Clear Sky Science · ar
هجوم عدائي قائم على القرار بكفاءة استعلامية وميزانية استعلام منخفضة
لماذا يمكن لثغرات صغيرة جداً في الصور أن تخدع الآلات الذكية
يمكن للذكاء الاصطناعي الحديث التعرف على الوجوه والحيوانات والأشياء اليومية بدقة مثيرة للإعجاب. ومع ذلك، يمكن خداع هذه الأنظمة نفسها بتغييرات على صورة ضئيلة لدرجة أن البشر بالكاد يلاحظونها. تستكشف هذه الورقة طريقة جديدة لإنشاء مثل هذه الصور «المضللة» مع طرح أقل عدد ممكن من الأسئلة على نموذج الذكاء الاصطناعي، مما يكشف عن هشاشة النماذج الحالية وكيف قد يستغلها المهاجمون في العالم الحقيقي.
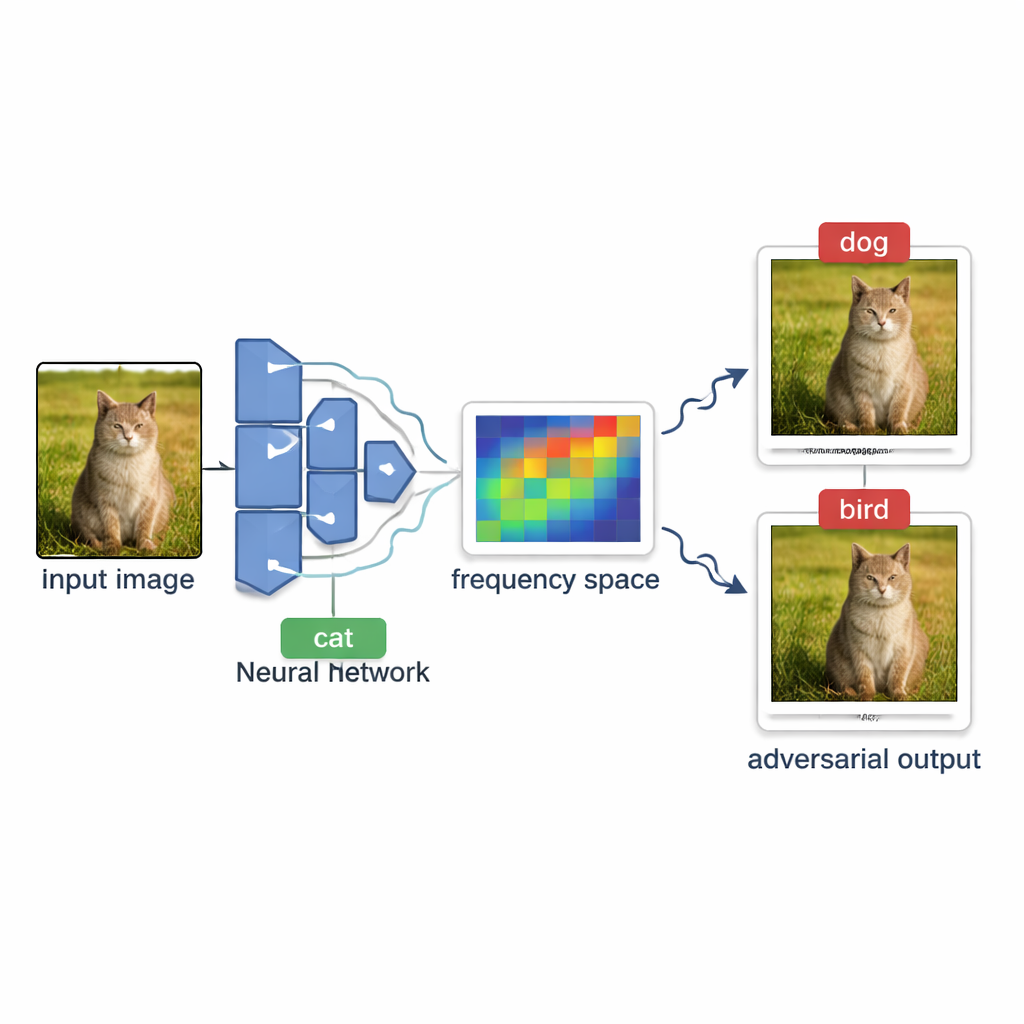
كيف يستجوب المهاجمون أنظمة الذكاء الاصطناعي من الخارج
في العديد من الخدمات الواقعية—مثل وسم الصور عبر الإنترنت أو مرشحات المحتوى—يتصرف النموذج كصندوق أسود. يمكن للوافدين الخارجيين رفع صورة ورؤية التسمية النهائية فقط، مثل «كلب» أو «إشارة قف»، لكنهم لا يصلون إلى درجات الثقة الداخلية أو بنية النموذج. تسمى عملية إنشاء صورة مضللة في هذه الظروف هجوم صندوق أسود قائم على القرار. التحدي هو دفع صورة طبيعية بلطف حتى يخطئ النموذج في تصنيفها، من دون أن نتمكن من رؤية مدى «قربها» من تغيير القرار ومن دون إرسال عدد كبير جداً من الصور التجريبية التي قد يلحظها النظام أو تجعل الاستعلامات مكلفة للغاية.
