Clear Sky Science · ar
إطار تكيّفي لإعادة توازن البيانات للتنبؤ بالمخاطر المرورية في الوقت الفعلي
لماذا يهم موازنة بيانات المرور من أجل السلامة
حوادث الطرق السريعة أحداث نادرة مقارنةً بكمية القيادة الاعتيادية الخالية من الحوادث. هذه نعمة للسلامة، لكنها تخلق مشكلة مخفية لأنظمة الحوسبة التي تحاول التنبؤ بوقت ومكان وقوع الحوادث في الوقت الفعلي. عندما تهيمن الحالات الآمنة على البيانات، قد تصبح الخوارزميات بارعة في التنبؤ بـ«لن يحدث شيء» وتبدو دقيقة على الورق—بينما تفشل بهدوء في الكشف عن اللحظات الخطرة الحقيقية. يتناول هذا البحث هذا الاختلال بشكل مباشر، مقترحًا طريقة تكيفية لإعادة توازن بيانات المرور بحيث تستطيع أنظمة الإنذار التعرف بشكل أفضل على حالات الخطر النادرة لكنها المهمة من دون أن تصبح بطيئة جدًا للاستخدام العملي.
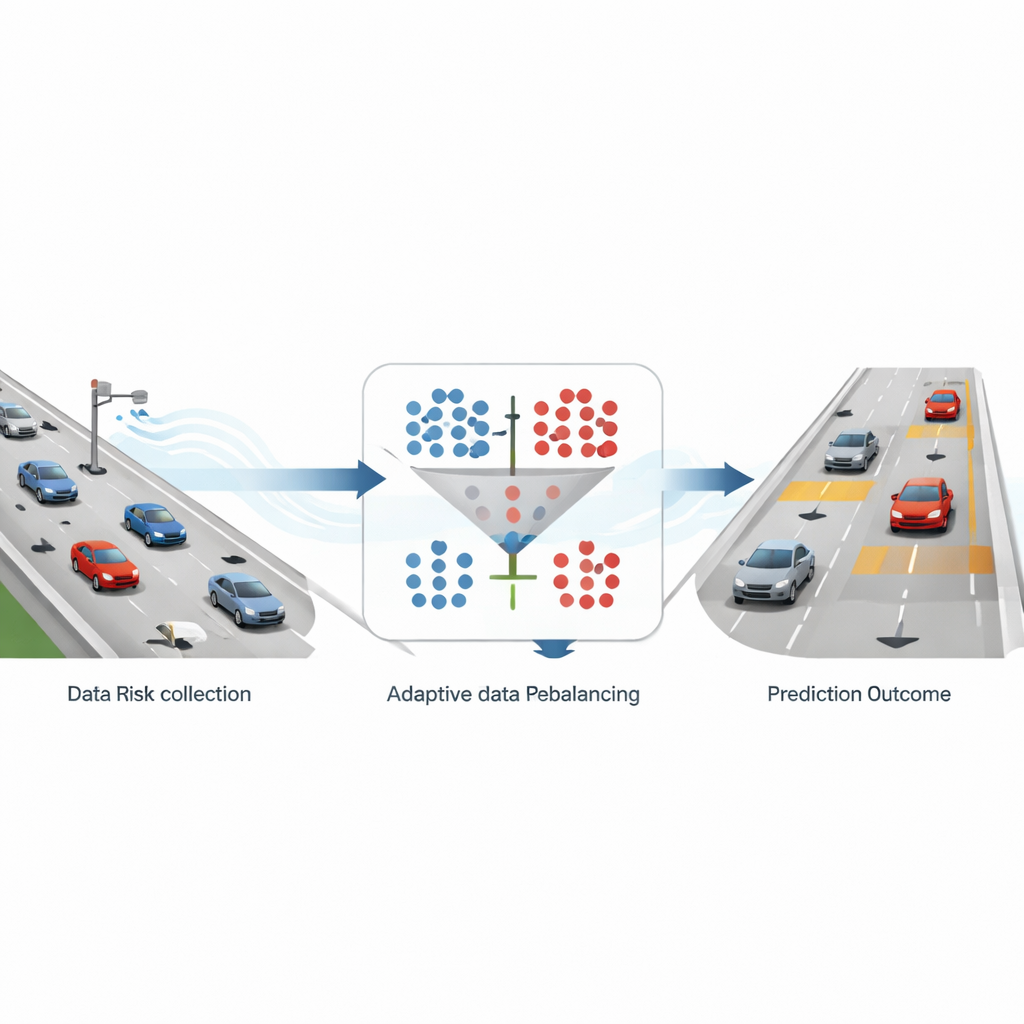
كيف تتحول حركة المرور الحقيقية إلى إشارات إنذار
يبني الباحثون إطارهم على بيانات مسارات مفصّلة من مجموعة بيانات واسعة مُسجلَة بواسطة طائرات بدون طيار على طرق سريعة ألمانية. يتم تتبع موضع وسرعة كل مركبة عدة مرات في الثانية على مقاطع طرق من ست حارات. من سجل الحركة الغني هذا، يحسب الفريق مؤشر سلامة مستخدمًا على نطاق واسع يُسمى زمن الاصطدام (time-to-collision)، الذي يقدّر المدة التي ستستغرقها سيارة تابعة لمصادمة السيارة الأمامية لو استمرت المركبتان على الحالة نفسها. عندما ينخفض هذا الزمن إلى أقل من ثلاث ثوانٍ، تُوسم الحالة بأنها «عالية المخاطر»؛ وإلا فتُعامل كـ«غير مخاطرة». بعد تجميع هذه القياسات في شرائح زمنية مدتها 10 ثوانٍ والتركيز على الطرق ذات الست حارات، ينتهي المطاف إلى حوالي عيّنة آمنة واحدة مقابل كل عيّنة خطرة، ما يجعل مجموعة البيانات منحازة بشكل قوي يعكس ظروف الطرق السريعة الواقعية.
