Clear Sky Science · ar
تصنيف تكيفي ذكي تدريجياً باستخدام شبكة عصبية محسّنة بدودة النملة الديناميكية لتدفقات البيانات
لماذا تثير البيانات المتغيرة باستمرار الاهتمام
من شبكات الطاقة والمصانع إلى المدفوعات عبر الإنترنت، تولد الأنظمة الحديثة بيانات في كل ثانية. تكمن في هذه التدفقات المستمرة من البيانات إشارات مبكرة لأعطال المعدات، أو هجمات إلكترونية، أو ارتفاعات وشيكة في الأسعار. التحدي هو أن هذا النهر من المعلومات لا يتوقف وسلوكه يتغير بمرور الوقت. تعرف الورقة المنشورة هنا طريقة جديدة لتدريب الشبكات العصبية بحيث تواصل التعلم من هذه البيانات الحيّة دون إبطاء أو فقدان الدقة، مما يجعلها أكثر فائدة للمراقبة وصنع القرار في العالم الحقيقي.
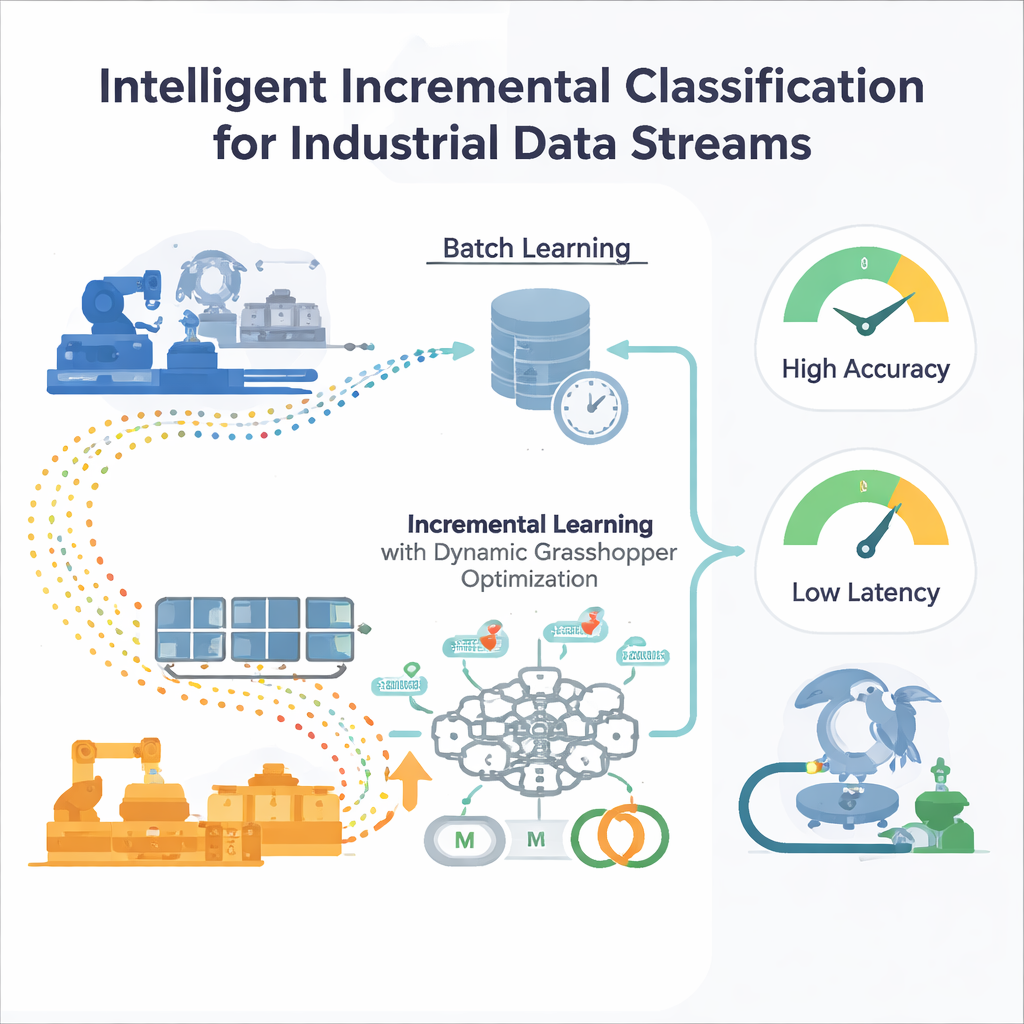
حدود التدريب لمرة واحدة
تُدرَّب معظم نماذج التعلم الآلي التقليدية في شكل «دفعات»: يجمع المهندسون مجموعة كبيرة من البيانات التاريخية، يضبطون النموذج، ثم ينشرونه. هذا ينجح إذا ظل العالم ثابتًا إلى حد ما. لكن في البيئات الصناعية تتحول الظروف—تتغير أنماط الطلب، وتتقدم المستشعرات في العمر، وتتقلب الأسواق. يصبح النموذج المجمد بمرور الزمن أعزل عن الأنماط الجديدة، وإعادة تدريبه من الصفر على مجموعات بيانات متزايدة الحجم مكلفة وبطيئة. كما أن أساليب الضبط التلقائي القياسية مثل بحث الشبكة أو الخوارزميات التطورية تفترض ثبات البيانات، ما يجعل إعادة تشغيلها ضرورية عند تغيّر توزيع البيانات، وهو أمر غير عملي للأنظمة العاملة دائمًا.
