Clear Sky Science · ar
التعرّف المتين على الأماكن تحت تغيُّرات الإضاءة باستخدام بيانات شبيهة بـ LiDAR من صور بزاوية 360 درجة
روبوتات لا تضيع أبداً في الظلام
تخيّل روبوتاً يستطيع أن يتعرّف على موقعه داخل مبنى، سواء كان الوقت منتصف النهار مع أشعة الشمس تدخل من النوافذ أو في ساعة متأخرة من الليل مع عدد قليل من المصابيح فقط. يقدّم هذا البحث طريقة جديدة لمنح الروبوت هذا النوع من الإحساس الموثوق بالمكان باستخدام كاميرا واحدة نسبياً ورخيصة. من خلال تحويل الصور المسطحة إلى معلومات ثلاثية الأبعاد، يجعل الباحثون تنقّل الروبوت أقل حساسية للظلال والوهج وتغيُّرات الإضاءة الأخرى التي عادة ما تشتت أنظمة الرؤية المعتمدة على الصور.
لماذا يصعب تحديد نفس المكان مرتين
بالنسبة للروبوت، «التعرّف على المكان» يعني الإدراك: «لقد كنت هنا من قبل»، حتى يتمكّن من تحديد موقعه على خريطة والتنقّل بأمان. تعتمد الأنظمة التقليدية إما على كاميرات عادية أو حسّاسات مدى بالليزر المعروفة بـ LiDAR. الكاميرات رخيصة وتلتقط ألواناً ونَسقاً غنياً، لكن مظهر المشهد يتغير جذرياً بين أيام غائمة ومشمسة وفي الليل. LiDAR أكثر استقراراً لأنه يقيس المسافة مباشرة، لكنه ضخم ومكلّف. بعض الروبوتات تجمع بين حسّاسات متعددة، لكن ذلك يزيد التكلفة والتعقيد. يتبنى مؤلفو هذا العمل مساراً مختلفاً: يحافظون على بساطة العتاد باستخدام كاميرا شاملة الرؤية واحدة تراقب المحيط بالكامل، ويطوّرون البرمجيات بحيث يفكر الروبوت في البنية الثلاثية الأبعاد بدلاً من المظهر الخام.
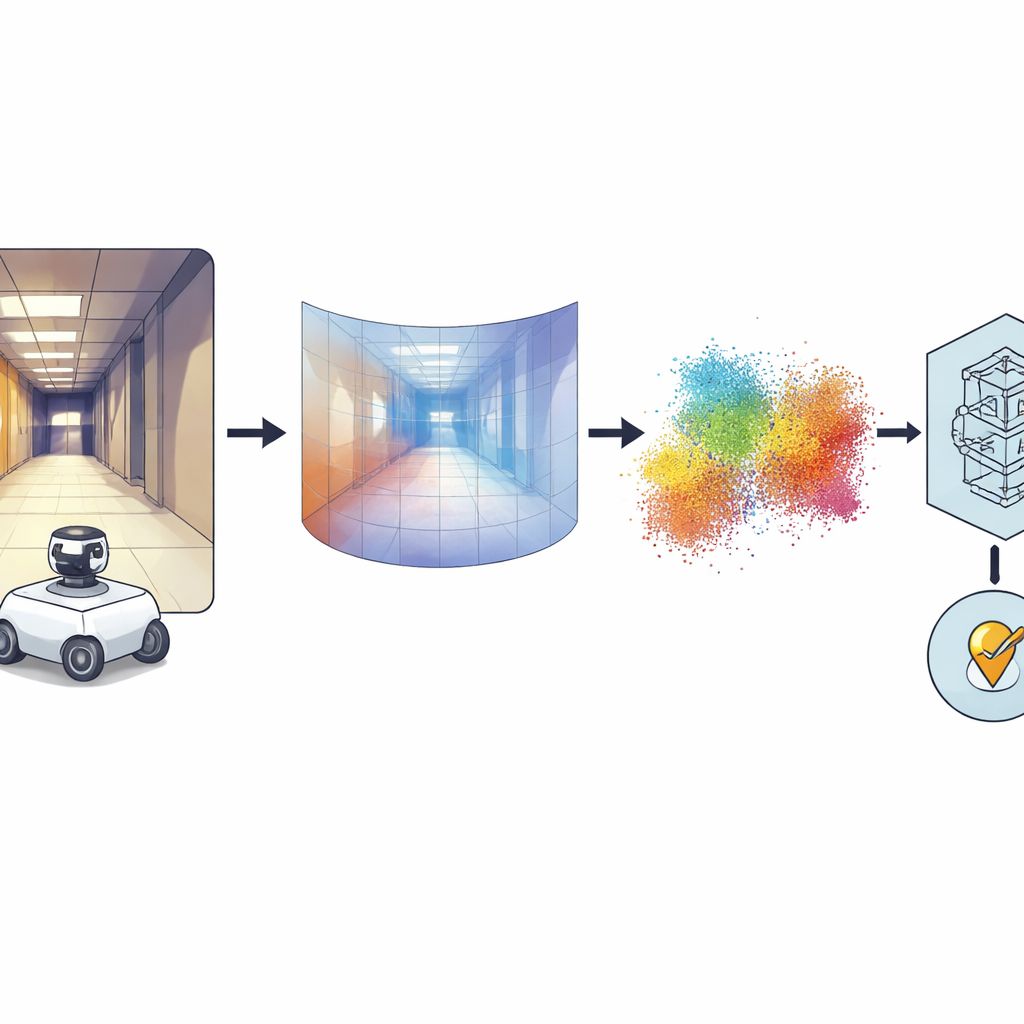
من صور شاملة إلى أشكال ثلاثية الأبعاد