معالجة الاختلال دون فقدان ما يهم
لمعالجة هذا الانحياز، يقارن البحث استراتيجيتين شائعتين. الأولى، تُسمى الإفراط في العيّنات (oversampling)، تضيف أمثلة أكثر للحالات النادرة الخطرة بإنشاء عينات تركيبية تشبه الحالات الحقيقية عالية الخطورة. والثانية، التقليل من العيّنات (undersampling)، تقلّص العدد الكبير من الحالات الآمنة عن طريق حذف بعضها عشوائيًا. يستخدم المؤلفون طريقة إفراط شائعة (SMOTE) وطريقة تقليل عشوائي بسيطة، ويطبّقانها بنسب ثابتة متعددة للحالات الآمنة إلى الخطرة—1:1، 2:1، 3:1، و4:1. ثم يزوّدون كلًّا من مجموعات البيانات الأصلية والمعدّلة بأربعة نماذج تنبؤية: نهجان تقليديان في تعلم الآلة ونموذجان عميقان متخصصان في التعامل مع السلاسل الزمنية. من خلال اختبار كل هذه التركيبات، يمكنهم أن يقيّموا كيف تغيّر طرق موازنة البيانات قدرة النظام على رصد المخاطر مع الحفاظ على التعرف على الحالات الآمنة.
ترك الخوارزمية تبحث عن نقطة التوازن المثلى
بدلاً من افتراض أن الأعداد المتساوية تمامًا من العينات الآمنة والخطرة هي الأفضل، يترك الباحثون لخوارزمية جينية—طريقة بحث مستلهمة من التطور—مهمة البحث عن التوازن الأكثر فاعلية. يقوم هذا المحسّن بتعديل نسبة الآمن إلى الخطر ضمن نطاق واقعي من 1:1 إلى 4:1، مولِّدًا مرارًا نسبًا مرشحة، ومقيّمًا لها، ومُحسّنًا عبر مئات التكرارات. والأهم أنه لا ينظر إلى الدقة وحدها: بل يأخذ أيضًا في الاعتبار الزمن الذي يستغرقه النموذج للتدريب وإجراء التنبؤات، مراعيًا متطلبات الوقت الحقيقي لمراكز التحكم المروري. ولضمان إمكانية دمج الدقة وزمن الحساب بشكل عادل، تُطبَع كل المقاييس قبل دمجها في درجة «الملاءمة» الوحيدة التي تسعى الخوارزمية لتقليلها.
