Clear Sky Science · ar
إطار تعلم عميق ثنائي المسار للتعرف المستمر على لغة الإشارة لتعزيز إمكانية الوصول في منطقة حائل
سد فجوة التواصل
بالنسبة لكثير من الصم، تُعد لغة الإشارة الوسيلة الأساسية للتواصل، ومع ذلك لا تزال معظم الحواسيب والهواتف والخدمات العامة غير قادرة على فهمها. تقدم هذه الورقة نظام ذكاء اصطناعي جديداً يمكنه مشاهدة التوقيع المستمر في الفيديو وتحويله إلى كلمات مكتوبة بدقة أكبر. من خلال الانتباه ليس فقط إلى حركات اليدين بل أيضاً إلى موضع الرأس والمؤشرات الوجهية، يسعى النظام لجعل التواصل المعتمد على التقنية أكثر طبيعية ويسراً—خاصة لمجتمعات الصم في منطقة حائل بالمملكة العربية السعودية، حيث لا يزال الدعم الرقمي محدوداً. 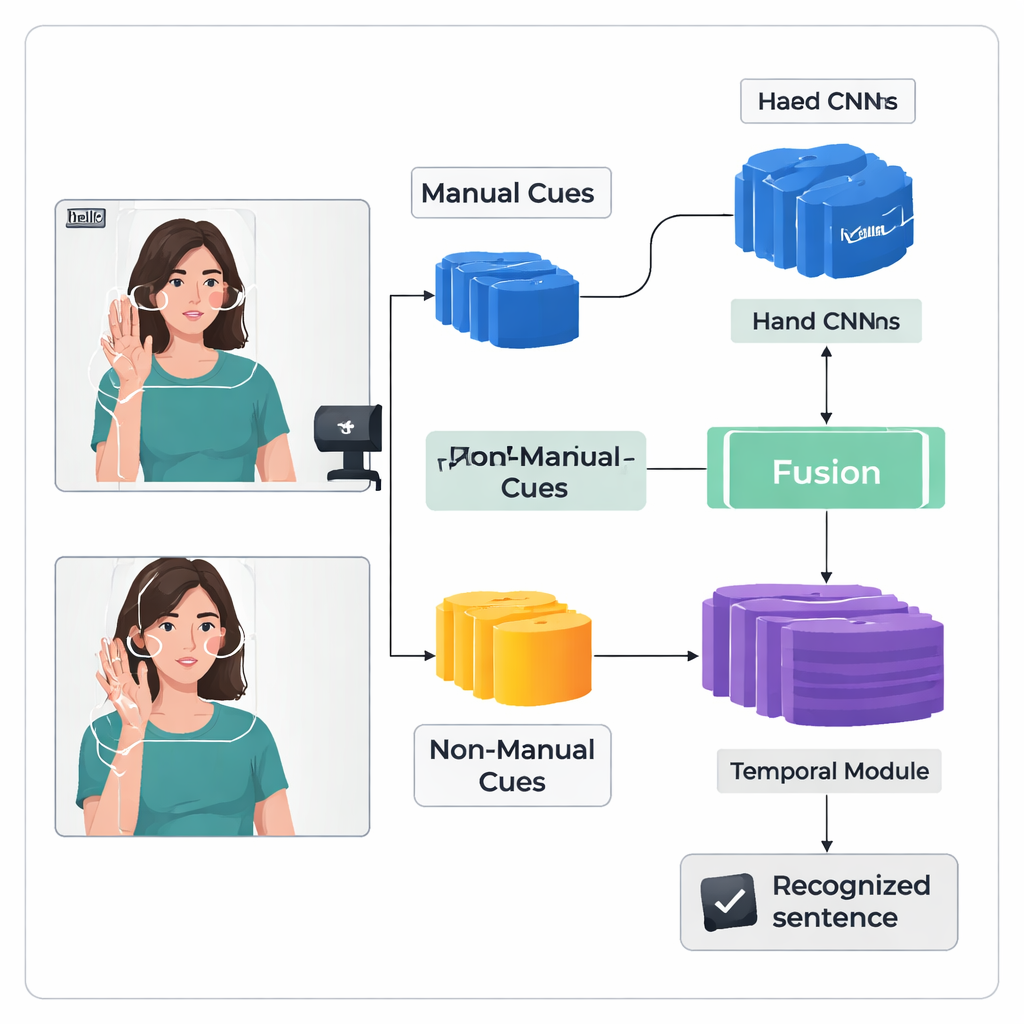
لماذا اليدان ليستا كافيتين
لغات الإشارة أنظمة غنية ومعقدة تستخدم الجزء العلوي من الجسم بكامله. لا تأتي المعاني فقط من كيفية تحرك اليدين، بل أيضاً من تعابير الوجه، واتجاه نظر المُشير، وكيف يميل الرأس أو يومئ. يمكن أن تشير هذه الإشارات غير المتعلقة باليدين إلى الاستفهام، النفي، التأكيد أو العاطفة. البشر يقرؤون كل ذلك بسهولة، لكن معظم أنظمة الحاسوب للتعرف على لغة الإشارة تركز تقريباً بالكامل على اليدين. هذا الاختصار يبسط التدريب لكنه يفقد دلائل مهمة، خصوصاً عندما تتدفق الإشارات معاً في جمل مستمرة وسريعة بدلاً من كلمات منعزلة.
