Clear Sky Science · ar
استكشاف التفاعل بين المعلم والطالب عبر نماذج لغوية كبيرة متعددة الوسائط: تحقيق تجريبي
لماذا يهم مراقبة الفصول الدراسية بالذكاء الاصطناعي
كل من جلس في فصل دراسي يعرف أن كيفية تفاعل المعلمين والطلاب يمكن أن تصنع الفارق بين الملل والتعلّم الحقيقي. ومع ذلك، من الصعب بشكل مدهش دراسة هذه التبادلات اللحظية: يملّ المراقبون، وتختلف الأحكام البشرية، وتصبح بيانات الفيديو ساحقة بسرعة. يستكشف هذا المقال كيف يمكن لنوع جديد من الذكاء الاصطناعي — نماذج لغوية كبيرة متعددة الوسائط قادرة على «النظر» إلى الصور و«قراءة» النصوص — أن يساعد الباحثين والمدارس على فهم حياة الفصل المعقّدة بسرعة وموضوعية أكبر.
تحويل الدروس الحقيقية إلى بيانات بحثية
بدأ الباحثون بفيديوهات فصلية عادية من مدارس ابتدائية وثانوية صينية، متاحة علناً على منصة تعليمية وطنية. من 30 درساً استخرجوا ما يقرب من 2400 صورة ثابتة تلتقط لحظات رئيسية من التعليم والتعلّم. تم تعليم كل صورة وفق خمسة أنماط تفاعل سهلة الفهم: موجه (شرح المعلم)، تعاوني (عمل الطلاب معاً)، تساؤلي (طرح وإجابة الأسئلة)، مستقل (عمل الطلاب بمفردهم)، وعرضي (عرض الطلاب أمام الفصل). ساعد خبراء في تكنولوجيا التعليم على تنقيح هذه الفئات لتتطابق مع ما يبحث عنه الملاحظون ذوو الخبرة في الفصول الحقيقية.
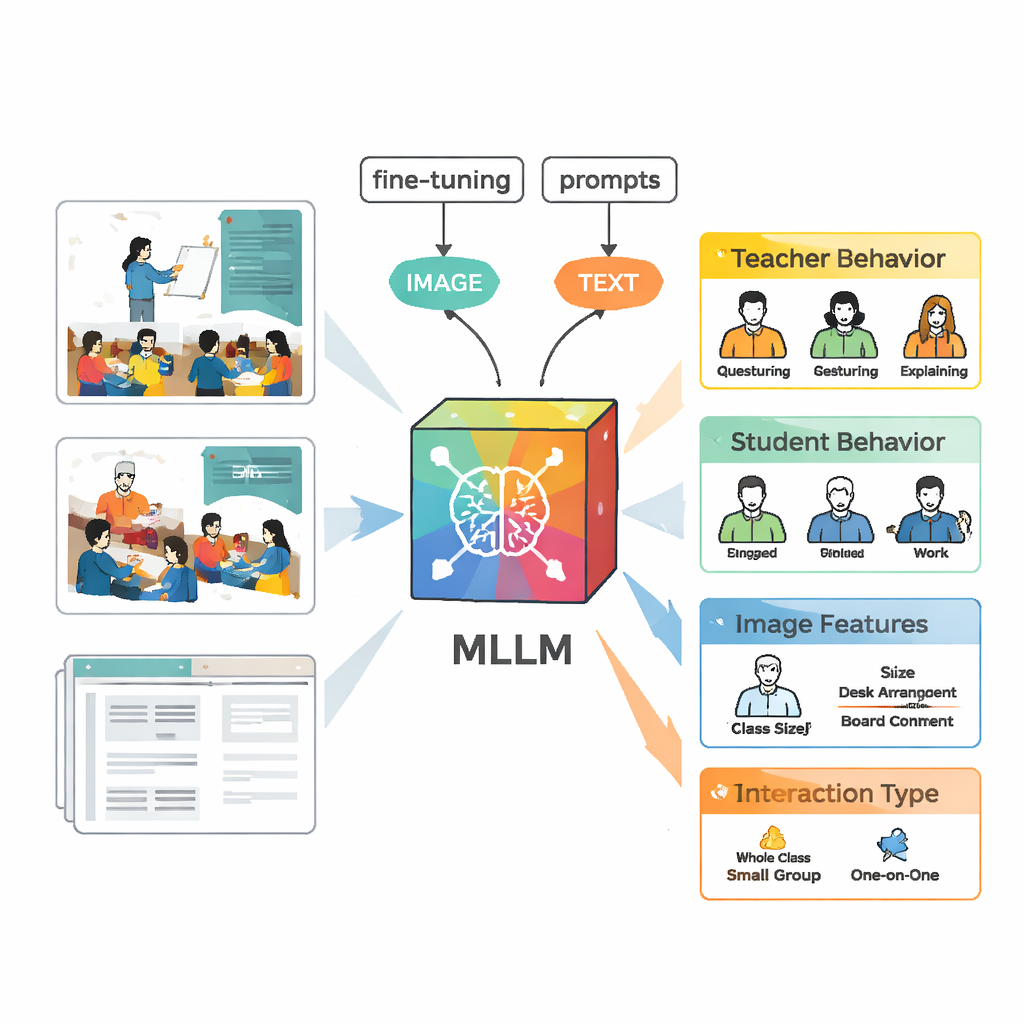
تعليم الذكاء الاصطناعي رؤية ديناميكيات الفصل
