Clear Sky Science · ar
يمكن للذكاء الاصطناعي القابل للتفسير أن يفسر تثبيط الكربونيك أنهيدراز عبر التنبؤ الكونفورمالي وتوضيحات مضادة للحقيقة
لماذا تهم الأدوية الذكية المضادة للسرطان
غالبًا ما تتصرف أدوية السرطان كأدوات خشنة: فهي تهاجم خلايا الورم وقد تصيب أيضًا الأنسجة السليمة وتسبب آثارًا جانبية خطيرة. أحد المسارات الواعدة لتحسين الدقة هو حجب نسخ محددة من إنزيم يُدعى الكربونيك أنهيدراز، الذي يساعد الأورام على البقاء في بيئات منخفضة الأكسجين. ومع ذلك، فإن عدة نسخ من هذا الإنزيم تبدو متشابهة للغاية، مما يصعّب تصميم أدوية تستهدف النسخ «الضارة» في الأورام دون الإضرار بالنسخة «النافعة» الموجودة في أنحاء الجسم. تُظهر هذه الدراسة كيف يمكن للذكاء الاصطناعي القابل للتفسير أن يساعد الباحثين على التنقل في هذا التحدي وتصميم مرشحين دوائيين أكثر انتقائية وأمانًا.
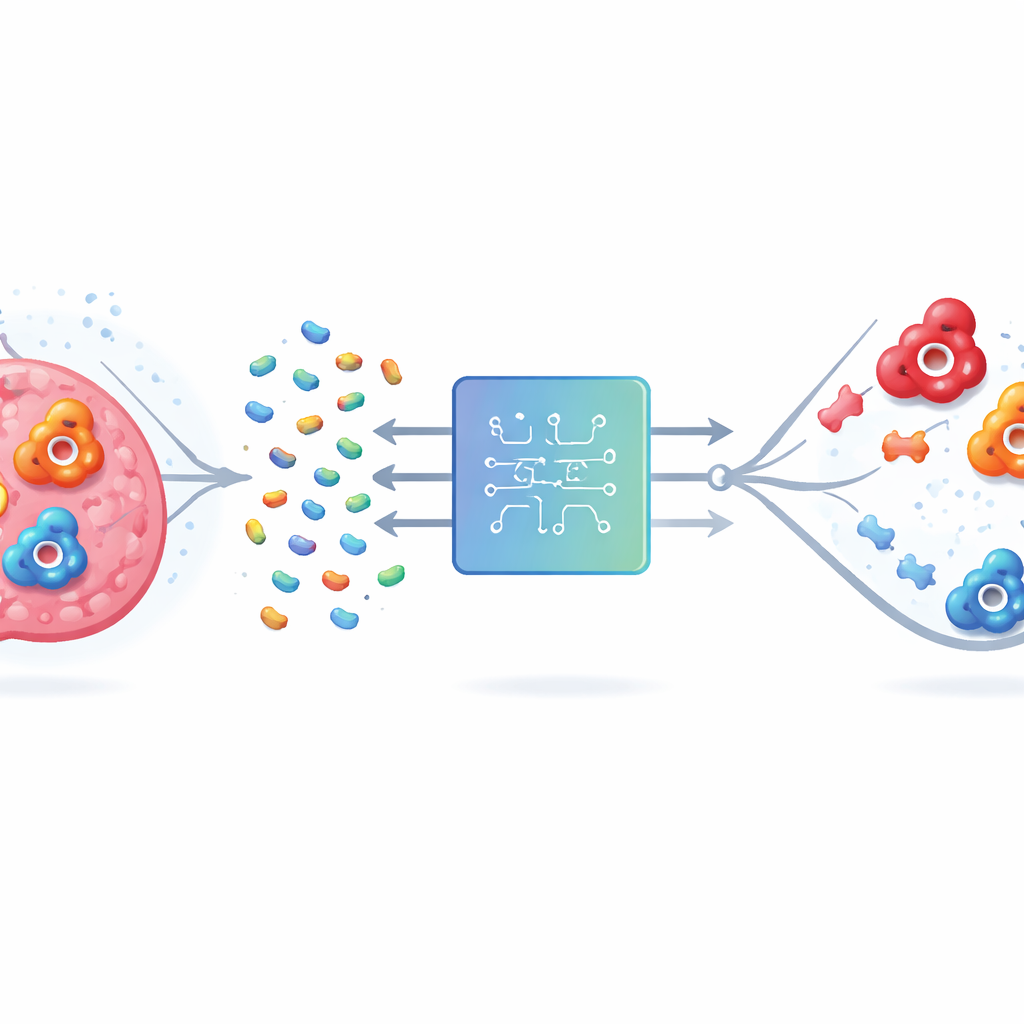
مشكلة استهداف الهدف الخاطئ
يأتي الكربونيك أنهيدراز البشري (hCA) بأشكال أو متغايرات متعددة. يرتبط اثنان منهما، IX وXII، ببقاء خلايا السرطان في أورام تعاني نقص الأكسجين، لذا قد يبطئ حجبهما تقدم المرض ويحسن علاجَه. لكن المتغاير II منتشر في الأنسجة السليمة وله موقع فعال يشبه