Clear Sky Science · ar
نموذج هجين قابل للتفسير من نوع CNN–Transformer للتعرّف على لغة الإشارة على أجهزة طرفية باستخدام الدمج التكيفي وتقطير المعرفة
لماذا تهم أدوات لغة الإشارة الصغيرة
تعتمد مليارات المحادثات اليومية على حركات اليدين وتعابير الوجه ولغة الجسد أكثر من الكلمات المنطوقة. ومع ذلك، لا تزال معظم الهواتف والأجهزة اللوحية والأجهزة العامة غير قادرة على فهم لغات الإشارة، لا سيما خارج الدول الناطقة بالإنجليزية. تقدّم هذه الورقة TinyMSLR، نظاماً مضغوطاً وقابلاً للتفسير للتعرّف على لغة الإشارة مصمّم للعمل في الوقت الحقيقي على أجهزة صغيرة منخفضة الطاقة. الهدف هو تحويل الأجهزة العادية إلى مساعدات تواصل ميسورة وجديرة بالثقة للأشخاص الصمّ وضعاف السمع حول العالم.
إدخال المزيد من اللغات إلى النقاش
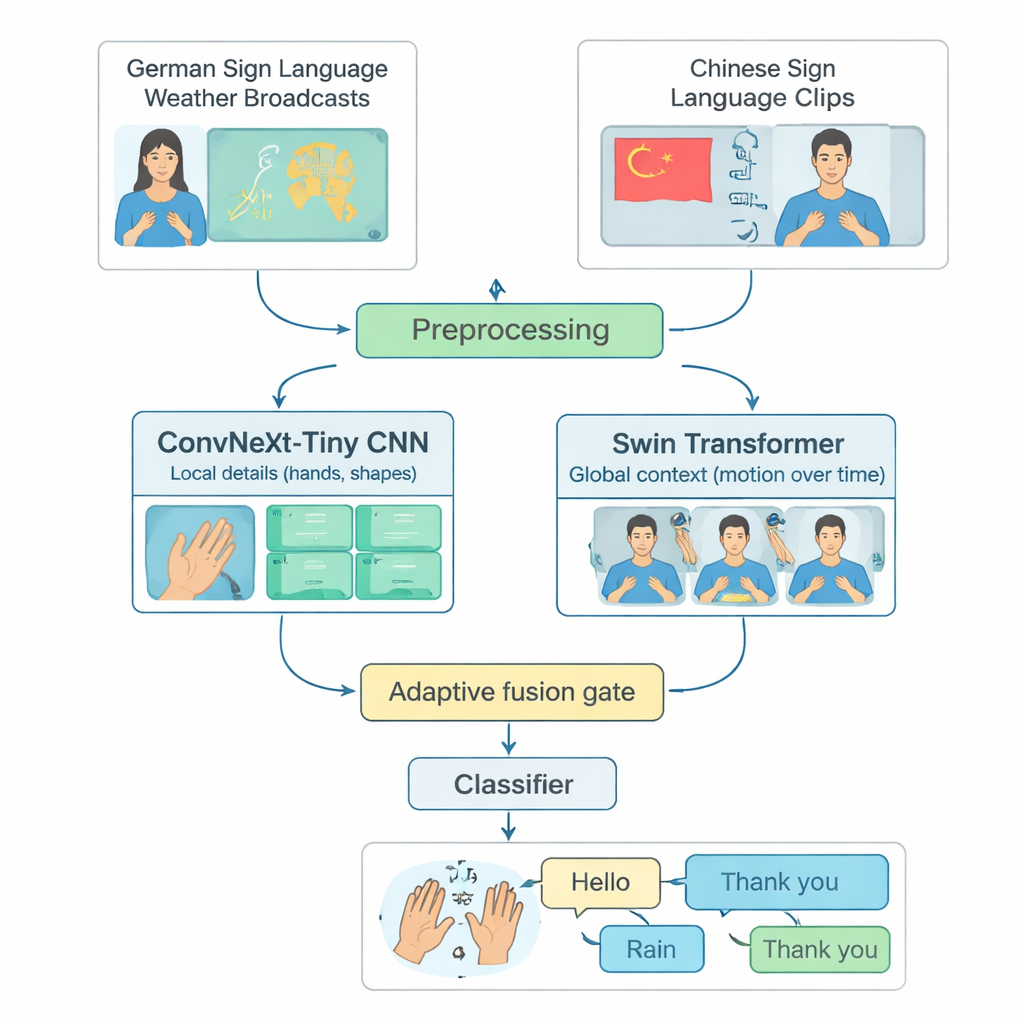
تركز العديد من أنظمة التعرّف المتقدمة على لغة إشارة واحدة، غالباً لغة الإشارة الأمريكية، وتعمل فقط على حواسب قوية. هذا يستثني من يعتمدون لغات إشارة أخرى أو يعيشون في مناطق محدودة الموارد الحاسوبية. يعالج المؤلفون هذه الفجوة ببناء بيئة اختبار مشتركة من لغتين مختلفتين: نشرات الطقس بلغة الإشارة الألمانية ومجموعة كبيرة من لغة الإشارة الصينية. اختاروا بعناية 20 إشارة يومية شائعة — مثل مرحباً، الطقس، مطر، سعيد، نعم، وشكراً — الموجودة في كلتا اللغتين. من خلال تقليم مقاطع الفيديو الطويلة إلى مقاطع قصيرة تحتوي علامة واحدة فقط، وموازنة عدد الأمثلة لكل فئة ولكل موقّع، أنشأوا طريقة عادلة وقابلة للتكرار لتقييم مدى قدرة النموذج على التعرّف على إشارات معزولة عبر لغات مختلفة.
