذه الأدوات من الأسهل بكثير على الخبراء متابعة أدبيات السرطان وتحويل النتائج الجديدة إلى رعاية أفضل.
الاستشهاد: Hossain, E., Nuzhat, T., Masum, S. et al. R-GAT: cancer document classification leveraging graph-based residual network for scenarios with limited data. Sci Rep 16, 6582 (2026). https://doi.org/10.1038/s41598-026-39894-6
الكلمات المفتاحية: معلوماتية السرطان, تنقيب النصوص الطبية الحيوية, تصنيف المستندات, الشبكات العصبية البيانية, التعلّم ببيانات محدودة