إلى حد كبير مواقع IX وXII. قد تؤدي الأدوية التي ترتبط بالثلاثة معًا إلى مشاكل غير مرغوب فيها مثل الحماض الأيضي واضطرابات الرؤية. تواجه الطرق التقليدية في المختبر والحاسوب صعوبة لأن الإنزيمات جزيئات كبيرة ومعقدة، وعدد المركبات الشبيهة بالأدوية المحتملة هائل. لا يمكن اختبارها جميعًا بشكل شامل، لا في المختبر ولا على الحاسوب.
بناء قاعدة بيانات نظيفة وموثوقة
عالج المؤلفون ذلك أولًا بتجميع قاعدة بيانات مُنقّاة بعناية تضم آلاف الجزيئات المختبرة ضد hCA II وIX وXII من مستودع ChEMBL. قاموا بتوحيد الهياكل الكيميائية، وحذف القياسات المشكوك فيها، والتركيز على مركبات تشترك في مجموعة ربط الزنك النموذجية لهذه الفئة من المثبطات. باستخدام عتبات صارمة، صنفوا الجزيئات كمفعَّلة بوضوح أو غير مفعَّلة بوضوح وتخلّصوا من الحالات الحدية التي قد تربك النماذج. وبما أن عدد الجزيئات غير الفعالة كان أكبر بكثير من الفعالة، قاموا بموازنة البيانات حتى لا تميل خوارزميات التعلم إلى التصنيف لصالح الفئة الغالبة. كما استخدموا طريقة تقسيم «مستندة إلى السقالات» بحيث تحتوي مجموعات التدريب والاختبار على أُطر جزيئية أساسية مختلفة، مما يمنح صورة أكثر واقعية لكيفية تعامل النماذج مع مركبات جديدة حقًا.