شبكة عصبية تتعلم أثناء سير البيانات
يقترح المؤلفون إطار تعلم تزايدي مبنيًا حول شبكية إدراك متعددة الطبقات (MLP)، وهو نوع شائع من الشبكات العصبية. بدلاً من تغذية الشبكة بكل البيانات السابقة دفعة واحدة، تُقسَّم تدفقات البيانات الواردة إلى نوافذ قابلة للإدارة. تصبح كل نافذة جديدة خطوة تدريب صغيرة تحدّث أوزان الشبكة الداخلية ثم تُتلف—استراتيجية «تدريب ونسيان» تحافظ على انخفاض استخدام الذاكرة. والأهم أن النظام لا يعتمد على إعدادات تدريب ثابتة. اثنان من عناصر التحكم الأساسية التي تضبط سلوك التعلم—معدل التعلم (حجم كل تحديث) والزخم (مدى نعومة تحرك التحديثات)—تُعدَّلان باستمرار مع تطور التدفق، بحيث يبقى النموذج مستجيبًا دون أن يصبح غير مستقر.
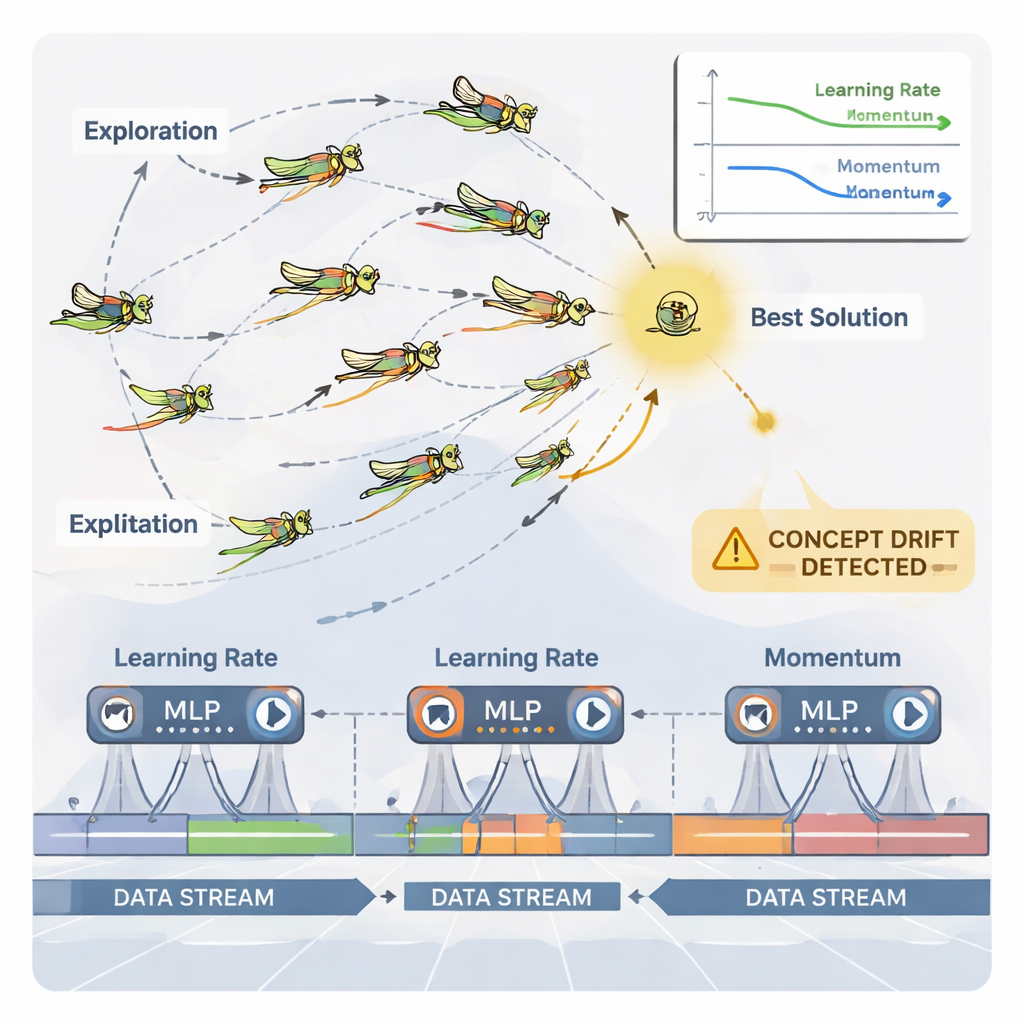
الجراد كضابط ذكي للمعاملات
لمعالجة هذا التعديل المستمر، تستخدم الورقة مُحسِّنًا مُستلهمًا من الطبيعة يُدعى خوارزمية تحسين الجراد الديناميكية (DGOA). تخيل سربًا افتراضيًا من الجراد يستكشف مجموعات ممكنة من معدّل التعلم والزخم. في المراحل الأولى يتجولون على نطاق واسع للبحث عن مناطق جيدة؛ لاحقًا يضيّقون حركتهم لتنقيح الخيارات الواعدة. في هذا الشكل الديناميكي يتغير حجم خطواتهم وجاذبيتهم نحو أفضل حل مع مرور الوقت اعتمادًا على مدى أداء الشبكة العصبية. كما يراقب النظام «انحراف المفهوم»—تغيّرات مفاجئة في أخطاء التنبؤ أو في البيانات نفسها. عند اكتشاف انحراف، يُعاد تهيئة بعض الجراد وتزداد خطواتهم مؤقتًا، مما يتيح للمُحسِّن البحث بسرعة في مناطق جديدة والهروب من إعدادات أصبحت قديمة.
اختبار الطريقة