لتحليل هذه المشاهد، استخدم الفريق نموذجاً لغوياً كبيراً متعدد الوسائط يدعى VisualGLM‑6B، القادر على استقبال كل من الصور والنصوص كمُدخلات. لأن النموذج الأصلي تم تدريبه بشكل واسع وليس خصيصاً على بيئات الفصل، قام الباحثون «بضبطه الدقيق» باستخدام صورهم المعلمة. اعتمدوا تقنية تُسمى LoRA التي تعدل عدداً قليلاً فقط من معلمات النموذج الداخلية، مما يجعل التدريب أكثر كفاءة ومع ذلك قوياً. كما صمموا مطالبات دقيقة — تعليمات مُهيكلة تطلب من النموذج وصف سلوك المعلم، وسلوك الطلاب، والميزات البصرية، ونوع التفاعل بصيغة متسقة، بحيث يصبح مخرجه أسهل للمقارنة مع أحكام الخبراء البشر.
بناء تسميات أفضل بالإنسان والآلة
تتطلب إنشاء مجموعة تدريب عالية الجودة أكثر من مجرد توجيه النموذج نحو الفيديوهات. أولاً، أنتج VisualGLM أوصافاً أساسية لكل صورة. ثم صحّح المعلّقون البشر الأخطاء وملأوا السياق المفقود، مثل من كان يتكلم أو ما إذا كان الطلاب يستمعون أو يناقشون. بعد ذلك، أدخلوا هذه الأوصاف المصقولة إلى ChatGPT، الذي وبإرشادات مطالبات مخصصة ولّد تحليلات مُنظمة تتبع فئات التفاعل الخمس. راجع الخبراء هذه التحليلات التي أنشأها الذكاء الاصطناعي وعدّلوها مرة أخرى. النتيجة النهائية كانت مجموعة بيانات غنية تُرفق بكل صورة وصفاً مفصّلاً وموثوقاً لما كان يفعله المعلمون والطلاب.
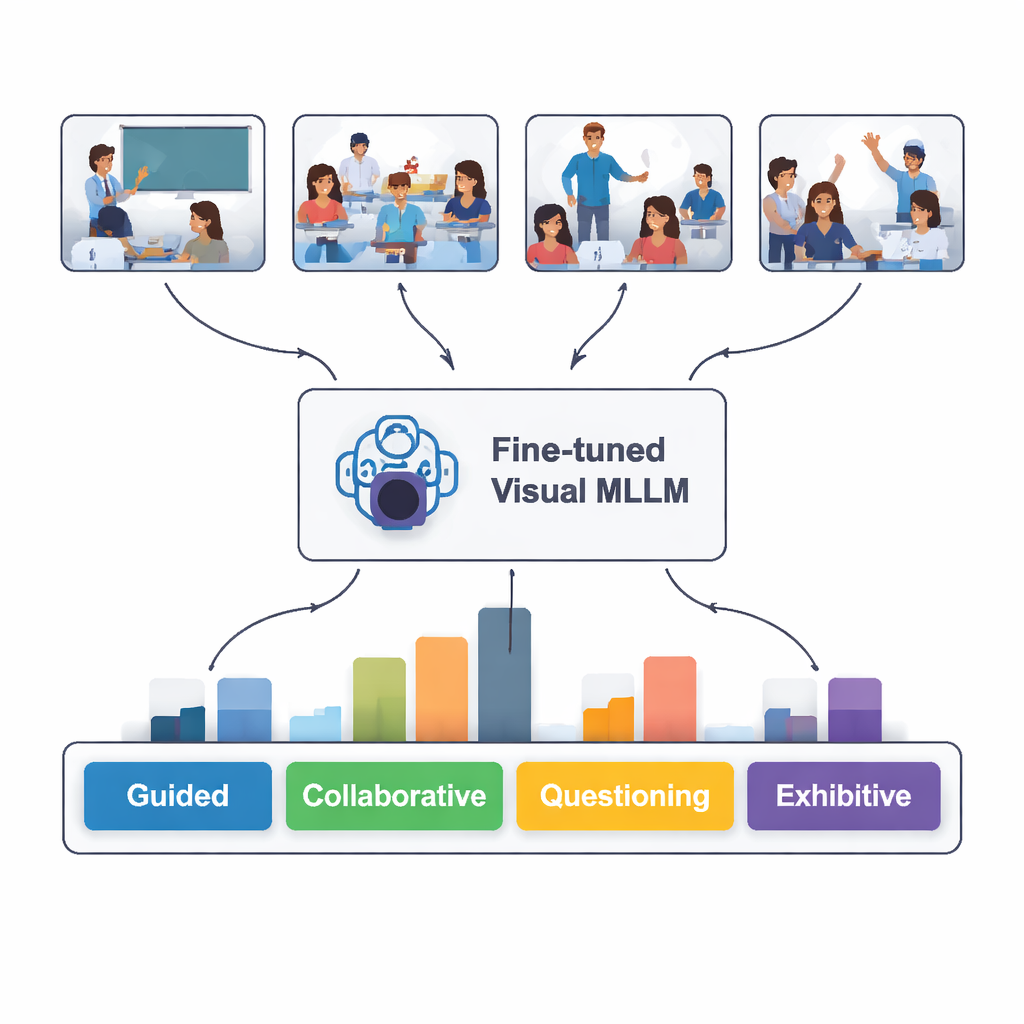
ما مدى قدرة الذكاء الاصطناعي على «قراءة» الفصل؟
عند اختباره على 100 صورة فصل جديدة لم يرها من قبل، حدّد النموذج المُعدل نوع التفاعل بشكل صحيح في 82 في المئة من الحالات. أظهر أداءً أفضل في التعرف على المواقف الموجهة والمستقلة والعرضية — حين يكون المعلم يشرح بوضوح، أو