Clear Sky Science · ar
CGDFNet: شبكة فصل دلالي ذات فرعين في الوقت الحقيقي مع دمج التفاصيل موجه بالسياق
تعليم السيارات رؤية الشارع بالكامل
تعتمد السيارات والروبوتات الحديثة بشكل متزايد على الكاميرات لفهم العالم من حولها — اكتشاف الطرق والأرصفة والأشخاص والمركبات واللافتات في الوقت الحقيقي. تقدم هذه الورقة CGDFNet، نظام رؤية حاسوبية جديد مصمم لأداء هذا النوع من «فهم المشهد» بسرعة ودقة أكبر، لا سيما في شوارع المدن المزدحمة. من خلال تعلّم الحفاظ على كل من التفاصيل الدقيقة (مثل أعمدة إشارات المرور أو عجلات الدراجات) والتركيب العام للمشهد (مثل الطرق والمباني) في آن واحد، تهدف CGDFNet إلى جعل القيادة الآلية ومهام الرؤية في الوقت الحقيقي الأخرى أكثر أمانًا وموثوقية.
لماذا الرؤية على مستوى البكسل تطلبة للغاية
في التقسيم الدلالي، يخصص الحاسوب فئة لكل بكسل في الصورة: طريق، سيارة، مُشاة، سماء، وهكذا. هذا يتطلب جهدًا أكبر بكثير من رسم مربع حول سيارة، لأن النظام يجب أن يتتبع حدود الأجسام والأشكال الصغيرة بدقة عالية. توجد طرق ذات دقة عالية كثيرة، لكنها عادةً ما تكون بطيئة وتستهلك طاقة كبيرة، وهو ما لا يناسب أنظمة الوقت الحقيقي في السيارات والطائرات المسيّرة أو الأجهزة القابلة للارتداء. من ناحية أخرى، الطرق الخفيفة التي تعمل بسرعة غالبًا ما تضحّي بالتفاصيل أو تفقد الرؤية العامة للمشهد، فتواجه صعوبة مع الأجسام الصغيرة والهياكل الرفيعة أو البيئات الحضرية المزدحمة.
مساران: واحد للتفاصيل وآخر للسياق
تعالج CGDFNet هذا التوتر بتصميم من فرعين: يركز فرع واحد على التفاصيل الدقيقة، بينما يلتقط الآخر السياق الواسع. اعتمادًا على شبكة عمود فقري فعّالة، تُغذّي الطبقات الدنيا «فرع التفاصيل» الذي يحافظ على دقة أعلى للحفاظ على الحواف والأنسجة. وتغذّي الطبقات العميقة «فرع السياق» الذي يرى المشهد بشكل