Clear Sky Science · ar
توقع مُقَنَّع بطوبولوجيا الحركة للهيكل العظمي وتعلّم تبايني للاعتراف بالإجراءات البشرية بالتعلّم الذاتي
تعليم الحواسيب قراءة لغة الجسد
من أجراس الأبواب الفيديوية إلى أدوات التأهيل الذكية، تحتاج العديد من الأنظمة الحديثة إلى فهم ما يفعله الأشخاص عبر مراقبة حركتهم فقط. لكن تدريب الحواسيب على تمييز الأفعال البشرية يتطلب عادة مجموعات بيانات ضخمة ومفصّلة، حيث تُعلّم كل موجة أو ركلة أو مصافحة يدوياً. تقدّم هذه الدراسة طريقة ليتعلّم الآلات من بيانات الحركة الخام وحدها، مستخدمةً الهيكل العظمي المتحرك فقط—دون تسميات، ودون وجوه، ودون فيديو ملون كامل—مما يجعل التعرّف على الأفعال أدقّ وأكثر خصوصية وأقل اعتماداً على التعليقات البشرية المكلفة.
لماذا يكفي الهيكل العظمي وحده
بدلاً من تحليل إطارات الفيديو الكاملة، تعمل الطريقة مع بيانات الهيكل العظمي ثلاثي الأبعاد: إحداثيات المفاصل الأساسية مثل الأكتاف والمرفقين والأرداف والركبتين عبر الزمن. هذه النظرة المجردة للجسم لها مزايا عدة. فهي تتجاوز قضايا الخصوصية إلى حد كبير لأن الوجوه والملابس تُستبعد، كما أنها مدمجة بما يكفي للمعالجة بكفاءة حتى للتسجيلات الطويلة. كما أن الهياكل العظمية أكثر متانة أمام الخلفيات المزدحمة وتغيرات الإضاءة التي قد تربك أنظمة الفيديو الاعتيادية. ومع ذلك، فإن معظم الأساليب المعتمدة على الهيكل العظمي لا تزال تعتمد بدرجة كبيرة على أمثلة موسومة وتكافح لالتقاط كيفية تفاعل المفاصل معاً في حركات منسقة ومعقدة.
