Clear Sky Science · ar
نهج لمعالجة مجموعات البيانات غير المتوازنة باستخدام إزاحة الحدود
لماذا تهم الحالات النادرة في البيانات اليومية
من الاحتيال المصرفي والتشخيص الطبي إلى التنبؤ بمغادرة العملاء، يعتمد كثير من القرارات التي نطلب من الحواسيب اتخاذها على اكتشاف أحداث نادرة ولكنها حاسمة. في معظم مجموعات البيانات الحقيقية، تكون هذه الحالات المهمة أقلية كبيرة مقارنة بالحالات العادية. النموذج الذي يرى «روتين الأعمال» في الغالب قد يصبح أعمى عن الحالات التي نهتم بها أكثر. تقدم هذه الورقة طريقة جديدة لإعادة توازن مثل هذه البيانات المتحيزة حتى تولي خوارزميات التعلم الاهتمام المناسب للحالات النادرة ذات التأثير الكبير.
الفخ الخفي للبيانات المائلة
عندما تفوق نوع من الأمثلة نوعًا آخر بكثير، تميل طرق التعلم الآلي القياسية إلى التركيز على الفئة الكبرى وتهميش الفئة الصغرى بصمت. قد يصنف نظام التنبؤ بمغادرة العملاء، على سبيل المثال، معظم الناس على أنهم عملاء مخلصون ويظل يحقق دقة عالية ببساطة لأن المغادرين الفعليين قليلون جدًا. تظهر مشكلات مماثلة في كشف الحوادث ومراقبة الاحتيال والفحص الطبي، حيث تكون الحالات الإيجابية نادرة لكن تفويتها مكلف. تنقسم الطرق التقليدية لإصلاح ذلك إلى معسكرين: تعديل خوارزمية التعلم لتولي اهتمامًا أكبر للأقلية، أو إعادة تشكيل البيانات نفسها إما بإزالة بعض حالات الأغلبية (العينة الناقصة) أو بإنشاء أمثلة إضافية للأقلية (العينة الزائدة). أدوات العيّنات الزائدة الشائعة مثل SMOTE تولد أمثلة أقلية تركيبية، لكنها قد تملأ عن غير قصد منطقة الحدود الحساسة حيث يلتقي الفئتان.