الفكرة الأساسية هي تحويل كل صورة بانورامية إلى خريطة كثيفة للعمق، حيث يعبر كل بكسل عن بعد ذلك الجزء من المشهد عن الكاميرا. لتحقيق ذلك، يعتمد المؤلفون على نموذج أساس قوي يُدعى Distill Any Depth، الذي تعلّم استنتاج العمق من مجموعات ضخمة من الصور. ثم تُحوّل خريطة العمق الناتجة إلى سحابة نقاط ثلاثية الأبعاد — نوع من LiDAR افتراضي أو pseudo-LiDAR — دون الحاجة إلى ماسح ليزر حقيقي. تُنقّح معالجة إضافية العيوب الناتجة عن المرآة الخاصة المستخدمة للكاميرا بزاوية 360 درجة، فيُعالج ملء المناطق المفقودة أو المحجوبة. أخيراً، تضغط شبكة عصبية تُدعى MinkUNeXt، مصممة للعمل مباشرة على سحب النقاط ثلاثية الأبعاد، كل سحابة إلى بصمة مدمجة تلتقط التخطيط العام للمكان.
تعليم النظام تجاهل خدع الإضاءة
تقديرات العمق ليست مثالية، خصوصاً عندما تتغير الإضاءة بشدّة من لحظة إلى أخرى. لجعل النظام متيناً، قدّم الباحثون خدعة تدريبية جديدة يسمونها Distilled Depth Variations. بدلاً من الثقة في نموذج عمق واحد، يخلطون عمداً توقعات العمق من عدة نسخ أصغر وأقل دقة من مقدّر العمق. تحاكي هذه «الضوضاء» المتحكّم بها التشوّهات التي تظهر تحت ظروف إضاءة مختلفة، مما يجبر الشبكة الثلاثية الأبعاد على تعلّم ما يهم فعلاً في هندسة المكان وما يمكن تجاهله بأمان. كما يُثرون كل نقطة ثلاثية الأبعاد بمعلومات عن الحواف وقوة النسيج في الصورة — ميزات تميل لأن تكون أكثر ثباتاً عبر تغيّرات الإضاءة من اللون الخام.
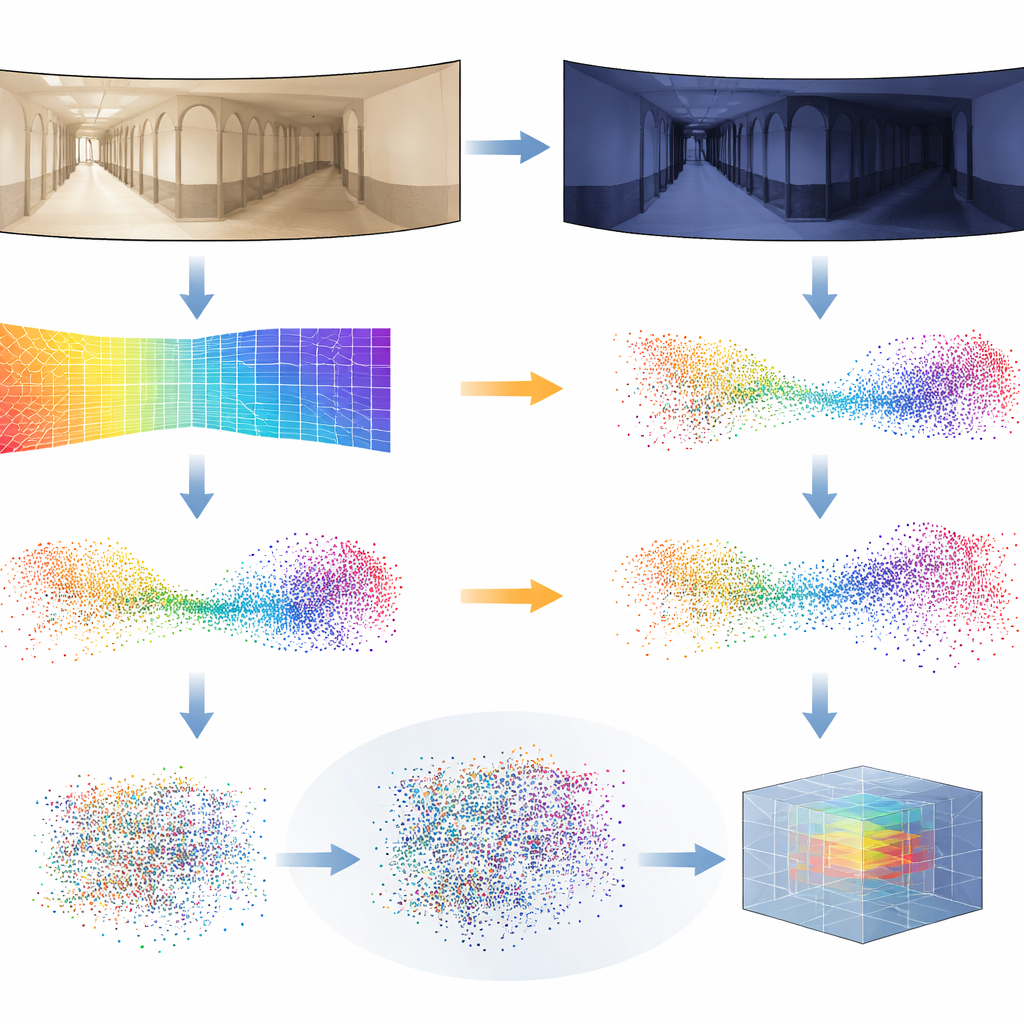
إثبات الفعالية في العالم الحقيقي