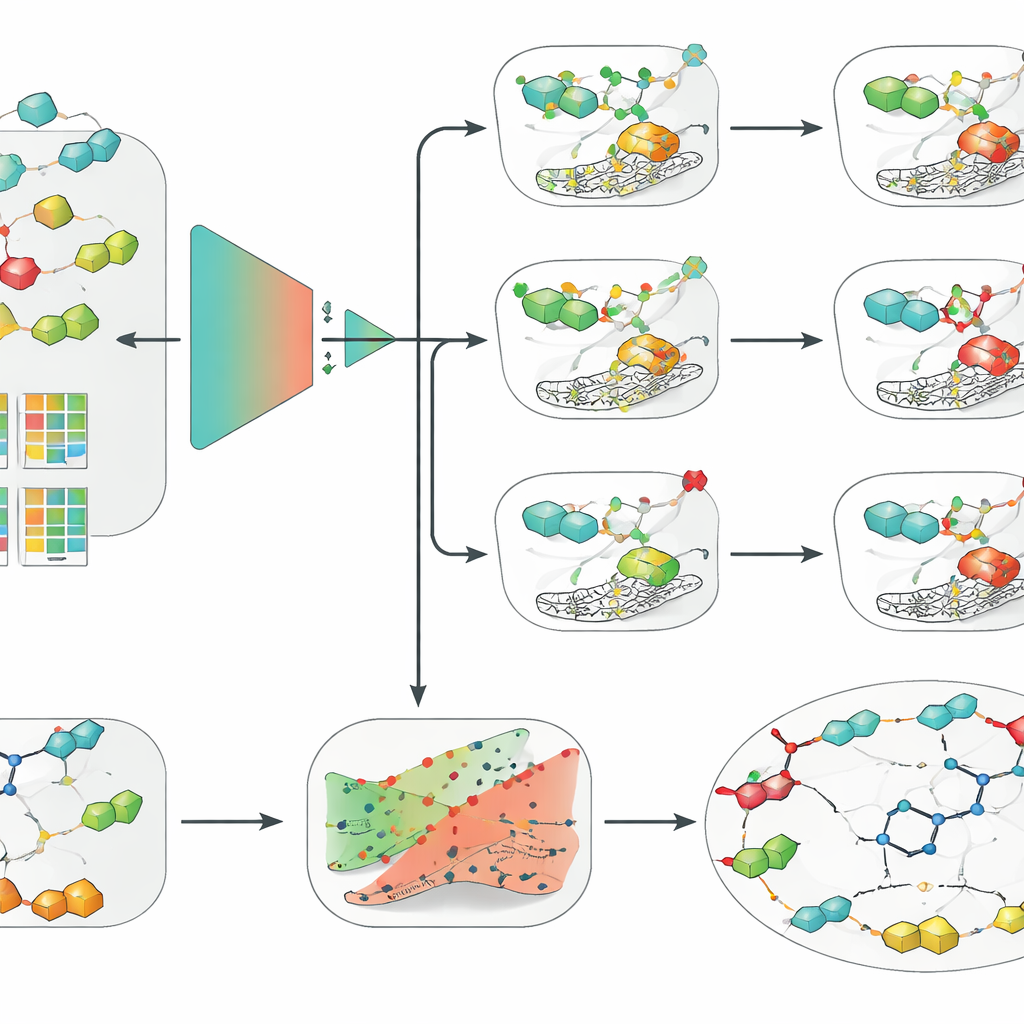
النماذج البسيطة تتفوق على التعلم العميق عندما تكون البيانات محدودة
باستخدام مجموعة البيانات المُنقّاة، قارن الفريق مجموعة واسعة من الأساليب، من طرق التعلم الآلي الكلاسيكية مثل الانحدار اللوجستي والغابات العشوائية وآلات الدعم الناقلة (SVMs) إلى الشبكات العصبية العميقة الحديثة، بما في ذلك النماذج القائمة على الرسوم التي تعمل مباشرة على الهياكل الجزيئية. أقرنوا هذه الأساليب بعدة طرق لترميز الجزيئات، مثل الوصوف اليدوية التقليدية، وبصمات المفاتيح، والتضمينات المتعلمة من نموذج لغة كيميائية. عبر المتغايرات الثلاثة وتحت تقييم أكثر صرامة قائم على السقالات، برز تركيب واحد باستمرار: SVM مزود ببصمات الاتصال الموسعة (extended-connectivity fingerprints)، وهي طريقة منظمة لوصف البيئات الكيميائية المحلية داخل الجزيء. ومن المدهش أن هذا الإعداد البسيط نسبيًا تفوّق على نماذج الرسم والتعلم العميق الأكثر رواجًا، مما يبرز أن جودة البيانات، والتحقق الدقيق، والوصوف الجزيئية الجيدة قد تكون أكثر أهمية من تعقيد الخوارزمية عندما تكون مجموعات البيانات متواضعة الحجم.