مضغوط أكثر، وهو مناسب لفهم التركيب العام والعلاقات بين الأجسام. على عكس تصميمات سابقة ذات فرعين تبقي هذين التيارين منفصلين إلى حد كبير ثم تجمعهما بشكل خام، تشجع CGDFNet على تواصلهما طوال مراحل المعالجة، بحيث تُراجع التفاصيل الدقيقة باستمرار بما يعرفه الشبكة عن المشهد ككل.
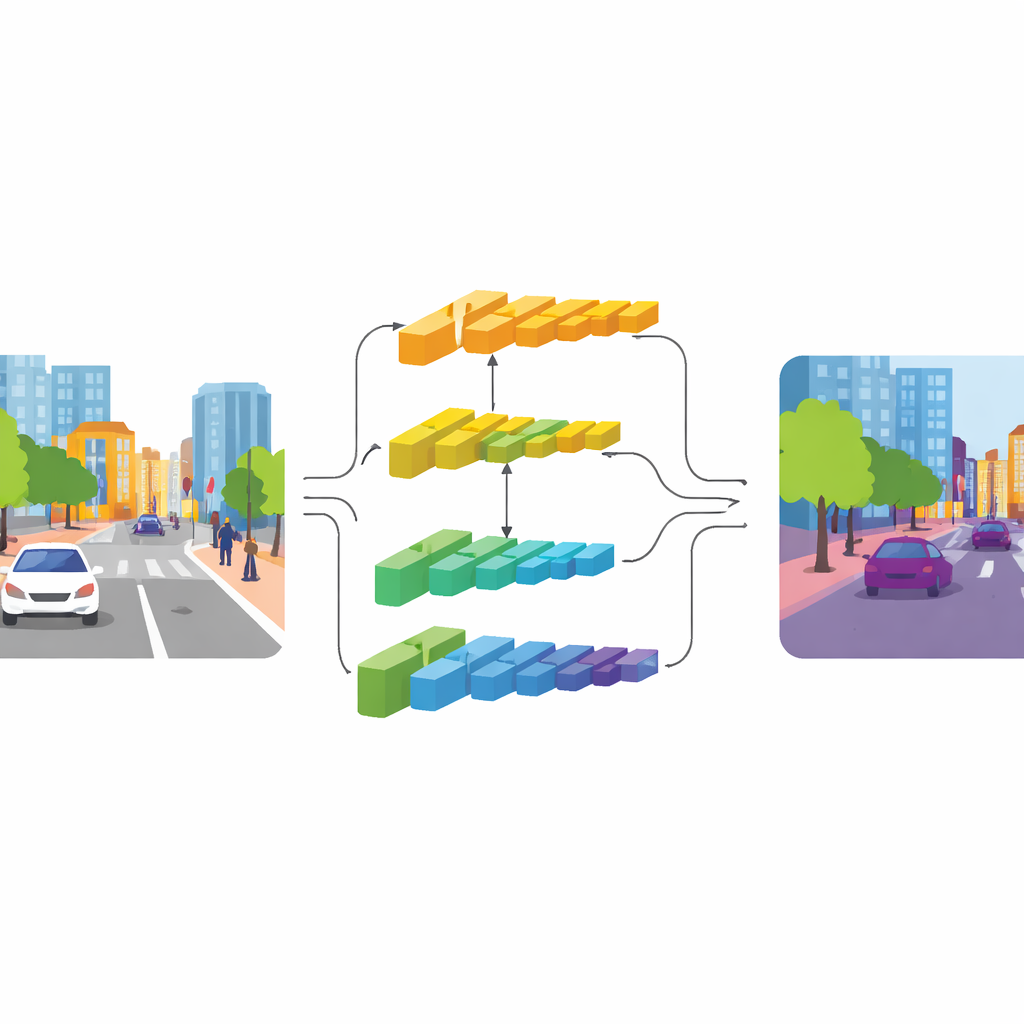
توجيه التفاصيل بالمعنى
مكونان رئيسيان يقوّيان هذا التفاعل. في فرع السياق، يتعلم وحدة تنقية دلالية (Semantic Refinement Module) إبراز المناطق والقنوات الأكثر معلوماتية في خرائط الميزات. تفعل ذلك بدمج الإشارات المحلية (أي أجزاء المشهد النشطة بجانب بعضها) مع الإشارات العالمية (ما تراه الشبكة عبر الصورة كاملة)، بحيث تحمل التمثيلات كلًا من تفاصيل الجوار ومعنى مستوى المشهد. في فرع التفاصيل، تستخدم وحدة التفاصيل الموجهة بالسياق (Context‑Guided Detail Module) هذه المعلومات الدلالية لتوجّه الانتباه نحو الحواف والهياكل الدقيقة المهمة، مثل محيط حافلة أو إطار دراجة. وتعتمد على نوع خاص من الالتفاف الحساس أكثر للتغيرات بين البكسلات المجاورة، ما يؤكد الخطوط والقرائن الصغيرة بطبيعتها دون إضافة العديد من المعاملات الزائدة.
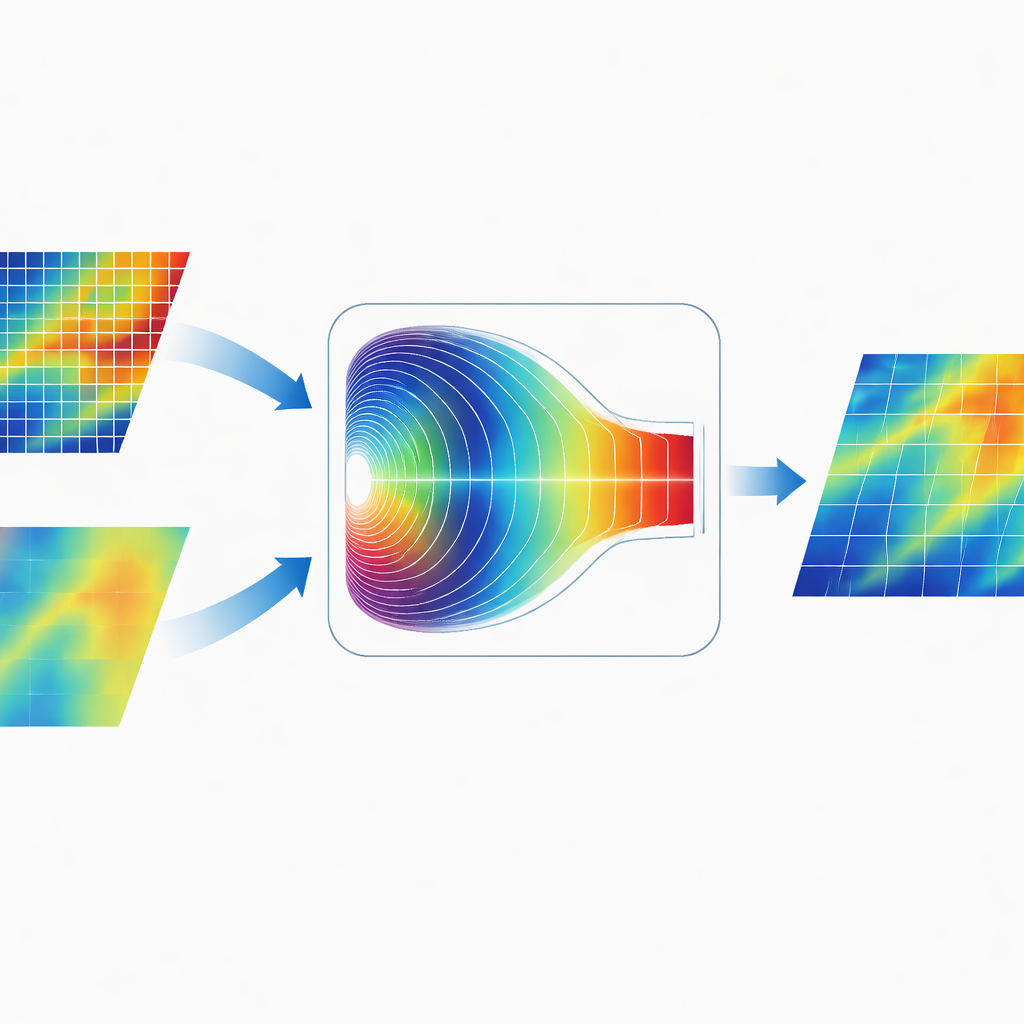
مزج المعلومات في عالم التردد
سمة مميزة في CGDFNet هي طريقة دمج الفرعين. بدلًا من جمع خرائطهما في فضاء الصورة ببساطة، صمم المؤلفون وحدة دمج تكيفية في نطاق فورييه (Fourier‑Domain Adaptive Fusion Module). هذه الوحدة تحول الميزات المدمجة مؤقتًا إلى نطاق التردد، حيث تُعبّر الأنماط من حيث التغيرات البطيئة والعريضة والتغيرات السريعة والحادة. ثم يتعلّم آلية بوابة تكيفية أي مكونات التردد يجب التأكيد عليها من فرع التفاصيل وأيها من فرع السياق. بعد هذا الترجيح، تُحوّل الميزات مرة أخرى، مما ينتج تمثيلًا يوحّد الحواف الحادة مع البنية العالمية المتماسكة بشكل أكثر فاعلية من الدمج التقليدي المعتمد على الفضاء المكاني فقط.
