Clear Sky Science · ar
نماذج اللغة الكبيرة تُظهر تأثيرات شبيهة بمخطط دننغ-كروجَر في التحقق من الحقائق متعدد اللغات
لماذا يهم التحقق الذكي من الحقائق الجميع
تنتشر المعلومات المضلِّلة اليوم أسرع من أي وقت مضى، وتشكل ما يعتقده الناس بشأن الصحة والسياسة والعلوم والحياة اليومية. بدأت العديد من المنصات وغرف الأخبار تعتمد على الذكاء الاصطناعي — وبخاصة نماذج اللغة الكبيرة (LLMs) — للمساعدة في التثبت مما إذا كانت الادعاءات الفيروسية صحيحة أم خاطئة. تطرح هذه الدراسة سؤالاً بسيطاً لكن جوهرياً: عندما نسمح لهذه الأنظمة بحكم الحقائق، كم مرة تكون محقة، ومدى اليقين الذي تظهره، وهل يختلف ذلك عبر لغات ومناطق العالم؟
كيف اختبر الباحثون الذكاء الاصطناعي مقابل الشائعات الواقعية
بدلاً من اختراع أمثلة مصطنعة، بنى المؤلفون اختباراتهم من 5000 ادعاء حقيقي سبق أن حققت فيها منظمات التحقق المهنية حول العالم. غطت هذه الادعاءات 47 لغة وجاءت من كل من الشمال العالمي والجنوب العالمي، لتعكس الواقع المعقد والمتعدد الثقافات للشائعات على الإنترنت. شُمِلت فقط العبارات التي لديها أحكام «صحيحة» أو «خاطئة» واضحة — تم الاتفاق عليها من قبل عدة محقِّقين — فأنشأ ذلك أرضية حقيقة قوية للمقارنة.
ثم شغّلوا تسعة نماذج لغوية مستخدمة على نطاق واسع، بدءاً من الأنظمة مفتوحة المصدر الصغيرة إلى الأنظمة التجارية المتقدمة، على كل ادعاء. لمحاكاة الطريقة التي يتحدث بها الناس فعلياً مع برامج الدردشة، كانت معظم الحواشي بسيطة مثل «هل هذا صحيح؟» أو «هل هذا خاطئ؟»، مكتوبة بنفس لغة الادعاء. إعداد رابع أكثر احترافية استخدم تعليمات مفصلة باللغة الإنجليزية حوَّلت النموذج إلى مدقِّق حقائق افتراضي وطلبت مخرجات منظمة. قرأ المعلِّقون البشريون إجابات النماذج بعناية وصنّفوها باعتبارها تقول إن الادعاء صحيح أو خاطئ أو ترفض إصدار حكم واضح.
قياس ليس فقط الصواب أو الخطأ، بل متى يقول «لا أعلم»
قام الفريق بأكثر من إحاطة النتائج بعدد الإجابات الصحيحة والخاطئة. استخدموا ثلاثة مقاييس رئيسية لالتقاط سلوك النماذج. أولاً، «الدقة الانتقائية» نظرَت في عدد المرات التي يكون فيها النموذج محقاً عندما يتخذ موقفاً ويعلن أن الادعاء صحيح أو خاطئ. ثانياً، «دقة صديقة للامتناع» اعتبرت أنه مقبول، بل مرغوب، أن يعترف النموذج بعدم اليقين بدلاً من التخمين، وهو أمر حيوي في مجالات حساسة مثل الطب أو الانتخابات. ثالثاً، «معدل اليقين» تتبّع عدد المرات التي أجاد فيها النموذج إجابة قاطعة، ليكون بذلك بديلاً تقريبياً عن سلوكه الواثق.