إضافة ثقة موثوقة وتفسيرات ودية للبشر
ثم أضاف الباحثون على أفضل نموذج SVM طبقتين إضافيتين مصممتين لجعل توقعاته أكثر قابلية للاستخدام في اكتشاف الأدوية الحقيقي. أولًا، طبقوا إطار عمل يسمى التنبؤ الكونفورمالي، الذي لا يعطي إجابة بنعم أو لا فقط، بل يوفر منطقة من النتائج المحتملة مع معدل خطأ مضمون. يتيح هذا للعلماء ضبط مدى الحذر الذي يريدونه وللتعرّف على الحالات التي يكون فيها النموذج غير متأكد فعليًا. ثانيًا، استخدموا توضيحات مضادة للحقيقة لتجعل منطق النموذج أكثر بديهية. بالنسبة إلى جزيء معين، ولّدوا نظائر قريبة تقلب النتيجة المتوقعة من فعّال إلى غير فعّال أو العكس. عند فحص هذه الأزواج لمرشح علاجي SLC-0111، الذي يثبط انتقائيًا IX وXII وليس II، اكتشفت الطريقة بشكل مستقل بصيرة مهمة في كيمياء الأدوية: تغييرات صغيرة في الجزء «الذنب» من الجزيء تغيّر بشدة أي متغاير يفضّل الارتباط به.
من الخوارزميات إلى أدوات عملية لتصميم الأدوية
ليجعلوا نهجهم في متناول اليد، حزم المؤلفون النماذج الثلاثة لـSVM وطبقة عدم اليقين ومحرك التوضيحات المضادة في أداة رسومية اسمها CAInsight. يمكن للمستخدم إدخال تمثيل نصي للجزيء وبنقرة واحدة الحصول على نشاط متوقع ضد hCA II وIX وXII، وتقدير لمدى موثوقية كل توقُّع، وتعديلات تركيبية مقترحة قد تزيد أو تقلل النشاط. بينما تركز النماذج على تصنيف الجزيئات كفعالة أو غير فعالة بدلاً من التنبؤ بالقدرة الحقيقية أو الانتقائية بدقة في خطوة واحدة، إلا أنها بالفعل تعيد سلوكيات معروفة لمرشحين دوائيين حقيقيين وتفرّق تغييرات تركيبية دقيقة. يشير المؤلفون إلى أن مجموعات بيانات أكبر وأكثر انتظامًا، بالإضافة إلى تحليل أعمق لكيفية اختيار عتبات النشاط، قد تحسّن الأداء أكثر.
ما معنى ذلك لأدوية السرطان المستقبلية
بعبارات بسيطة، تُظهر هذه العمل أن النماذج المبنية بعناية والمفسرة جيدًا يمكن أن تساعد الكيميائيين على تصميم أدوية سرطانية تميز بشكل أفضل بين أهداف إنزيمية متماثلة الشكل. من خلال الجمع بين إحصاء قوي، وتقديرات عدم اليقين، وأمثلة «ماذا لو» بديهية، لا يتنبأ الإطار فقط بأي الجزيئات من المحتمل أن تعمل بل يقترح أيضًا سبب ذلك. يمكن لهذا النوع من الذكاء الاصطناعي الشفاف أن يسرّع الفرز الافتراضي، ويدعم التصميم التوليدي لمركبات جديدة، ويقلل من العبء التجريبي والتجريبي في المختبر، مما يساعد في نهاية المطاف على اكتشاف علاجات أكثر انتقائية وأمانًا للمرضى.
الاستشهاد: Ghamsary, M.S., Rayka, M. & Naghavi, S.S. Interpretable machine learning rationalizes carbonic anhydrase inhibition via conformal and counterfactual prediction. Sci Rep 16, 8419 (2026). https://doi.org/10.1038/s41598-026-39771-2
الكلمات المفتاحية: مثبطات الكربونيك أنهيدراز, الذكاء الاصطناعي القابل للتفسير, انتقائية الأدوية, التنبؤ الكونفورمالي, توضيحات مضادة للحقيقة