Clear Sky Science · ar
تقييم أداء نماذج اللغة الكبيرة في امتحانات البورد في الروماتيزم بالفارسية: دقة واستدلال سريري لـ GPT-4o مقابل GPT-5.1
لماذا يهم هذا الأطباء والمرضى
الذكاء الاصطناعي يدخل بسرعة إلى القاعات الدراسية والعيادات الطبية، لكن معظم اختبارات هذه الأدوات تركز على اللغة الإنجليزية. تسأل هذه الدراسة سؤالاً يهم ملايين الناطقين بالفارسية: ما مدى قدرة روبوتات الدردشة المتقدمة، وتحديداً GPT‑4o و GPT‑5.1، على معالجة أسئلة امتحانات الروماتيزم المعقدة المكتوبة بالفارسية؟ تساعد الإجابة المعلّمين والمتدربين والمرضى على فهم الأماكن التي يمكن لهذه الأدوات أن تساعد فيها بأمان وأين تظل الخبرة البشرية ضرورية.
اختبار الذكاء الاصطناعي
جمع الباحثون 204 أسئلة اختيار من متعدد من امتحانات البورد الإيراني في الروماتيزم لعامي 2023 و2024، وهي نفس الامتحانات التي يجب على الاختصاصيين اجتيازها للحصول على الشهادة. بعد استبعاد سبعة أسئلة معيبة، استُخدمت 197 مسألة. تم إدخال كل سؤال، بما في ذلك أي صور أو رسوم بيانية مرافقة، بالفارسية إلى GPT‑4o وGPT‑5.1 في محادثات منفصلة وجديدة. طُلب من النماذج اختيار أفضل إجابة وشرح تسلسل افكارها، محاكاةً للطريقة التي قد يستعلم بها المتدرب عن أداة ذكاء اصطناعي أثناء الدراسة.
التحقق من الإجابات والمنطق
حُكم على الأداء بطريقتين. أولاً، قورنت الخيارات التي اختارتها النماذج بمفتاح الإجابة الرسمي، مما أعطى مقياساً بسيطاً للصواب أو الخطأ. ثانياً، قيّم ستة أطباء روماتيزم معتمدون جودة كل تفسير بشكل مستقل على مقياس من خمس نقاط، من الاستدلال الخاطئ تماماً إلى استدلال كامل وسليم سريرياً. قيّم كل نموذج من قبل طبيبين مختلفين من الروماتيزم كانوا مجهولي التقييم أمام بعضهم البعض وأمام مفتاح الإجابة الرسمي. سمح هذا للباحثين برؤية ليس فقط ما إذا كان الذكاء الاصطناعي "خمن صح"، بل ما إذا كان منطقُه يشبه طريقة تفكير الاختصاصيين.
كيف أدت النسخة الأحدث
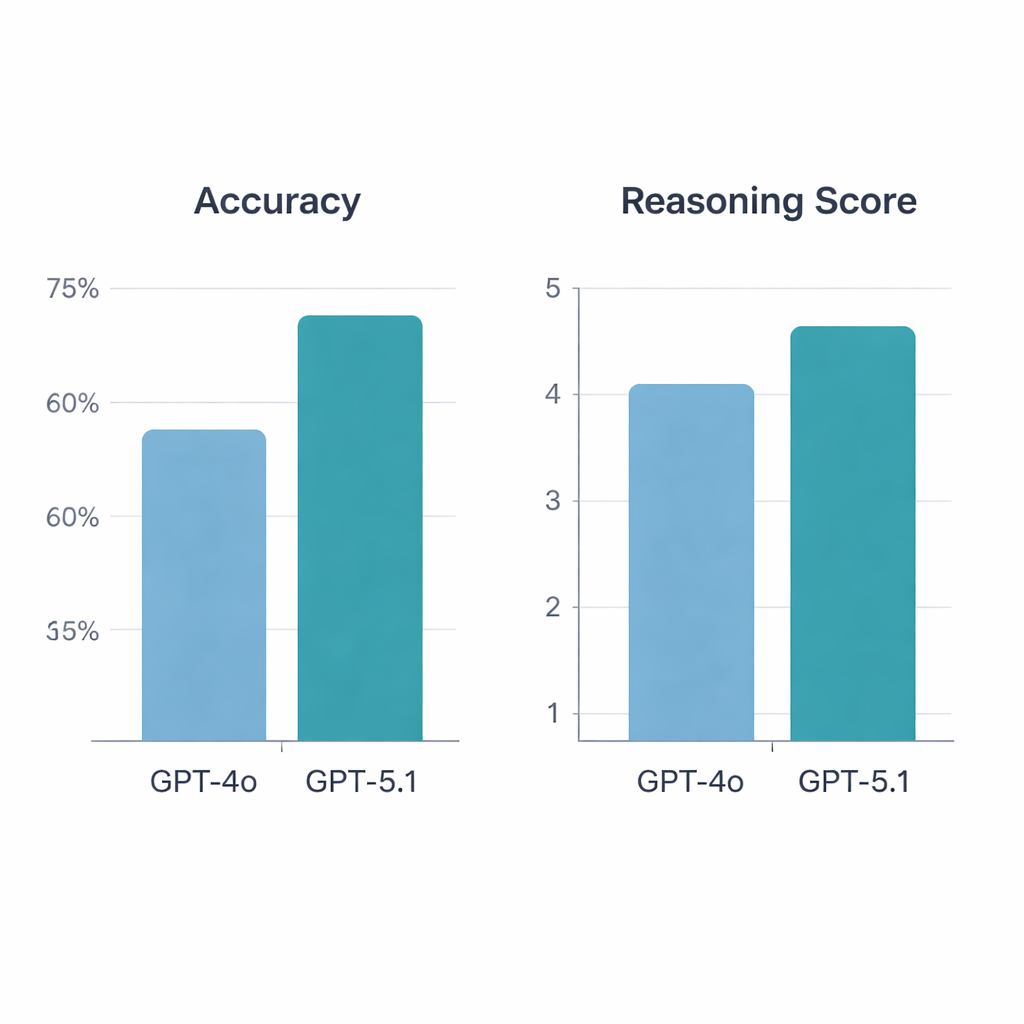
تفوقت GPT‑5.1 بوضوح على GPT‑4o. من بين 197 سؤالاً صالحاً، أجاب GPT‑4o بشكل صحيح على 64.5%، بينما وصل GPT‑5.1 إلى دقة 76% — وهو ارتفاع ذو دلالة إحصائية. كلا النموذجين أجابا بشكل صحيح عن 113 سؤالاً وخطئا في 34، لكن GPT‑5.1 حل بمفرده 36 سؤالاً إضافياً لم تجب عليها GPT‑4o؛ بينما كانت GPT‑4o صحيحة بشكل فريد في 13 سؤالاً