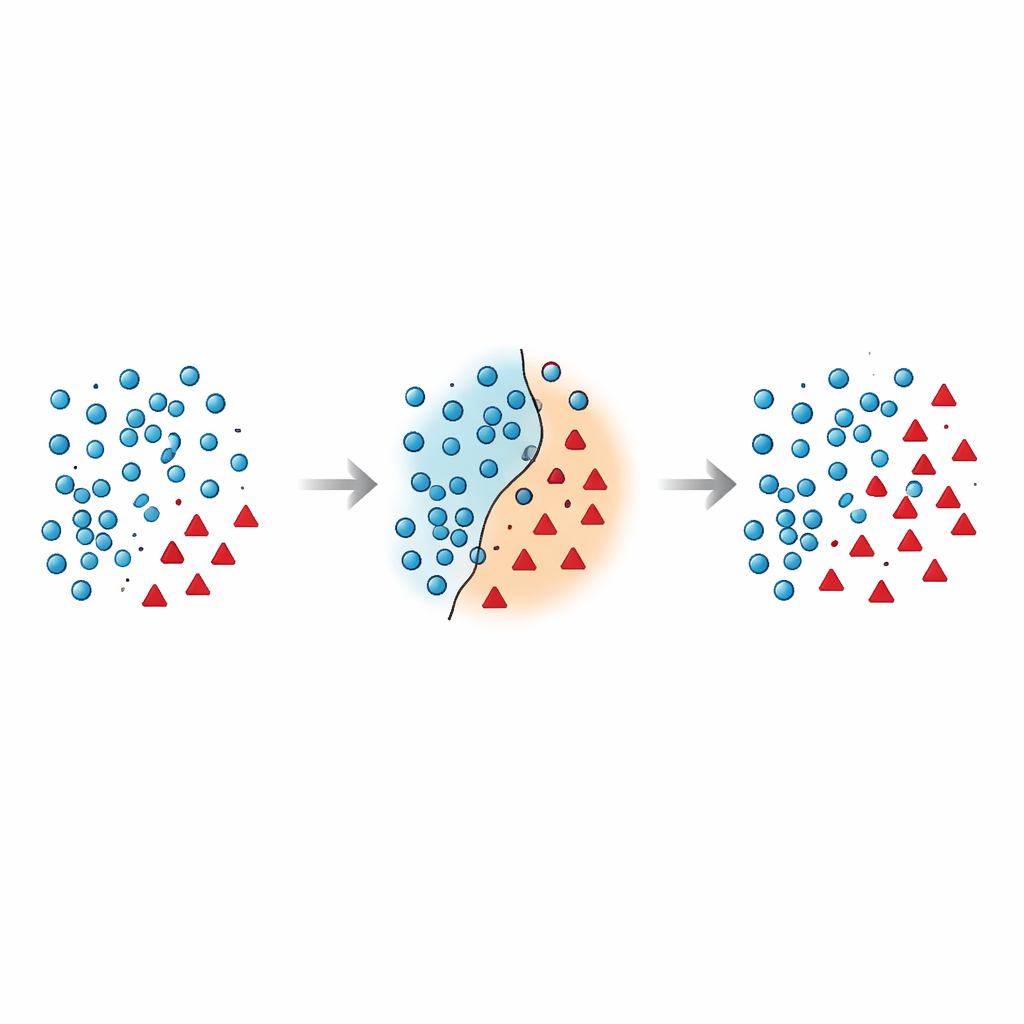
لماذا الحدود بين المجموعات هشة جدًا
يجادل المؤلفون أن أخطر الأخطاء تحدث بالقرب من حد القرار — المنطقة التي تتداخل فيها حالات الأغلبية والأقلية في فضاء الميزات. العديد من التقنيات الحالية إما تضيف نقاطًا تركيبية في هذه المنطقة الخطرة دون تنظيفها، أو تحذف بيانات بشكل قاسٍ وتزيل أمثلة مفيدة عن غير قصد. حاولت أبحاث حديثة ترويض هذا باستخدام قيود هندسية أو تقديرات الكثافة المحلية أو مرشحات الضوضاء، ومع ذلك فإن معظم الطرق لا تزال تعامل نقاط الأقلية في مواضعها ونادرًا ما تعيد التفكير في كيفية التعامل مع نقاط الأغلبية القريبة من تلك الحدود. هذا يترك مشكلة قائمة: عينات متداخلة وملوثة تشتت المُصنّف وتؤدي إلى تنبؤات غير مستقرة، خاصة على بيانات جديدة.
طريقة من خطوتين لترتيب الحدود
تقدم الورقة طريقة Borderline Shifting Oversampling (BSO)، وهي طريقة لإعادة تشكيل البيانات على مرحلتين تستهدف صراحة منطقة الحدود الإشكالية هذه. أولاً، تفحص الجوار لكل مثال من أغلبية لتقرر ما إذا كان يقع في منطقة آمنة، على الحدود، أو في موضع خاطئ بوضوح (ضوضاء). تُعاد تصنيف نقاط الأغلبية المحاطة بجيران من الأقلية نحو جانب الأقلية أو توشَّم كضوضاء وتُزال، مما ينظف ويزيح الحد بحيث يعكس النمط الكامن بشكل أفضل. في المرحلة الثانية، يولد الأسلوب نقاطًا تركيبية جديدة للأقلية باستخدام استيفاء شبيه بـ SMOTE، ولكن فقط حول عينات الأقلية القريبة من الحد المنقّح. من خلال تركيز البيانات الجديدة حيث تكون أكثر إفادة وتجنب البقع الملوثة بوضوح، يبني BSO مجموعة تدريب أكثر توازنًا من حيث الحجم وأنظف من حيث البنية.