مساران يعملان بالتوازي
يعرض المؤلفون إطار تعلم عميق «ثنائي المسار» باسم TS-CNN يعالج اليدين والرأس بشكل منفصل ثم يدمجهما. يركز أحد المسارات على صور مقصوصة ليدَي المُشير، ليتعلم أنماط الشكل والحركة والموقع. يستقبل المسار الآخر خريطة مضغوطة للوجه والرأس، مشتقة من نقاط معالم وتقديرات وضعية الرأس. كلا المسارين يستخدم نوعاً شائعاً من شبكات الرؤية لتحويل كل إطار فيديو إلى ميزات رقمية. يقوم النظام بعد ذلك بدمج هذه الميزات إطاراً بإطار، مع احترام حقيقة أن دلائل اليد والرأس تظهر في الوقت نفسه أثناء التوقيع الحقيقي. تنظر وحدة زمنية لاحقة عبر عدة إطارات لفهم كيف تتكشف الإشارات عبر الزمن، وتنتج طبقة متكررة متتابعة من الوحدات المتوقعة للعلامات أو «الغلو�سس».
تحسين ذاكرة النظام للعلامات
التعرف على التوقيع المستمر صعب لأن بيانات التدريب محدودة وتندمج العلامات معاً دون تسميات واضحة إطاراً بإطار. للتعامل مع ذلك، يضيف المؤلفون وحدة تعزيز الميزات التي تمنح الشبكة توجيهاً إضافياً أثناء التدريب. تقنية واسعة الاستخدام توائم تسلسل الغلوس المتوقع مع الفيديو، منتجة مواقع محتملة لكل غلوس عبر الزمن. تأخذ الوحدة الجديدة هذه الاقتراحات التوافقية وتستخدمها كمشرف مباشر لصقل التمثيلات الداخلية لميزات الغلوس. ببساطة، يتعلم النظام ليس فقط إخراج التسلسل الصحيح، بل أيضاً بناء «ذاكرات» داخلية أوضح وأكثر اتساقاً لما تبدو عليه كل علامة عبر مقاطع فيديو مختلفة.
تجريب المنهج
يقيم الفريق TS-CNN على مجموعتي بيانات معروفتين في لغة الإشارة: RWTH-PHOENIX-Weather 2014 للغة الإشارة الألمانية وCSL Split II للغة الإشارة الصينية. يقيسون الأداء باستخدام معدل خطأ الكلمة، وهو مقياس قياسي مشابه لما يُستخدم في التعرف على الكلام. بالمقارنة