Clear Sky Science · ar
إطار سيامي CNN-RNN مع تجميع متعدد المستويات لإعادة التعرف على الأشخاص في الفيديو
لماذا يهم تتبع الأشخاص عبر الكاميرات
تغطي الكاميرات المدن الحديثة، لكن هذه الكاميرات نادراً ما "تتواصل" مع بعضها البعض. عندما ينتقل شخص من زاوية شارع إلى محطة قطار، تلتقطه كاميرات مختلفة من زوايا جديدة، وتحت إضاءات متباينة، وغالباً وسط حشود. تعرف النظام تلقائياً على أنه نفس الشخص عبر مقاطع فيديو مختلفة—وهو ما يُسمى إعادة التعرف على الأشخاص المعتمدة على الفيديو—يمكن أن يساعد المحققين في تتبع الحركات بعد حادثة، دعم عمليات البحث عن مفقودين، أو تزويد تحليلات في الأماكن العامة المزدحمة. لكن تحقيق ذلك بدقة وكفاءة، خاصة على أجهزة محدودة الموارد، يمثل تحدياً تقنياً كبيراً.
دماغ أبسط لمطابقة الأشخاص أثناء الحركة
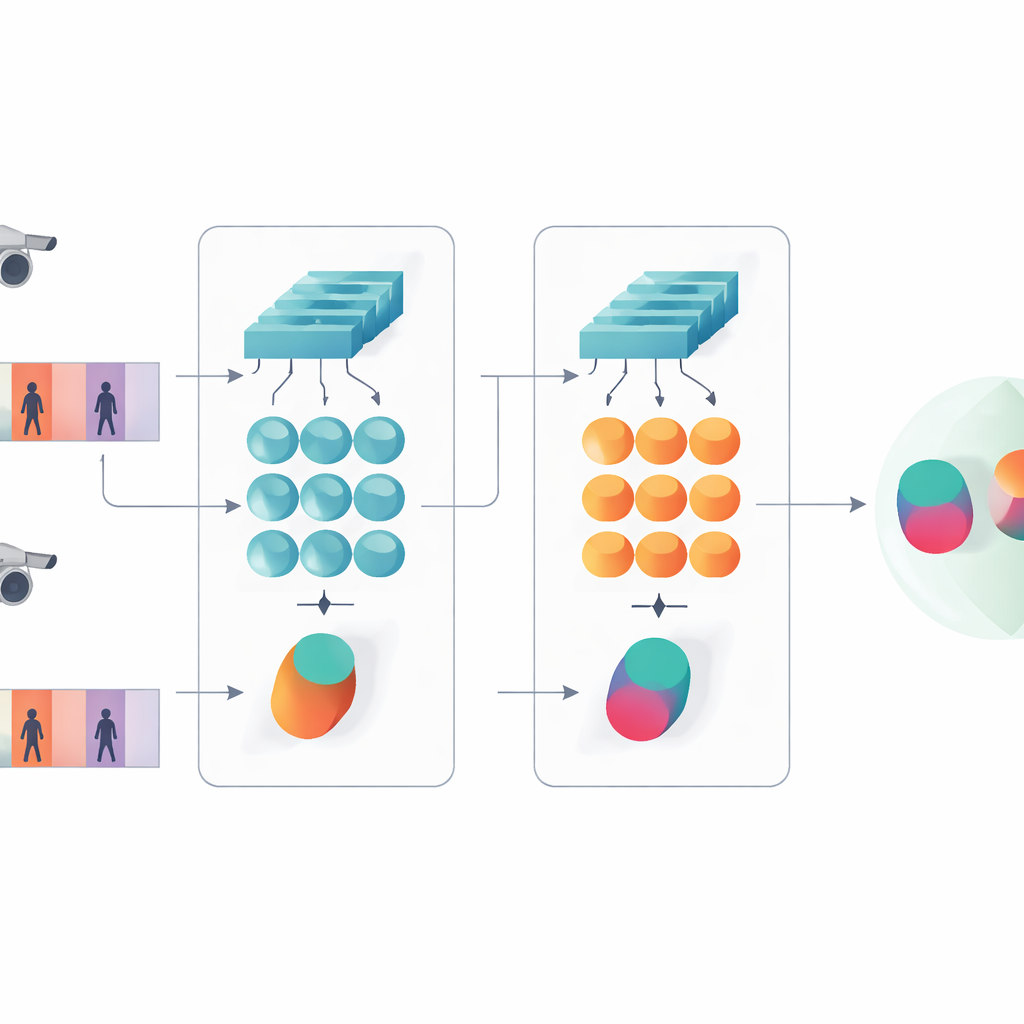
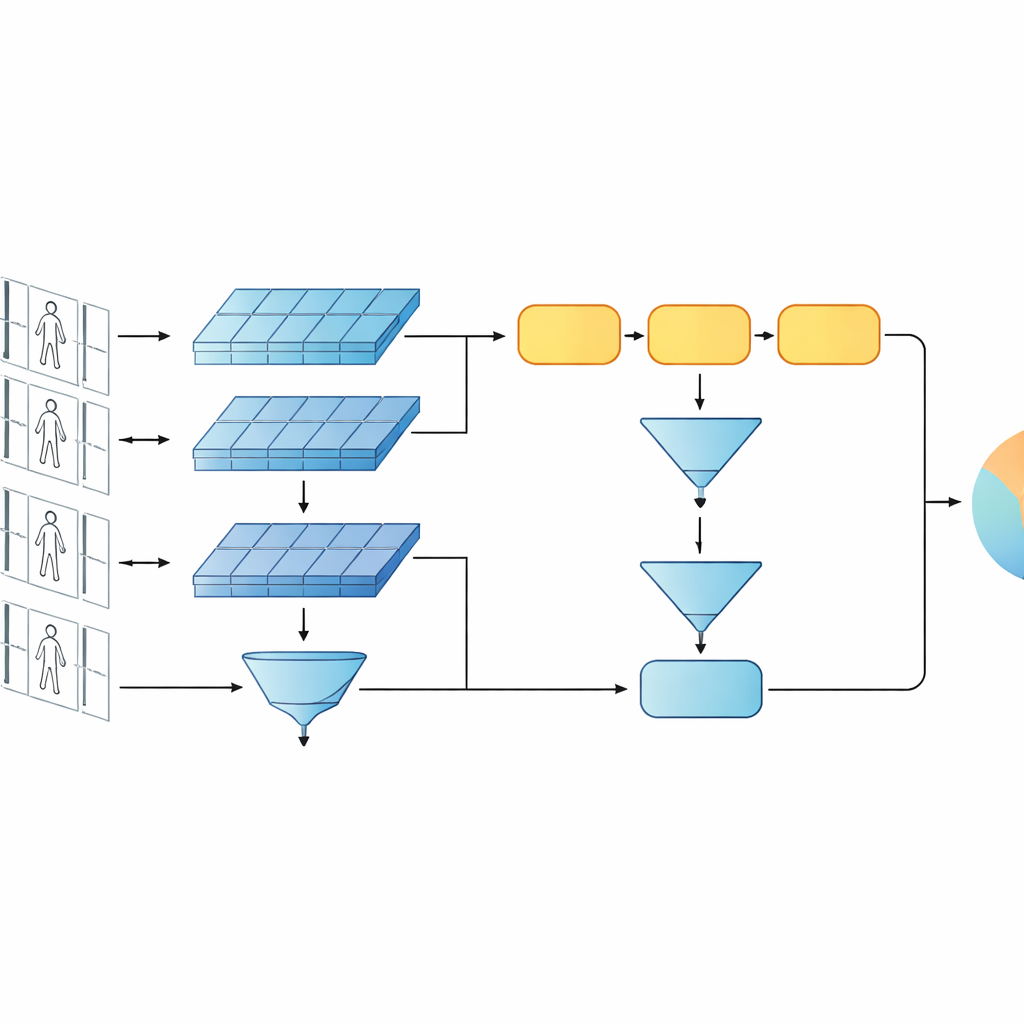
تقدّم هذه الدراسة نظام ذكاء اصطناعي مدمج مصمم لتحديد ما إذا كان مقطعا فيديو قصيران يظهران نفس الشخص. بدلاً من اتباع اتّجاه اليوم نحو الشبكات العميقة جداً أو الشبكات المعتمدة على المحولات، يبني المؤلفون على تصميم أخف يجمع عنصرين كلاسيكيين: شبكة تلافيفية تحلل كل إطار فيديو، ووحدة تكرارية ذات بوابات (GRU) تتتبّع كيف يتغير المظهر مع الزمن. يتم ترتيب هذين الفرعين بتصميم سيامي—نسخان توأمان من نفس الشبكة يشتركان في كل إعداداتهما الداخلية. يعالج كل توأم تسلسل فيديو واحد، ويتعلم النظام إنتاج توقيعات داخلية متشابهة لمقاطع لنفس الشخص وتوقيعات مختلفة بوضوح لأشخاص مختلفين.
رؤية التفاصيل والأنماط عبر الزمن
فكرة رئيسية في العمل هي أن التعرف لا ينبغي أن يعتمد فقط على أعمق السمات وأكثرها تجريداً في الشبكة. الطبقات الأولى ما زالت تحتوي على تفاصيل بصرية حادة مثل نسيج سترة، خطوط على البنطال، أو ملامح حقيبة الظهر—إشارات غالباً ما تصمد أمام تغيّر زاوية الكاميرا. لذلك يحافظ النموذج المقترح على مستوىين من الوصف. يقوم فرع واحد بتجميع ميزات الطبقات المبكرة عبر جميع الإطارات لتلخيص القوام الدقيق والأنماط المحلية. أما الفرع الآخر فيغذي الميزات المتأخرة إلى الـGRU، الذي يتابع التسلسل إطاراً تلو الآخر ثم يُجرِي متوسطاً للحالات الداخلية عبر الزمن. تمنع خطوة المتوسط هذه المبالغة في التأكيد على الإطارات الأخيرة وبدلاً من ذلك تلتقط رؤية إجماعية لكيف يظهر الشخص ويتحرك عبر المقطع بأكمله.