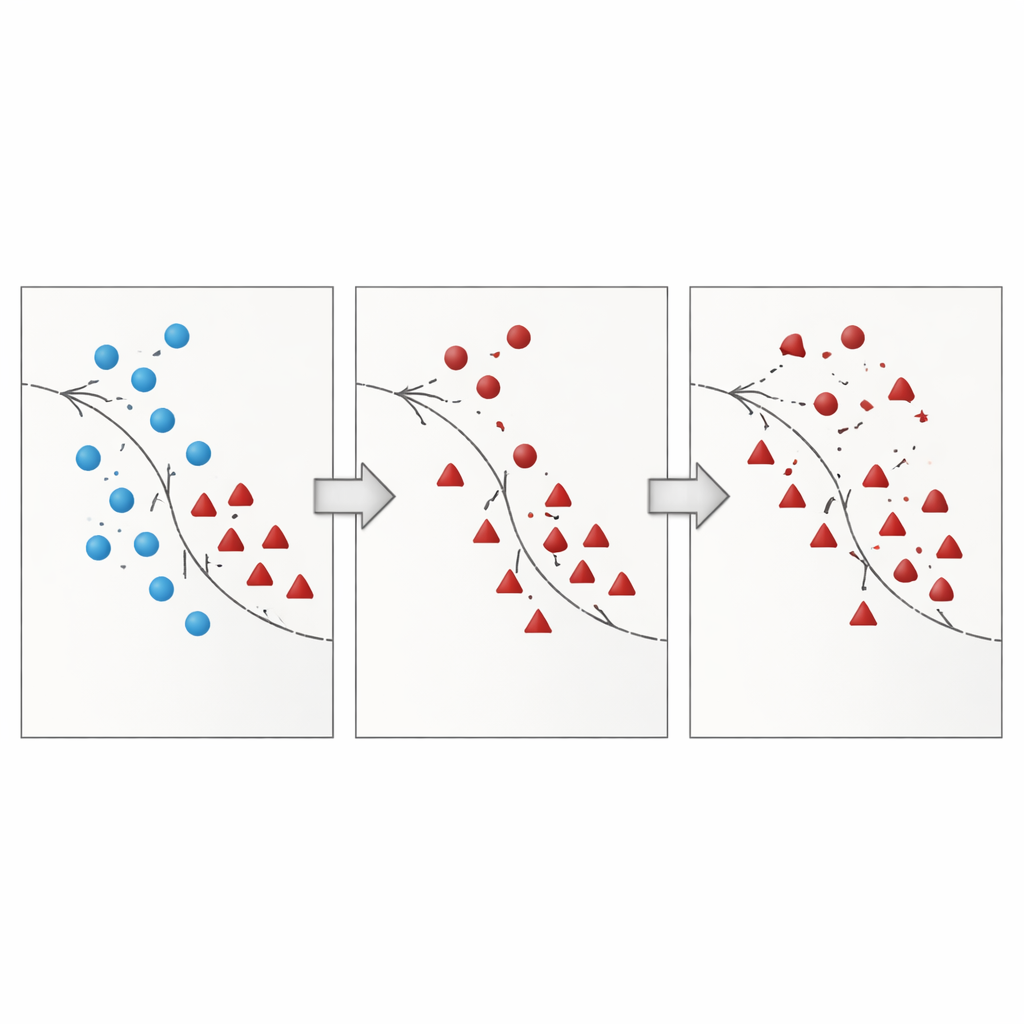
وضع الطريقة على المحك
لاختبار فعالية هذا النهج عمليًا، قيّم الباحثون BSO على 30 مجموعة بيانات معيارية ذات درجات تفاوت وتداخل مختلفة. قارنوه مع سبعة بدائل مستخدمة على نطاق واسع، بما في ذلك العيّنات العشوائية الزائدة والناقصة، SMOTE، Borderline‑SMOTE، NearMiss، وطريقتين مختلطتين تمزجان العيّنات الزائدة مع تنظيف الضوضاء (SMOTE‑Tomek وSMOTE‑ENN). تم تدريب ثلاثة مصنفات شائعة — آلات الدعم الناقلة، بايز البسيط، وغابات عشوائية — على كل مجموعة بيانات معاد عينتها. بدلًا من الاعتماد على الدقة الخام، استخدمت الدراسة مقاييس أكثر إفادة في حالات الاختلال مثل F1‑score، G‑mean، الاستدعاء، الدقة، ومساحة تحت منحنى ROC (AUC). عبر معظم المجموعات والمصنفات، قدم BSO درجات أعلى أو قابلة للمقارنة مع تباين أقل، مما يعني أن فوائده كانت ثابتة بدلاً من أن تكون مرتبطة بنموذج أو إعداد معين.
ماذا يعني هذا للقرارات في العالم الحقيقي
بمصطلحات يومية، يعمل نهج Borderline Shifting كمحرر دقيق للبيانات المعقدة: ينظف الأمثلة المربكة بالقرب من خط التقسيم بين الفئات ثم يضيف عددًا كافيًا من حالات الأقلية الواقعية في الأماكن المناسبة. النتيجة أن خوارزميات التعلم تصبح أفضل في التعرف على الأحداث النادرة ولكن المهمة دون أن تضللها التداخلات الملوثة. لتطبيقات مثل كشف الاحتيال، التنبؤ بالحوادث، أو الفرز الطبي — حيث قد يكون تفويت حالة من الأقلية مكلفًا — يقدم هذا الأسلوب وسيلة عملية لجعل النماذج أكثر عدلاً وحساسية وموثوقية، مع إضافة عبء حسابي متواضع فقط.
الاستشهاد: Malhat, M.G., Elsobky, A.M., Keshk, A.E. et al. An approach for handling imbalanced datasets using borderline shifting. Sci Rep 16, 8264 (2026). https://doi.org/10.1038/s41598-026-39118-x
الكلمات المفتاحية: اختلال توازن الفئات, إعادة العينات الزائدة, حد القرار, كشف الشواذ, صلابة تعلّم الآلة