مع خط أساس ينظر إلى حركات اليد فقط، يؤدي إضافة معلومات وضعية الرأس إلى خفض الأخطاء بنحو 4 نقاط مئوية على البيانات الألمانية وحوالي 3–4 نقاط على البيانات الصينية. يؤدي إضافة وحدة تعزيز الميزات إلى مكاسب أكبر، حيث تقل الأخطاء بنحو 10–14 في المئة إجمالاً على كلتا المجموعتين. كما يعمل النظام بكفاءة، ويصل إلى سرعات زمن حقيقية على معالج رسومي حديث، وهو أمر حاسم إذا أُريد استخدامه في الترجمة الحية أو أدوات الهواتف المحمولة. 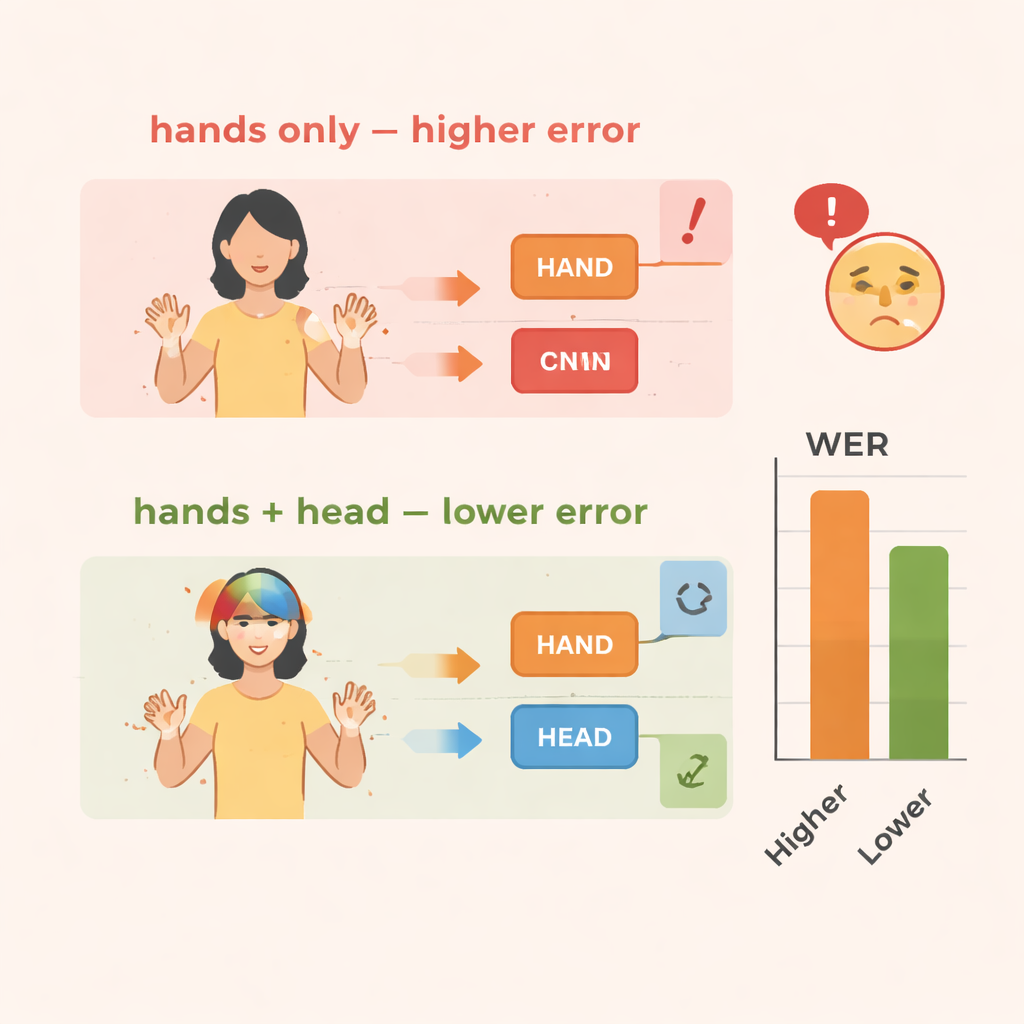
ما معنى هذا في الحياة اليومية
بعبارات يومية، تُظهر هذه الدراسة أن الحواسيب يمكنها فهم لغة الإشارة بشكل أكثر موثوقية عندما تراقب المُشير بأكمله، وليس اليدين فقط. من خلال نمذجة حركات الرأس والمؤشرات الوجهية جنباً إلى جنب مع حركات اليدين، وبواسطة تحسين كيفية التعلم من بيانات تدريب محدودة بعناية، يقترب إطار TS-CNN من أنظمة عملية قد تساعد الصم في المدارس والمستشفيات والمكاتب العامة. بالنسبة لمناطق مثل حائل، حيث المترجمون البشريون نادرون والمشروعات التكنولوجية لا تزال في مراحلها الأولى، يمكن لنظام كهذا أن يدعم في نهاية المطاف تواصلاً أكثر شمولية—مسهماً في ردم الفجوة بين مُستخدمي لغة الإشارة والعالم السامع دون أن يحل محل التجربة البشرية الغنية للغة الإشارة نفسها.
الاستشهاد: Harrouch, H., Guesmi, H., Alalfy, H. et al. A dual-stream deep learning framework for continuous sign language recognition to enhance communication accessibility in the Ha’il region. Sci Rep 16, 7070 (2026). https://doi.org/10.1038/s41598-026-38912-x
الكلمات المفتاحية: التعرف على لغة الإشارة, التعلم العميق, إمكانية الوصول, رؤية الحاسوب, تفاعل الإنسان مع الحاسوب