ما الذي تتعلمه النماذج عن المخاطر على الطريق
خلال التجارب العديدة، يبرز نمط واحد بوضوح. تحسين توازن البيانات يعزز التنبؤ بالمخاطر مقارنة بترك الانحياز الأصلي، وتميل طرق الإفراط في توليد عينات خطرة تركيبية لأن تعطي نتائج أفضل من حذف الحالات الآمنة. تعطي نسبة 2:1 من الآمن إلى الخطر أفضل أداء بين الإعدادات الثابتة، متفوقة على الخيار الشائع 1:1. عندما يُسمح للخوارزمية الجينية بضبط هذه النسبة، تستقر على قيم طفيفي الاختلال لكنها مثالية—حوالي 2.3:1 للإفراط في العيّنات وحوالي 2.7:1 للتقليل. من بين نماذج التنبؤ، يقدم نوع معين من الشبكات العصبية المتكررة المعروف باسم وحدة الارتداد البوابية (GRU) نتائج أقوى باستمرار، خاصة عند اقترانها بالإفراط في العيّنات والتحسين. كما تكشف النماذج أن متوسط سرعات المركبات أعلى وأسفل نقطة على الطريق أكثر إفادة في التنبؤ بالمخاطر من العدّ البسيط لعدد المركبات.
فحص الاستقرار والاستعداد للتطبيق العملي
لأن طرق التحسين قد تعلق أحيانًا في حلول مضللة، يفحص المؤلفون كيف يتصرف بحثهم مع مرور الوقت. يبينون أن درجات الملاءمة تنخفض بثبات وفي نهاية المطاف تستقر، مما يشير إلى أن الخوارزمية تتقارب نحو نسب مستقرة وعالية الجودة بدلًا من التذبذب. ثم يقومون بتعديل النسب المختارة للأعلى والأسفل بنسب قليلة ليروا ما إذا كان الأداء ينهار. عمليًا، تنخفض الدقة قليلاً عند تغييرات صغيرة، مما يدل على أن النظام قوي وليس مضبوطًا بإفراط على إعداد واحد هش. ومع ذلك، عندما تصبح حصة البيانات المخصصة للاختبار كبيرة جدًا، تصبح النماذج أكثر حساسية، مما يبرز الحاجة إلى بيانات تدريبية كافية الغنى.
ما معنى ذلك لطرق سريعة أكثر أمانًا وذكاءً
بمصطلحات يومية، تُظهر الدراسة أن تعليم الحواسيب على التعرف على الخطر على الطريق ليس مسألة نماذج ذكية فقط؛ بل يتعلق أيضًا بتغذية هذه النماذج بصورة عادلة من الأحداث النادرة لكن الحرجة. من خلال تعديل عدد العينات الآمنة والخطرة المستخدمة في التدريب بعناية—وبالسماح لخوارزمية تكيفية بإيجاد أفضل توازن بين الدقة والسرعة—يجعل الإطار المقترح التنبؤ بالمخاطر على الطرق السريعة في الوقت الحقيقي أكثر موثوقية وأكثر عملية. يمكن لوكالات المرور دمج هذا النهج في أنظمة تراقب بيانات حساسات المرور وتصدر تحذيرات مبكرة حول احتمالات وقوع تصادمات من الخلف، ما يساعد في توجيه تنبيهات السائقين، ونشر الدورية، أو تفعيل استراتيجيات الكبح الآلي. بينما عُرض العمل على طرق سريعة ألمانية في طقس جيد، فإن الفكرة الأساسية لإعادة توازن البيانات التكيفية تقدم وصفة عامة لتحسين توقعات السلامة حيث تكون الأحداث الخطرة نادرة لكنها مهمة جدًا لئلا تُفقد.
الاستشهاد: Chen, S., Cui, B. & Chang, A. An adaptive data rebalancing framework for real-time traffic risk prediction. Sci Rep 16, 8882 (2026). https://doi.org/10.1038/s41598-026-39539-8
الكلمات المفتاحية: سلامة المرور, التنبؤ بمخاطر الحوادث, البيانات غير المتوازنة, تعلم الآلة, مسارات الطرق السريعة