رفع الإعداد الاحترافي، بتوجيهاته خطوة بخطوة، الدقة باستمرار عبر جميع النماذج. لكنه كشف أيضاً عن مقايضة: فالنماذج الصغيرة صارت غالباً أكثر حسمًا دون أن تصبح أكثر موثوقية، بينما استخدمت النماذج الأكبر البنية لتقديم إجابات أقل عدداً لكن أفضل جودة. أدت الحواشي اليومية الشبيهة بالدردشة إلى سلوك أكثر حذراً، خصوصاً في النماذج الأضعف، لكنها قلّلت إلى حد ما من دقتها.
عندما تتصرف الأنظمة الأقل قدرة بثقة أكبر
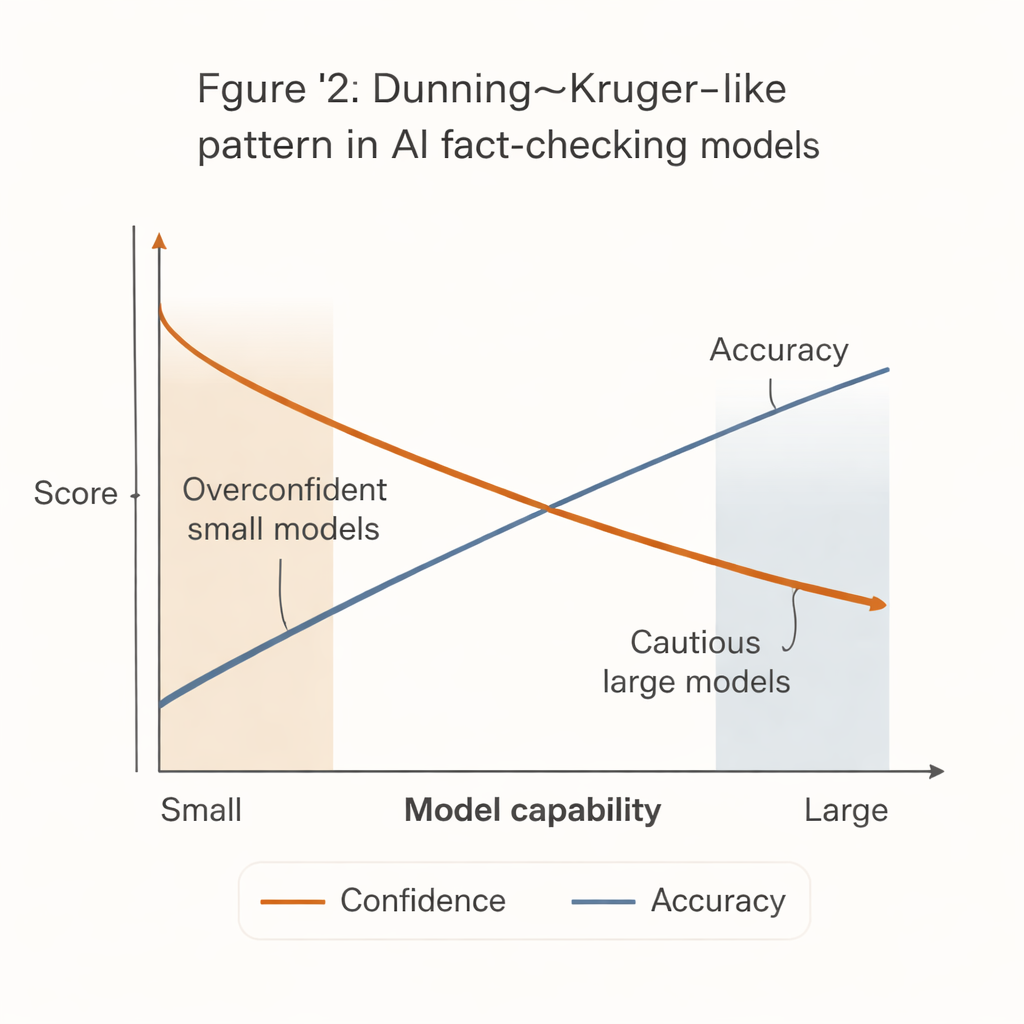
ظهر نمط لافت يعكس تأثير دننغ-كروجَر المعروف في سيكولوجيا البشر: كانت الأنظمة الأقل قدرة هي الأكثر ثقة. الميل إلى أن تصدر النماذج الصغيرة والرخيصة أحكاماً حاسمة على غالبية الادعاءات، لكن بدقة أقل بشكل ملحوظ. بالمقابل، كانت أقوى النماذج — مثل الإصدارات المتقدمة من GPT — أدق بكثير عندما تُصرّ على حكم، لكنها أكثر ميلاً للامتناع، خاصة في العبارات الصعبة أو الغامضة.