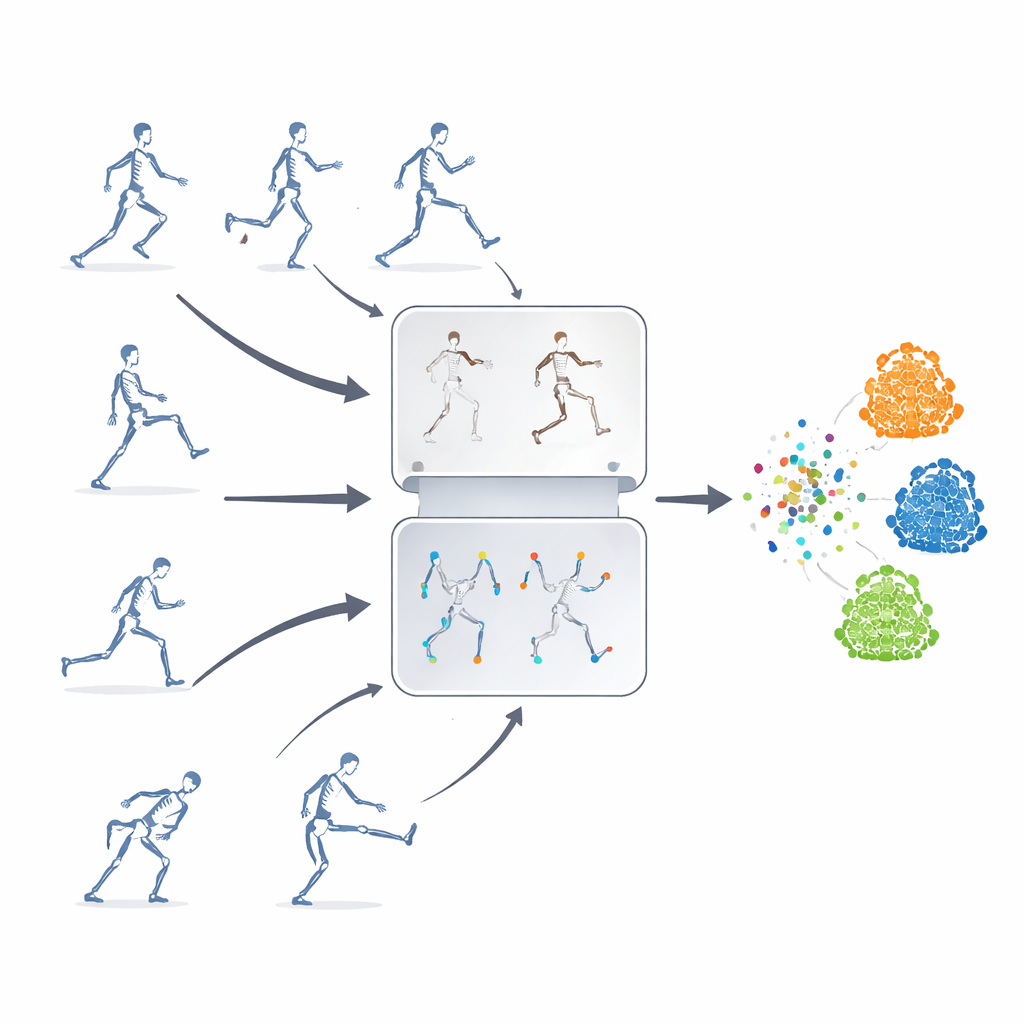
التعلّم بدون تسميات
يقترح المؤلفون إطار عمل للتعلّم الذاتي، أي أن النظام يعلّم نفسه من تسلسلات هيكلية غير موسومة. الفكرة الأساسية هي الجمع بين استراتيجيتين قويتين عادةً ما تُستخدمان بشكل منفصل. الأولى هي «التنبؤ المقنّع»، حيث تُخفى أجزاء من بيانات الهيكل العظمي عن عمد بحيث يضطر النموذج إلى تخمين الحركة المفقودة من السياق المتبقي. والثانية هي «التعلّم التبايني»، الذي يعرض للنموذج عدة نسخ معدّلة من نفس الفعل ويدرّبه على إدراك أن هذه التباينات لا تزال تمثل حركة واحدة أساسية. من خلال مزج هاتين المقاربتين، يتعلّم النظام كلاً من تفاصيل حركة المفاصل الدقيقة والمعنى الكلي للفعل.
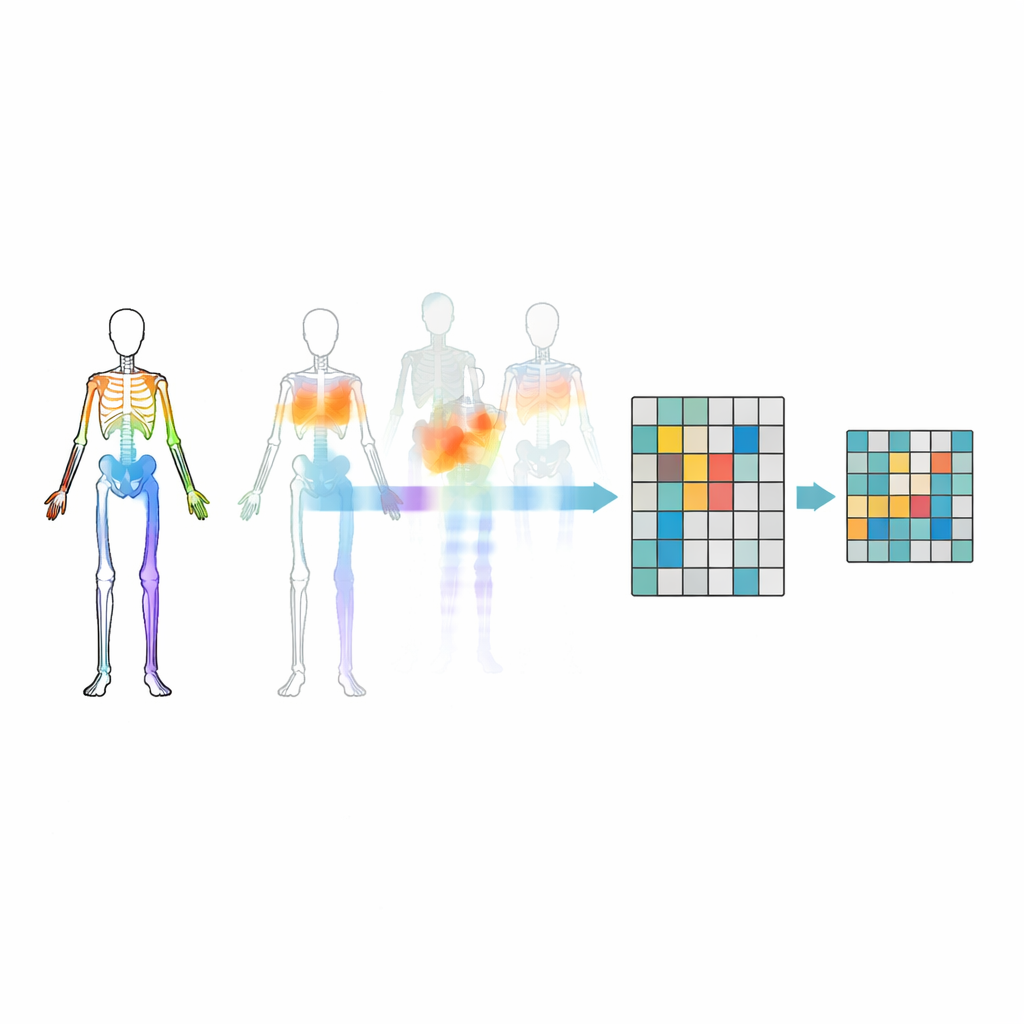
إخفاء المفاصل المناسبة
الإخفاء العشوائي للمفاصل وحده غير كافٍ—فقد يتجاهل النموذج علاقات مهمة بين أجزاء الجسم أو يركّز على الحركة الأكثر وضوحاً. لتجنّب ذلك، يقدم الباحثون استراتيجية إخفاء مبنية على طوبولوجيا الحركة. يقومون بتجميع المفاصل إلى مناطق جسدية ذات مغزى مثل الذراعين والساقين والجذع، ثم يقيسون مدى نشاط كل منطقة عبر الزمن. تسترشد قرارات الإخفاء ببنية الجسم ومدى حركة كل منطقة، بحيث تُخفى أحياناً الأجزاء النشطة بشكل كبير ويُجبر النموذج على استنتاجها من بقية الجسم. يساعد هذا الإخفاء الموجَّه النظام على تعلّم كيفية تعاون المفاصل أثناء الأفعال بدلاً من حفظ بضع حركات ملفتة فقط.
