Clear Sky Science · ar
تحليل عناوين المرضى عبر التعلم التبايني المدرك للرسم المعرفي واستدلال نموذج لغوي كبير مقيد محليًا
لماذا تهمنا عناوين المرضى المرتبة
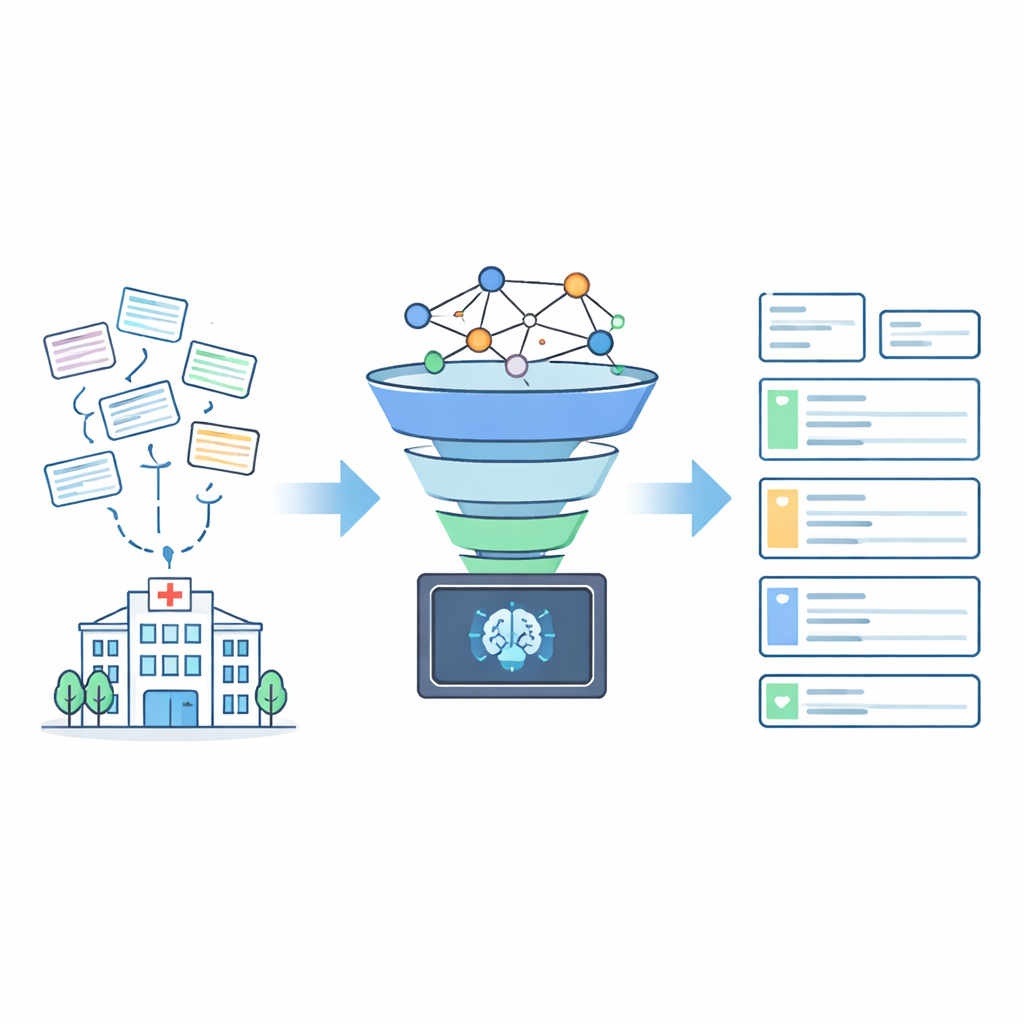
خلف كل زيارة للمستشفى سطر بسيط من النص: عنوان سكن المريض. بعيدًا عن كونه مسألة إدخالية، تُمكّن هذه العناوين رسم خرائط الأمراض، والتخطيط للطوارئ، وقرارات حول أماكن إنشاء العيادات وسيارات الإسعاف. ومع ذلك في العديد من نظم السجلات الطبية، تُخزن العناوين كنص فوضوي وغير متسق مليء بالاختصارات والأخطاء الإملائية والفراغات المفقودة. يقدّم هذا المقال AddrKG‑LLM، طريقة جديدة تحول مثل هذا النص الفوضوي إلى سجلات نظيفة وموثوقة مع الحفاظ على خصوصية البيانات الحساسة.