تدريب الشبكات التوأمية على الاتفاق والتصنيف
لتعليم النظام ما يهم، يجمع المؤلفون بين هدفين للتدريب. أولاً، هدف التحقق يشجع الفروع التوأمية على إنتاج توقيعات متقاربة لمقاطع الفيديو لنفس الشخص وتوقيعات متباعدة لأشخاص مختلفين. ثانياً، هدف التصنيف يطلب من الشبكة تعيين كل مقطع تدريبي إلى هوية محددة. من خلال تحسين كلا الهدفين معاً، وعلى مستويي الخصائص المنخفض والعالي، يتعلم النموذج أوصافاً داخلية ليست فقط مميزة بين الأشخاص ولكنها أيضاً مقاومة للضوضاء والحجب والإطارات ذات الجودة الضعيفة أحياناً. يبقى التصميم سطحيًا من حيث الطبقات والمعلمات، مما يساعده على تجنب الإفراط في التكيّف مع مجموعات بيانات فيديو صغيرة نسبياً.
الاختبار على فيديوهات على طراز المراقبة الحقيقية
تم تقييم الإطار على معيارين مستخدمين على نطاق واسع للفيديو، PRID-2011 وiLIDS-VID، واللذان يحتويان على تسلسلات مشي قصيرة لمئات الأفراد مأخوذة من زوجين من الكاميرات المنفصلة. يدرس العمل بعناية خيارات تصميم مختلفة: استبدال الـGRU بوحدات تكرارية أخرى، تغيير عدد الطبقات التكرارية المستخدمة، تعديل طرق تجميع الميزات عبر الزمن، وتشغيل أو إيقاف الفروع ذات المستوى المنخفض أو العالي. عبر هذه الاختبارات، قدمت GRU بطبقة واحدة مع التجميع المتوسط والإعداد متعدد المستويات أفضل دقة باستمرار. يضاهي النموذج أو يتفوق على العديد من الأنظمة التكرارية والسيامية الأكثر تعقيداً، ويؤدي أداءً تنافسياً مع بعض التصاميم المعتمدة على الانتباه، مع استخدام عدد أقل بكثير من المعلمات والحسابات.
الكفاءة لنشرها في العالم الحقيقي
إلى جانب الدقة، يركز العمل على الجوانب العملية. يحتوي كامل الشبكة على نحو مليون إلى مليوني معلمة قابلة للتدريب فقط—أوامر من حيث الحجم أقل بكثير من الأطر الخلفية الشعبية المعتمدة على الشبكات المتبقية العميقة أو المحولات—ويحتاج إلى جزء صغير من تكلفة الحساب لكل إطار مقارنةً بها. هذا يجعله أكثر ملاءمة للنشر على أجهزة ذات ذاكرة وقدرة معالجة محدودة، مثل خوادم الحافة القريبة من الكاميرات. تُظهر التجارب أيضاً أن تسلسلات المعرض الأطول، حيث يرى النظام المزيد من إطارات كل شخص مخزن، تحسّن التعرف بشكل كبير، وإن كان ذلك مع زيادة خطية في تكلفة المعالجة. يجادل المؤلفون أن مثل هذه البنى المدمجة والمصممة بعناية يمكن أن توفّر إعادة تعرّف موثوقة للأشخاص من دون التكلفة الباهظة لنماذج اليوم الأكبر حجماً.
ما الذي يعنيه هذا لأنظمة المراقبة اليومية
بعبارة بسيطة، تُظهر هذه الورقة أن التصميم الذكي يمكن أن يتفوق على الحجم وحده: من خلال الجمع بين تحليل صور سطحي، ونمذجة تسلسلية خفيفة الوزن، ونظرة ثنائية المستويات للتشابه البصري، يصبح من الممكن تتبع من هو من عبر الكاميرات بدرجة عالية من الاعتمادية مع إبقاء النموذج صغيراً وسريعاً. بالنسبة للأنظمة المستقبلية التي يجب أن تعمل على العديد من الكاميرات، غالباً بميزانيات صارمة للعتاد والطاقة، قد يساعد هذا النهج الفعّال ومتعدد المستويات في إدخال تحليلات فيديو أكثر قدرة ومسؤولية إلى الاستخدام العملي.
الاستشهاد: Wang, YK., Pan, TM. & Sun, CP. A CNN-RNN Siamese framework with multi-level aggregation for video-based person re-identification. Sci Rep 16, 8224 (2026). https://doi.org/10.1038/s41598-026-39277-x
الكلمات المفتاحية: إعادة التعرف على الأشخاص, مراقبة بالفيديو, الشبكات العصبية السيامية, النمذجة الزمنية, التعلّم العميق الفعال