يعمل الطلاب بهدوء بمفردهم، أو يقدم طالب عرضاً أمام الفصل. واجه صعوبة أكبر مع العمل التعاوني والتساؤل، حيث يمكن أن تكون لغة الجسد وترتيبات الجلوس غامضة حتى بالنسبة للبشر. أظهر مقارنة نصية أعمق أن أوصاف النموذج المكتوبة تطابقت غالباً مع تحليلات الخبراء إلى حد كبير، رغم أنه أحياناً «اختلق» تفاصيل غير موجودة في الصور أو أساء تفسير إيماءة دقيقة.
ماذا يعني هذا للفصول القادمة
بالنسبة للقارئ العادي، الرسالة الأساسية هي أن أنظمة الذكاء الاصطناعي أصبحت قادرة على مراقبة الفصول وتلخيص كيفية تطور التدريس والتعلّم، بمستوى من البنية والاتساق يصعب على البشر المحافظة عليه عبر آلاف المشاهد. وعلى الرغم من أنها ليست مثالية — خاصة في أشكال النقاش والتساؤل الدقيقة — تظهر المقاربة أن النماذج اللغوية الكبيرة متعددة الوسائط يمكن أن تدعم الآن البحث التربوي، وفي النهاية أدوات تغذية راجعة للفصل. ومع بدء هذه النماذج في شمول الصوت والإيماءات ومجموعات بيانات أكبر وأكثر تنوعاً، قد تساعد المعلمين على رؤية أنماط في ممارساتهم كانت مخفية سابقاً، مقدمة عدسة جديدة لفهم كيف تشكل التفاعلات اليومية تعلم الطلاب.
الاستشهاد: Chen, G., Han, G., Niu, J. et al. Exploring teacher-student interaction through multimodal large language models: an empirical investigation. Sci Rep 16, 7602 (2026). https://doi.org/10.1038/s41598-026-38626-0
الكلمات المفتاحية: التفاعل بين المعلم والطالب, تحليلات الفصول الدراسية, الذكاء الاصطناعي متعدد الوسائط, تكنولوجيا التعليم, نماذج لغوية كبيرة