كيف يرى النموذج الهجين اليدين والحركة
يجمع TinyMSLR طريقتين تكمليتين لمشاهدة الفيديو. يستخدم فرع واحد شبكة تلافيفية حديثة (ConvNeXt‑Tiny) متفوقة في رصد التفاصيل الدقيقة، مثل أشكال الأصابع والملمس الرفيع. أما الفرع الثاني فيستخدم Swin Transformer، وهي عائلة أحدث من النماذج التي تتألّق في تتبّع الأنماط عبر الزمان والمكان — كيف تتحرك اليدان والوجه والجزء العلوي من الجسم عبر عدة إطارات. يتم توحيد كل مقطع فيديو قصير إلى 32 إطاراً بحجم 224×224 بكسل، وتُجرى عليه زيادة طفيفة للبيانات (مثل دورانات صغيرة أو تغييرات في السطوع)، ثم يُمرَّر إلى الفرعين بالتوازي. ينتج كل فرع ملخصاً مكوّناً من 768 رقماً عما يراه؛ معاً تلتقط هاتان الخلاصتان التفاصيل المحليّة الحادّة والحركة والسياق الأوسع.
ترك للنموذج قرار ما هو الأهم
بما أن بعض الإشارات تُميَّز أساساً بشكل اليد بينما تعتمد أخرى على حركات واسعة للذراعين أو إشارات وجهية، فإن TinyMSLR لا يفرض وصفة واحدة لدمج رؤيتيه. بدلاً من ذلك، يستخدم «بوابة دمج» صغيرة تتعلّم، لكل مقطع إدخال، مقدار الثقة في الفرع المتركّز على التفاصيل مقابل الفرع المتركّز على السياق. تنظر البوابة إلى خلاصة الميزات من كلا الفرعين وتصدر وزنَين دائماً ما يجمعان إلى واحد؛ التمثيل النهائي هو خليط مرجّح من الاثنين. أثناء التدريب، يحصل كل فرع أيضاً على مصنّف صغير خاص به ليصبح مفيداً لوحده، وزوج من شبكات «المعلّم» الأكبر (واحدة CNN وواحدة Transformer) يوجّه النموذج الصغير بلطف عن طريق إظهار ليس فقط التصنيف الصحيح ولكن أيضاً أي التصنيفات البديلة تبدو متشابهة. تساعد هذه التقنية، المسماة تقطير المعرفة، النظام المدمج على الاقتراب من دقة النماذج الأثقل مع الحفاظ على الحجم والسرعة المناسبين للأجهزة الطرفية.
إظهار سبب اتخاذ النظام كل قرار
بعيداً عن الدقة الخامّ، يؤكد المؤلفون أن المستخدمين والمطوّرين يجب أن يكونوا قادرين على فحص ما يولي النموذج اهتمامه. يعتمدون SHAP، مجموعة أدوات تُنسب قيمة أهمية لكل جزء من الإدخال. عملياً، يحسبون هذه التفسيرات على الميزات الوسيطة ويعيدون رسمها على الإطارات كخرائط حرارية ومخططات زمنية. يكشف هذا، على سبيل المثال، أي الإطارات والمناطق تدفع القرار بين إشارتين متشابهتين بصرياً مثل مطر وثلج أو بارد وسيئ. تجميع الكثير من التفسيرات يظهر أنماطاً أوسع: تبرز الإشارات غير اليدوية مثل تعابير الوجه وحركات الرأس، وكذلك توجيه الرسغ وشكل اليد، كعوامل ذات تأثير خاص. تساعد هذه الرؤى في التحقق من أن النظام يعتمد على جوانب ذات معنى من الإشارة بدلاً من أثر الخلفية.

السرعة والاقتصاد ومساحة للنمو
على معيار الاختبار الثنائي اللغة المكوّن من 20 إشارة، يصل TinyMSLR إلى نحو 99% دقة تدريب وتحقق ودرجة F1 تقارب 99%، بينما يستخدم أقل من 2.7 مليون معلمة وحوالي 1.9 مليار عملية لكل مقطع. على وحدة معالجة رسومية حديثة يعالج إشارة في حوالي 13.5 ميلي ثانية ويستهلك أقل من 30 ميلي جول من الطاقة؛ النموذج المخزّن يبلغ حجمه نحو 7.2 ميغابايت فقط. تشير هذه الأرقام إلى أن التعرف على الإشارات في الوقت الحقيقي وعلى الجهاز ممكن على لوحات منخفضة التكلفة وأنظمة مضمّنة. ويشير المؤلفون بحذر إلى أن عملهم يغطي إشارات قصيرة ومعزولة ولغتين فقط، ويتعامل مع تعابير الوجه بشكل ضمني بدلاً من أن يكون إشارة منفصلة. ترك توسيع النهج إلى مفردات أغنى، وجمل مستمرة، ومزيد من اللغات، ونمذجة صريحة لتعبيرات الوجه وحركات الرأس للأعمال المستقبلية. ومع ذلك، يقدم TinyMSLR دليلاً مقنعاً: أدوات دقيقة وفعّالة وقابلة للتفسير لفهم لغات الإشارة لا يلزم أن تقتصر على السحابة — يمكن أن تعمل مباشرة على الأجهزة اليومية.
الاستشهاد: Lamaakal, I., Yahyati, C., Maleh, Y. et al. An explainable hybrid CNN–transformer model for sign language recognition on edge devices using adaptive fusion and knowledge distillation. Sci Rep 16, 7143 (2026). https://doi.org/10.1038/s41598-026-38478-8
الكلمات المفتاحية: التعرّف على لغة الإشارة, تعلم الآلة الصغير, الذكاء الاصطناعي الطرفي, الذكاء القابل للتفسير, نماذج متعددة اللغات