لاختبار نهجهم، لجأ الفريق إلى مجموعات بيانات عامة ومطالبة لرحلات روبوت داخلية. في هذه المجموعات، يتجوّل روبوت في ممرات وغرف عدة مرات تحت ضوء غائم، وضوء شمس ساطع، وفي الليل، بينما تتحرّك الأثاث والأشخاص. درّب المؤلفون نظامهم باستخدام صور غائمة فقط من مبنى واحد ثم قيّموه عبر جميع المباني وظروف الإضاءة، بما في ذلك مشاهد لم يرها النظام من قبل. تفوّق أسلوب pseudo-LiDAR أو كان مساوياً باستمرار لتقنيات رائدة تعتمد على الصور ثنائية الأبعاد وأنظمة ثلاثية الأبعاد أخرى، خاصة في أصعب الحالات مثل رحلات الليل أو الانتقال إلى بيئات جديدة كلياً. كما أظهروا أن نفس السلسلة تعمل مع كاميرات عادية مواجهّة للأمام، وليس فقط الكاميرات البانورامية، عبر تبديل الإسقاط المناسب من العمق إلى ثلاثي الأبعاد.
ماذا يعني ذلك للروبوتات المستقبلية
بعبارات عملية، يبيّن هذا العمل أن الروبوت يمكنه اكتساب وعي شبيه بـ LiDAR ببيئة المحيط باستخدام كاميرا واحدة وبرمجيات ذكية فقط. من خلال التركيز على البنية الثلاثية الأبعاد بدلاً من تفاصيل الإضاءة واللون المتقلبة، يمكن للنظام التعرّف على الأماكن بشكل موثوق عبر النهار والليل وتغيّرات الطقس، مع الحفاظ على عتاد بسيط وميسور التكلفة. قد يجعل هذا التنقّل الداخلي المتين أكثر سهولة للروبوتات الخدمية، ومركبات المخازن، والأجهزة المساعدة، ويفتح الباب لأنظمة مستقبلية تمزج العمق مع فهم أعلى مستوى للمشهد لتحقيق استقلالية أكثر موثوقية.
الاستشهاد: Cabrera, J.J., Alfaro, M., Gil, A. et al. Robust place recognition under illumination changes using pseudo-LiDAR from omnidirectional images. Sci Rep 16, 8817 (2026). https://doi.org/10.1038/s41598-026-39848-y
الكلمات المفتاحية: تحديد موضع الروبوت, الرؤية ثلاثية الأبعاد, التعرّف على المكان, تقدير العمق, كاميرات شاملة الرؤية