لهذا «الفجوة بين الثقة والكفاءة» عواقب واقعية. العديد من غرف الأخبار ذات الميزانيات المحدودة والمنظمات المجتمعية ومراكز التحقق المحلية لا تستطيع تحمل تكلفة أقوى أنظمة الذكاء الاصطناعي. من المرجح أن تعتمد نماذج أصغر وأرخص تبدو حاسمة لكنها غالباً ما تكون خاطئة أكثر. إذا وُصّلت هذه الأدوات إلى سير العمل أو أنظمة إدارة المجتمعات دون ضوابط حذرة، فقد تُضخِّم المعلومات المضلِّلة عن طريق إنتاج تحققَات واثقة لكنها غير صحيحة.
أداء غير متكافئ عبر اللغات والمناطق
تكشف الدراسة أيضاً أن هذه الأنظمة لا تؤدي أداءً متساوياً للجميع. عبر عدة لغات كبرى، أدركت النماذج أداءً أفضل بشكل عام على الادعاءات الإنجليزية وأضعف قليلاً على البرتغالية والهندية. كانت النماذج الأكبر تميل إلى الرد بحذر أكثر في اللغات غير الإنجليزية، لكنها ما تزال تتفوق على الصغيرة من حيث الدقة. عندما قارن المؤلفون الادعاءات المرتبطة بالشمال العالمي والجنوب العالمي، تعثرت معظم النماذج أكثر على الأخيرة. غالباً ما بقيت الأنظمة الأصغر واثقة بينما كانت دقتها في تراجع، في حين أظهرت النماذج الكبيرة انخفاضات أكبر في معدل اليقين لكنه مصحوب بانخفاضات أصغر في الصواب، مما يوحي بأنها شعرت بعدم اليقين وامتثلت للامتناع.
ما يعنيه هذا لمستقبل أدوات الذكاء الاصطناعي الموثوقة
بالنسبة لغير المتخصص، الرسالة الأساسية واضحة: مدقِّقو الحقائق المعتمدون على الذكاء الاصطناعي اليوم ليسوا متساوين، وأكثرها سهولة في الوصول قد تكون الأكثر تضليلاً. يمكن للنماذج القوية أن تكون حذرة ودقيقة، لكنها مكلفة وأحياناً مترددة أكثر من اللازم. النماذج الأضعف جريئة لكنها أكثر عرضة للخطأ، خصوصاً خارج الإنجليزية وفي القصص القادمة من الجنوب العالمي. يجادل المؤلفون بأن الذكاء الاصطناعي يجب أن يدعم، لا يحل محل، مدققي الحقائق البشر، وأن تُجبر سياسات وتصميمات أفضل على معايرة أدق — تعليم الأنظمة متى تلتزم الصمت — وتوفير وصول أكثر عدالة إلى أدوات عالية الجودة. وإلا فقد تعمّق نفس التكنولوجيا التي بُنيت لمكافحة المعلومات المضلِّلة عدم المساواة المعلوماتية التي تهدف إلى حلها.
الاستشهاد: Qazi, I.A., Khan, Z., Ghani, A. et al. Large language models show Dunning-Kruger-like effects in multilingual fact-checking. Sci Rep 16, 7594 (2026). https://doi.org/10.1038/s41598-026-39046-w
الكلمات المفتاحية: المعلومات المضلِّلة, التحقق من الحقائق, نماذج اللغة الكبيرة, ثقة الذكاء الاصطناعي, التحيّز متعدد اللغات