Clear Sky Science · ar
SAT: محول محاذاة الإزاحة لتنقية الفيديو دون تقدير التدفق
فيديوهات أكثر وضوحًا من مشاهد مضطربة
كل من حاول التسجيل داخل المباني ليلًا أو باستخدام هاتف بإضاءة محدودة يعرف النتيجة: فيديو محبب ومتلألئ حيث تبدو التفاصيل زاحفة وتظهر الألوان مشوهة. تعرض هذه الورقة طريقة جديدة لتنقية مثل هذه الفيديوهات، وتحويلها إلى تسلسلات أوضح وأكثر استقرارًا دون الاعتماد على برامج تتبع الحركة الثقيلة التي عادةً ما تجعل ذلك ممكنًا. الطريقة، المسماة محول محاذاة الإزاحة، مصممة للحفاظ على التفاصيل الدقيقة مع البقاء فعالة بما يكفي للاستخدام العملي.
لماذا تنقية الفيديو صعبة للغاية
إزالة الضوضاء من صورة واحدة تحدٍ بحد ذاته؛ وإجراء نفس العملية على فيديو أصعب بكثير. من جهة، كل إطار يتعرض لبقع عشوائية وتحولات لونية. ومن جهة أخرى، ترتبط الإطارات عبر الزمن: تتحرك الأجسام، يهتز الكاميرا، وتظهر التفاصيل وتختفي. اعتمدت طرق تنقية الفيديو التقليدية على تقدير الحركة بين الإطارات، غالبًا عبر أداة تُسمى التدفق البصري، التي تحاول تتبع أين يتحرك كل بكسل من إطار إلى آخر. ورغم قوتها، يمكن لهذه التقديرات أن تنهار بسهولة عندما يكون الفيديو شديد الضوضاء أو الحركة سريعة ومعقدة، كما أنها تضيف عبئًا حسابيًا كبيرًا قد تُبطئ الأنظمة بشكل ملحوظ.
طريقة جديدة للمحاذاة دون تتبع
بدلًا من محاولة اتباع كل بكسل صراحةً، يسلك محول محاذاة الإزاحة مسارًا مختلفًا: يسمح للشبكة باكتشاف العلاقات بين الإطارات ضمنيًا عن طريق إزاحة ومقارنة الميزات بعناية. يُبنى النموذج على هيكل حديث معروف بالمحول، الذي يتفوق في إيجاد العلاقات بعيدة المدى في البيانات. ضمن هذا الإطار، يقدم المؤلفون وحدة إزاحة مكانية-زمكانية تقوم بتوزيع المعلومات بلطف عبر الزمن والمكان معًا. على مستوى الزمن، يحرك النموذج ميزات الإطارات دورياً بحيث يتمكن كل إطار، طبقة بعد طبقة، من "الرؤية" أبعد في الماضي والمستقبل. على مستوى المكان، يقسم الميزات إلى مجموعات صغيرة كثيرة ويزحزح كل مجموعة في اتجاهات مختلفة. هذا المزيج يحاكي بشكل فعال كيف قد تتحرك الأجسام عبر الفيديو، ما يسمح للشبكة بمزامنة المعلومات من إطارات مختلفة دون حساب حقل حركة صريح.