تمديد الأفعال بطرق متعددة
لتدريب الجزء التبايني من النظام، تُحوّل نفس تسلسلة الهيكل العظمي الأصلية إلى العديد من «الوجهات» المختلفة. بعض التعديلات طفيفة، مثل اقتطاع نافذة زمنية أو تشويه طفيف للمسار، بينما تكون أخرى أكثر تطرفاً، بما في ذلك الانعكاسات والدورات وضوضاء أقوى. تكشف هذه المستويات المتعددة من التضخيم النموذج عن تنوّع غني في أنماط الحركة، مما يشجعه على التركيز على البنية الأساسية للفعل بدل التفاصيل السطحية. في الوقت نفسه، يتتبّع وحدة إسقاط الميزات الموجهة بالمسار أيّ ميزات الحركة يعتمد عليها النموذج غالباً ويكبتها أثناء التدريب عن عمد. عن طريق إزالة دلائله المفضلة مؤقتاً، يُدفع النظام لاكتشاف دلائل احتياطية وتعلّم تمثيلات أكثر عمومية وقابلة للنقل.
ما مدى فعاليته؟
اختُبر الإطار على ثلاثة معايير عامة كبيرة للحركات البشرية ثلاثية الأبعاد، تغطي سلوكيات يومية وحركات متعلّقة بالطب وتفاعلات بين أشخاص. رغم أنه يستخدم بيانات مفاصل هيكلية فقط وشبكة عصبية متكررة خفيفة إلى حدٍ ما، فإن الطريقة تضاهي أو تتفوق على العديد من الأنظمة الحديثة التي تعتمد على مدخلات أو بنى أكثر تعقيداً. تبرز قوتها بشكل خاص عندما تكون التعليقات نادرة أو عندما تُحجب أجزاء من الجسم—وهي ظروف شائعة في البيئات الواقعية. ومع أن قدرتها على نقل المعرفة عبر مجموعات بيانات مختلفة تماماً لا تزال تحتاج إلى تحسين، فإن النهج يضيق الفجوة بشكل كبير بين التدريب الموسوم وغير الموسوم للتعرّف على الأفعال.
ماذا يعني هذا للأنظمة الواقعية
بالنسبة لغير المتخصصين، الخلاصة أن هذا العمل يوضح كيف يمكن للحواسيب أن تتحسن كثيراً في قراءة لغة جسد الإنسان دون أن تُعلَّم صراحةً معاني كل حركة. من خلال إخفاء وتشويه بيانات الهيكل العظمي بذكاء أثناء التدريب، يتعلّم النموذج أنماط حركة متينة تصمد أمام الإضاءة الضعيفة والتشويش البصري أو المفاصل المفقودة، وذلك بعدد أقل بكثير من الملصقات البشرية. يفتح هذا الباب أمام أنظمة تعرّف على الأفعال أكثر خصوصية وقابلة للتوسع والتكيّف لتطبيقات تتراوح من المراقبة المنزلية وتدريب الرياضة إلى التأهيل الطبي والتفاعل بين الإنسان والروبوت.
الاستشهاد: Hui, Y., Li, F., Hu, X. et al. Skeleton motion topology-masked prediction and contrastive learning for self-supervised human action recognition. Sci Rep 16, 8100 (2026). https://doi.org/10.1038/s41598-026-39330-9
الكلمات المفتاحية: التعرّف على الأفعال البشرية, بيانات الهيكل العظمي ثلاثية الأبعاد, التعلّم الذاتي, التعلّم التبايني, تحليل الحركة