قيَّم الباحثون نهجهم على مجموعة بيانات سوق كهرباء حقيقية من أستراليا، حيث كان الهدف التنبؤ بما إذا كانت الأسعار سترتفع أم ستهبط. بالمقارنة مع طرق الضبط الشائعة مثل بحث الشبكة، والبحث العشوائي، وتحسين سرب الجسيمات، والخوارزميات الجينية، وتحسين مستعمرة النمل، وخوارزمية الجراد القياسية، حقق الشكل الديناميكي المزاوج مع التعلم التزايدي أعلى دقة (حوالي 89.5%) مع استخدام أقل للوقت الحاسوبي وعدد أقل من التكرارات. أظهرت تجارب إضافية أن الطريقة تتكيف بشكل أفضل مع تدفقات البيانات المستقرة والمتغيرة، وتتدرج من آلاف إلى مليارات العينات مع الحفاظ على ضبط الذاكرة، وتؤدي أداءً تنافسيًا في مهام مثل الصيانة التنبؤية، والكشف عن الشذوذ، والكشف عن الاحتيال، وكذلك على معايير تحسين رياضية قياسية.
ماذا يعني هذا عمليًا
لغير المتخصصين، الخلاصة أن هذا العمل يقدم طريقة للحفاظ على شبكات عصبية «حية» ومضبوطة جيدًا في بيئات لا تتوقف فيها تدفقات البيانات وظروفها تتبدل باستمرار. بدلًا من إيقاف النظام مرارًا لإعادة بناء النماذج من الصفر، يسمح الإطار المقترح لشبكة خفيفة بالتحيّن نافذة تلو الأخرى، بينما يقوم مُحسِّن معتمد على سرب بتعديل مدى سرعة ونعومة التعلم بصورة مستمرة. النتيجة هي تأقلم أسرع مع الأنماط الجديدة، ودقة أفضل على المدى الطويل، واستخدام أكثر كفاءة لموارد الحوسبة—وهي مقوّمات أساسية لاتخاذ قرارات موثوقة وفورية في قطاعات مثل الطاقة والتصنيع والتمويل.
الاستشهاد: Darwish, S.M., El-Shoafy, N.A. Intelligent incremental classification using a dynamic grasshopper-enhanced neural network for data streams. Sci Rep 16, 7730 (2026). https://doi.org/10.1038/s41598-026-38571-y
الكلمات المفتاحية: تدفقات البيانات, التعلم التزايدي, الشبكات العصبية, تحسين المعاملات الفائقة, ذكاء السرب