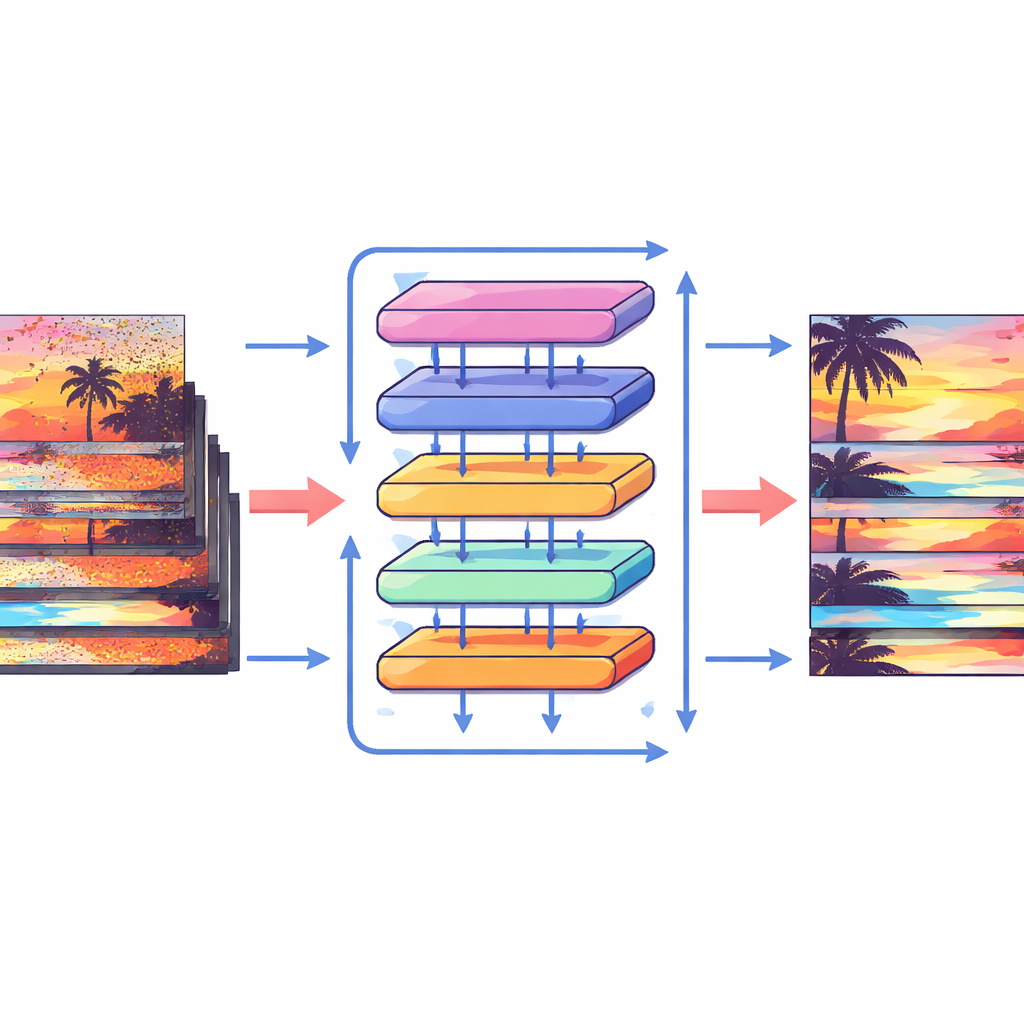
كيف تعمل الوحدات الجديدة
لاستثمار هذه الإزاحات بأقصى قدر، يصمم المؤلفون كتلة انتباه خاصة تمزج المعلومات داخل الإطارات وعبرها. أولًا، تُجمع الميزات المزاحة من الإطارات المجاورة وتُقارن عبر عملية انتباه متقاطع: يتعلم النموذج أي المناطق في الإطارات الأخرى تدعم الإطار الحالي بأفضل شكل في كل موضع. في الوقت نفسه، تركز عملية انتباه منفصلة على العلاقات داخل كل إطار بمفرده، معززة البنية والملمس المحليين. ثم تندمج هاتان القناتان وتمرران عبر طبقات معالجة بسيطة في شبكة متعددة المقاييس على شكل حرف U، تنتقل من دقة خشنة إلى دقيقة ثم تعود. يتيح هذا التخطيط للنظام التعامل مع حركات كاميرا كبيرة وتفاصيل دقيقة مثل الحواف الرقيقة أو الأنماط الصغيرة، مستعيدًا تدريجيًا نسخة نظيفة من كل إطار.