المشكلة مع عناوين المساكن الفوضوية
عندما تُكتب العناوين بحرية، يغفل الناس ذكر الأحياء، يبدلون ترتيب الكلمات، أو يستخدمون ألقابًا محلية لا تتعرف عليها الخرائط الرسمية. كانت الطرق الحاسوبية القديمة تقارن السلاسل حرفًا بحرف أو كقوائم كلمات بسيطة، وهو ما ينجح فقط عندما تكون المدخلات مرتَّبة ومكتملة بالفعل. تقرأ أنظمة التعلم العميق الأحدث السياق بذكاء أكبر، لكنها قد تتعثر أمام صياغات غير مألوفة وتحتاج إلى قدر كبير من الحوسبة. مؤخرًا أظهرت النماذج اللغوية الكبيرة قدرة ملحوظة على فهم وإنشاء النصوص. ولكن عندما يُسمح لها بالرد بحرية، فإنها تميل أيضًا إلى «الهلاوس»—إضافة تفاصيل غير موجودة في البيانات—وهو خطر غير مقبول في الرعاية الصحية، حيث يجب أن تكون السجلات دقيقة وقابلة للتدقيق.
مسار من خط الفوضى إلى نظام من خطوتين
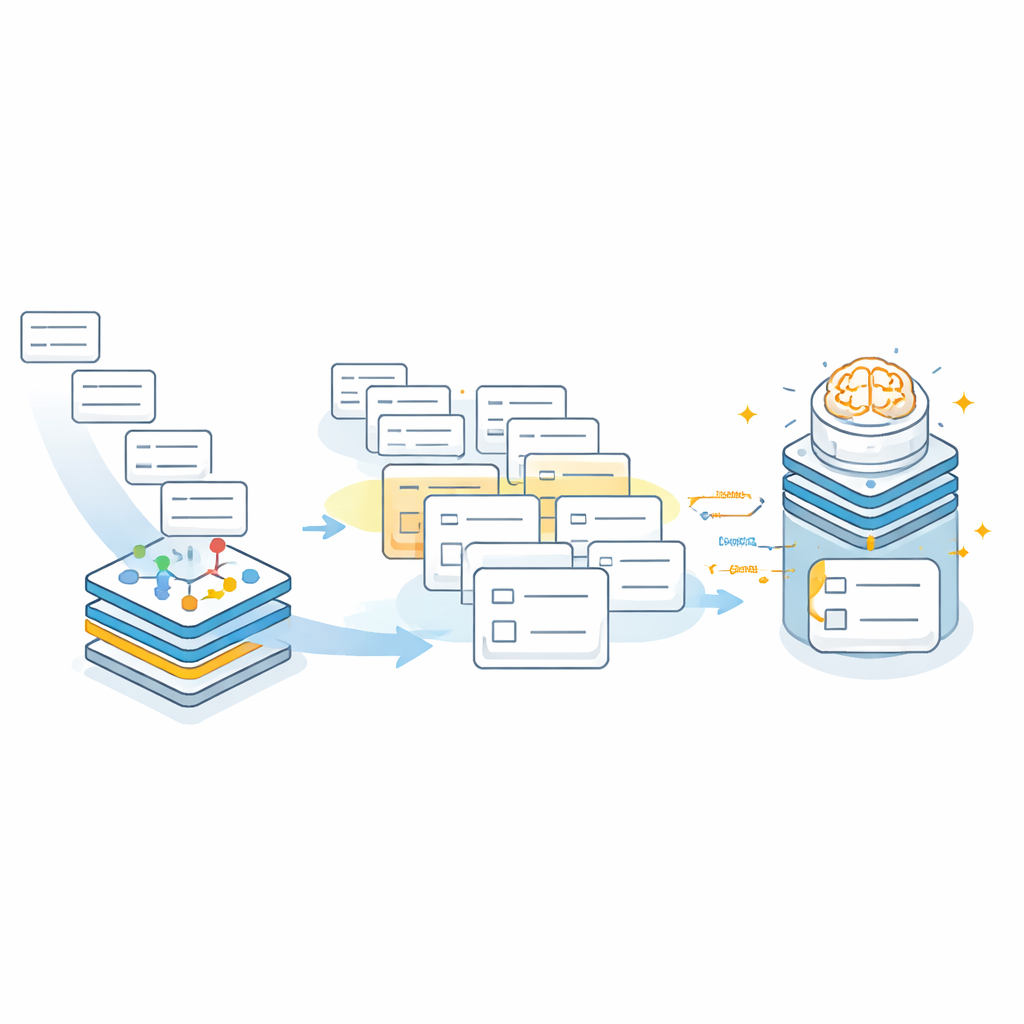
صمم الباحثون AddrKG‑LLM كخط أنابيب ذو مرحلتين يضيف بنية وضوابط حول نموذج اللغة بدلًا من تركه يعمل بمعزل. أولًا، تُنظف عناوين المرضى الواردة لإزالة التفاصيل ذات التعريف العالي مثل أرقام المباني والغرف وأرقام الهواتف، مما يساعد على حماية الخصوصية. يُحوَّل النص المتبقي إلى تمثيل رقمي كثيف يلتقط معناه. وفي الوقت نفسه، يبني الفريق رسمًا معرفيًا—شبكة تشبه الخريطة تُشفّر العلاقات الرسمية بين المدن والأحياء والشوارع والمجمّعات السكنية. باستخدام تقنية تُسمى التعلم التبايني، يُدرَّب النظام بحيث تُصبح العناوين التي تشير إلى نفس المجتمع الواقعي قريبة من بعضها في هذا الفضاء المشترك، بينما تُبعد الأماكن غير ذات الصلة إلى مسافات أبعد. يسمح هذا للنظام باسترجاع قائمة قصيرة من المرشحين المحتملين لكل سجل مريض جديد بسرعة.