النتائج على شوارع حقيقية
اختبر الفريق CGDFNet على معيارين مستخدمين على نطاق واسع لمشاهد القيادة الحضرية: Cityscapes، المجمعة من مدن أوروبية، وCamVid، المأخوذة من منظور السائق في المملكة المتحدة. عالجت CGDFNet صورًا كبيرة بسرعات وقت‑حقيقي — حوالي 88 إطارًا في الثانية على Cityscapes وحوالي 129 إطارًا في الثانية على CamVid — بينما حققت دقة فصل تنافس أو تتجاوز العديد من أنظمة الحالة‑الأدنى‑من‑الفن. برز أداؤها بشكل خاص في الفئات التي عادةً ما يصعب تقسيمها، مثل السياجات، علامات المرور، الحافلات، والدراجات، حيث يكون الحفاظ على حدود دقيقة والهياكل الصغيرة أمرًا حاسمًا.
ماذا يعني هذا للتكنولوجيا اليومية
من الناحية العملية، تُظهر CGDFNet أنه من الممكن بناء أنظمة رؤية سريعة بما يكفي للاستخدام في الوقت الحقيقي وحريصة بما يكفي على احترام التفاصيل الصغيرة الحساسة للسلامة في مشاهد المدن المعقدة. بدمج فرع يركز على التفاصيل، وفرع يركز على السياق، وخطوة دمج ذكية في نطاق التردد، تحافظ الشبكة على رؤية متوازنة للشارع: تعرف مكان كل شيء وأين يبدأ وينتهي كل جسم. وبينما تبقى تحديات — مثل الحشود الكثيفة أو سوء الأحوال الجوية —، يقدم النهج مخططًا واعدًا للرؤية المستقبلية على الجهاز، من السيارات الذاتية القيادة إلى كاميرات المرور الذكية والروبوتات المساعدة.
الاستشهاد: Zhao, S., Fu, W., Gao, J. et al. CGDFNet: a dual-branch real-time semantic segmentation network with context-guided detail fusion. Sci Rep 16, 9191 (2026). https://doi.org/10.1038/s41598-026-39370-1
الكلمات المفتاحية: التقسيم الدلالي في الوقت الحقيقي, رؤية القيادة الذاتية, شبكة عصبية ذات فرعين, دمج الميزات القائم على فورييه, فهم المشاهد الحضرية