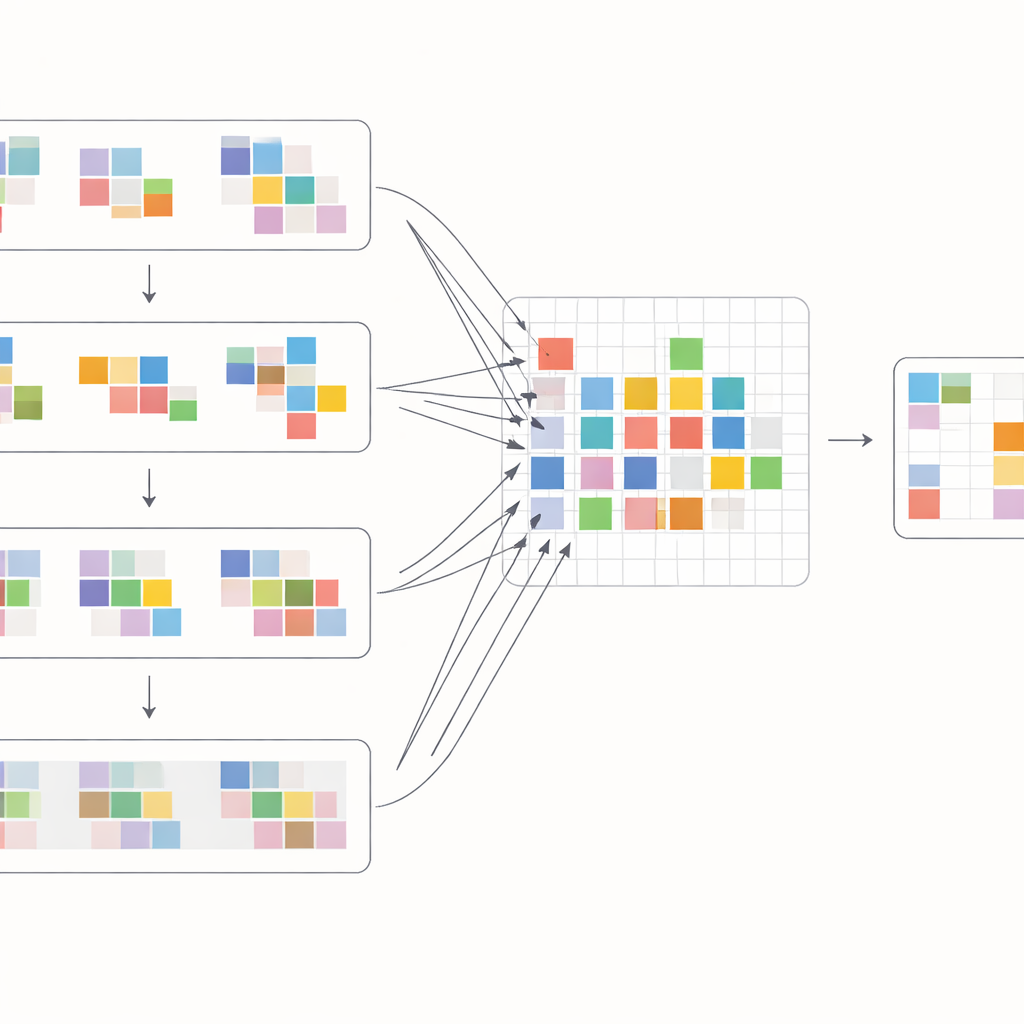
مدى فعاليته عمليًا
يختبر الباحثون نهجهم على معيارين صارمين. الأول يتضمن فيديوهات نظيفة تم إفسادها صناعيًا بمستويات مختلفة من الضوضاء العشوائية، مما يسمح بقياس مدى تطابق الإطارات المستعادة مع الأصلية بدقة. هنا، تتطابق الطريقة الجديدة أو تتجاوز باستمرار جودة الشبكات الالتفافية والمتكررة السابقة، وتقترب من أفضل نماذج المحول الموجودة مع استخدام حسابي أقل. المعيار الثاني يستخدم لقطات حقيقية ملتقطة من مجسات الصور في ظروف إضاءة منخفضة، حيث تكون الضوضاء غير متساوية وملونة وأقل قابلية للتنبؤ. في هذا الاختبار الأكثر واقعية، يتفوق محول محاذاة الإزاحة بشكل حاسم على طرق الحالة-الأدنى السابقة، منتجًا فيديوهات تبدو أنظف وأكثر حدة واستقرارًا عبر الزمن، مع تحولات لونية ونتوءات متبقية أقل.
ماذا يعني ذلك لأدوات الفيديو المستقبلية
بعبارة بسيطة، يُظهر المؤلفون أنه من الممكن تنقية الفيديوهات بفعالية دون تتبع الحركة صراحةً، عبر دمج إزاحات ذكية زمنية ومكانية مع مطابقة الميزات القائمة على الانتباه. يقدم محول محاذاة الإزاحة توازنًا قويًا بين الدقة والكفاءة، خصوصًا لقطات العالم الحقيقي منخفضة الإضاءة، حيث يكون تقدير الحركة التقليدي هشًا. ومع تحسن كفاءة النماذج القائمة على الانتباه، قد تدخل طرق كهذه إلى الكاميرات وخدمات البث اليومية، مساعدةً على تحويل المقاطع الصاخبة والصعبة للمشاهدة إلى فيديوهات ناعمة وحادة مع أقل قدر من التعقيد للمستخدم.
الاستشهاد: Zhang, X., Fan, S., Zhang, H. et al. SAT: shift alignment transformer for video denoising without flow estimation. Sci Rep 16, 8207 (2026). https://doi.org/10.1038/s41598-026-38431-9
الكلمات المفتاحية: تنقية الفيديو, محول, ضوضاء الصورة, فيديو منخفض الإضاءة, رؤية حاسوبية