إبقاء الذكاء الاصطناعي على مقود قصير
في المرحلة الثانية، يعمل النموذج اللغوي الكبير داخل فضاء بحث محاط بسياج محكَم. بدلًا من اختراع عنوان من الصفر، يتلقى النموذج النص المنظف الأصلي بالإضافة إلى مجموعة صغيرة من المجتمعات المرشحة التي اقترحها الرسم المعرفي. تخبر التعليمات النموذج صراحةً بأن يختار فقط من بين هؤلاء المرشحين وأن يخرج النتائج في بنية JSON ثابتة مع حقول منفصلة للمدينة، الحي، الشارع أو البلدة، والمجتمع. إذا لم يناسب أي من المرشحين—مثلاً عندما لم يتم استرجاع المجتمع الحقيقي—فإنه يُوجَّه لإرجاع قيم فارغة بدل التخمين. يقلل هذا السلوك القائم على «الرفض أولًا» بشكل حاد من خطر دخول مدخلات صحيحة المظهر لكنها خاطئة إلى سجلات المستشفى.
ما مدى فعاليته في التطبيق العملي؟
اختبر الفريق AddrKG‑LLM على عشرة آلاف عنوان مستشفى حقيقي مُجهَّل تعكس الضوضاء الواقعية: اختصارات، أحياء مفقودة، متغيرات هجائية، وحتى مدخلات غير صالحة تمامًا. قارنوا نظامهم بأدوات المطابقة النصية الكلاسيكية، ونماذج الوسم التسلسلي العميقة، والنماذج اللغوية العامة المستخدمة بطريقة حرة، وخدمة تجارية لتوحيد العناوين. على مقاييس صارمة تتطلب صحة كل حقل من حقول العنوان دفعة واحدة، تفوق AddrKG‑LLM على كل هذه النماذج المرجعية، رافعًا الدقة الكلية بأكثر من اثنتي عشرة نقطة مئوية مقارنة بنموذج BERT قوي. وبدت المكاسب واضحة بشكل خاص للعناوين المختصرة والناقصة جزئيًا، حيث تساعد البنية الهرمية المضمنة في الرسم المعرفي على ملء الفراغات. كما استكشف الباحثون كيف تتغير الأداءات مع أحجام مختلفة لنماذج اللغة ومع أعداد مختلفة من المرشحين المسترجَعِين، موضحين كيف يمكن للمستشفيات موازنة السرعة والدقة وفق احتياجاتها.
ماذا يعني هذا في الرعاية اليومية
بالنسبة لغير المتخصصين، الرسالة الأساسية أن AddrKG‑LLM يقدم طريقة لتنظيف بيانات عناوين المرضى الحيوية لكنها فوضوية، مع إبقاء السيطرة بيد البشر. من خلال ربط رسم معرفي شبيه بالخريطة بنموذج لغوي مقيد يعمل بالكامل على خوادم المستشفى، يوفر الإطار عناوين أكثر دقة وتناسقًا دون إرسال تفاصيل حساسة إلى خدمات سحابية خارجية أو السماح للذكاء الاصطناعي بالارتجال. النتيجة هي أداة عملية يمكنها تقوية رصد الأمراض، وتحسين تخطيط الموارد، ودعم عمليات المستشفيات الأكثر أمانًا وكفاءة—ببساطة عن طريق التأكد من وضع كل مريض على الخريطة بشكل موثوق.
الاستشهاد: Li, J., Pan, X. & Jia, Y. Patient address parsing via KG-aware contrastive learning and constrained on-prem LLM inference. Sci Rep 16, 8003 (2026). https://doi.org/10.1038/s41598-026-39348-z
الكلمات المفتاحية: تحليل عناوين المرضى, جودة بيانات الصحة, الرسم المعرفي, نموذج لغوي كبير, معلوماتية طبية