فقط. عندما قيّم الروماتيزيون التفسيرات، تفوقت GPT‑5.1 مرة أخرى، بمعدل درجة استدلال وسطي 4.47 من 5 مقارنة بـ 4.13 لـ GPT‑4o، كما حصلت على تقييمات أعلى أكثر. وعلى عكس GPT‑4o، التي تذبذبت جودة استدلالها اعتماداً على ما إذا كان السؤال يركز على العلوم الأساسية أو سيناريوهات الحالات أو التشخيص أو العلاج، حافظت GPT‑5.1 على أداء أكثر توازناً عبر جميع الفئات.
نقاط القوة، الثغرات، واختلافات البشر
كشفت الدراسة عن فروق دقيقة مهمة. حتى عندما كانت إجابة النموذج النهائية خاطئة، قيّمها الاختصاصيون أحياناً على أنها ذات استدلال متماسك إلى حد ما، ما يبرز فجوة بين تقييم الامتحان والتفكير السريري الواقعي. في الوقت نفسه، كان التوافق بين المقيمين من الروماتيزم متواضعاً فقط، مما يبرز أن الأطباء أنفسهم يختلفون في تعريف ما يُعد "استدلالاً جيداً". بدا أن اللغة تلعب دوراً أيضاً: أبلغت أعمال سابقة بالإنجليزية والإسبانية عن درجات أعلى لنماذج مماثلة، مما يشير إلى أن الذكاء الاصطناعي لا يزال يتعامل بشكل أفضل مع لغات عالمية كبرى مقارنة بالفارسية. يؤكد المؤلفون أن هذه الروبوتات قد تنتج تفسيرات مقنعة قد تُخفي أخطاء واقعية، وأن أداءها قد يتغير مع تحديث الأنظمة.
ماذا يعني هذا للمستقبل
للقراء غير المتخصصين، الرسالة هي أن أحدث جيل من روبوتات الدردشة الذكية يتحسن في التعامل مع امتحانات التخصص الطبي بالفارسية، لكنه ليس جاهزاً للاستعاضة عن التدريب الصارم أو الحكم الخبير. يمكن أن تكون GPT‑5.1 شريك دراسة مفيداً لمتدرِّبي الروماتيزم — تلخّص المواضيع، تستعرض الحالات، وتقدّم شروحات منظمة — لكنها لا ينبغي أن تُعتمد ككلمة نهائية في قرارات عالية المخاطر بشأن التشخيص أو العلاج. يدعو المؤلفون إلى دراسات أوسع متعددة اللغات، واختبارات متكررة عبر الزمن، ومحاكاة سريرية واقعية لتحديد كيف يمكن دمج هذه الأدوات بأمان في التعليم الطبي، وفي نهاية المطاف، في رعاية المرضى اليومية.
الاستشهاد: Rafiei, F., Sadeghipour, S., Sheikhalishahi, S. et al. Evaluation of large Language model performance on Persian rheumatology board exams: accuracy and clinical reasoning of GPT-4o vs. GPT-5.1. Sci Rep 16, 7274 (2026). https://doi.org/10.1038/s41598-026-38716-z
الكلمات المفتاحية: الروماتيزم, التعليم الطبي الفارسي, نماذج اللغة الكبيرة, الاستدلال السريري, امتحانات البورد