طريقة جديدة للبحث بقلّة استعلامات
يقدم المؤلفون طريقة OPOQA (هجوم مستوي واحد استعلام واحد)، وهي طريقة صممت لتقتصد في عدد الاستعلامات مع الحفاظ على إنتاج صور عدائية عالية الجودة. بدل الاستقصاء المتكرر على اتجاه مفترض واحد، تعمل OPOQA على جولات. في كل جولة تبدأ من صورة مضللة موجودة مسبقاً والصورة الأصلية النظيفة، ثم تقترح عدة صور مرشحة جديدة تقع في اتجاهات مُختارة بعناية. والأهم أن كل اتجاه يُستجوب مرة واحدة على الأكثر، مما يحرر ميزانية الاستعلام المحدودة لاستكشاف إمكانيات أكثر بدلاً من تحسين تخمين واحد بشكل مفرط.
الركوب على الموجات الناعمة في الصورة
لاختيار اتجاهات واعدة، تعتمد OPOQA على فكرة أن التغييرات الأكثر فعالية والتي يصعب رؤيتها تكون غالباً ناعمة وواسعة بدلاً من ضوضاء حادة على مستوى البكسل. تستخدم الطريقة أداة رياضية تُسمى تحويل جيب التمام المنفصل لوضع الصورة في منظور «التردد»، حيث توجد التغيرات البطيئة واللطيفة في منطقة مدمجة. تقوم بأخذ عينات عشوائية من بعض هذه المكونات منخفضة التردد، وتحويلها مرة أخرى إلى تغيرات بكسل عادية، واستخدامها كاتجاهات أساسية للاستكشاف. يساعد كل اتجاه مُؤَخذ في تعريف سطح ثنائي الأبعاد مسطح يربط الصورة الأصلية بالصورة العدائية الحالية وبالمرشح الجديد. على كل من هذه الأسطح، تختار OPOQA نقطة واحدة للاختبار، موازنة بين هدفين: الاقتراب من الصورة الأصلية مع احتمال دفع النموذج إلى اتخاذ قرار خاطئ.

اختيار أفضل مرشح والتكيف أثناء التنفيذ
بمجرد أن تولد OPOQA مجموعة صغيرة من الصور المرشحة، تقيس مدى بعد كل واحدة عن الصورة الأصلية وترتبها من الأقل إلى الأكثر تغيّراً. ثم تستعلم النموذج بهذا الترتيب. في اللحظة التي تجد فيها مرشحاً يسيء النموذج تصنيفه، تتوقف وتتعامل مع تلك الصورة كنقطة انطلاق جديدة للجولة التالية. إذا لم ينجح أي من المرشحين في خداع النموذج، تحتفظ OPOQA بأفضل صورة عدائية سابقة لكنها تضبط مقبضاً داخلياً يتحكم في مدى تحفظ أو جرأة خطوات المجموعة التالية. تتيح هذه الاستراتيجية «الطماعة»—قبول أفضل صورة خاطئة متاحة دائماً وضبط حجم الخطوة ديناميكياً—للهاجم أن يركز على اضطرابات دقيقة وفعالة دون إهدار الاستعلامات في اتجاهات غير واعدة.
ما تكشفه التجارب عن نقاط ضعف الذكاء الاصطناعي
اختبر الباحثون OPOQA على 200 صورة من مجموعة معيار ImageNet واسعة النطاق وستة نماذج شبكات عصبية مستخدمة على نطاق واسع، بما في ذلك Inception-v3 وResNet وVGG وDenseNet والمحولات البصرية. تحت حد صارم يبلغ 1000 استعلام للنموذج لكل صورة، طوّت OPOQA أو تفوقت على عدة طرق هجوم رائدة. فعلى سبيل المثال، نجحت على Inception-v3 في خداع النموذج في 94 في المئة من الصور مع إبقاء التغيرات صغيرة لدرجة تكاد تكون غير مرئية للعين البشرية، محققة تحسناً بعدة نقاط مئوية على أفضل طريقة سابقة. عبر النماذج، كانت OPOQA تميل إلى الوصول إلى معدلات نجاح عالية في وقت أبكر—باستخدام استعلامات أقل—على الرغم من أن بعض الطرق المنافسة لحق بها أو تفوقت عليها عندما مُنحت ميزانيات استعلام كبيرة جداً وزمن للتنقيح.
ماذا يعني هذا لأمان الذكاء الاصطناعي في الحياة اليومية
تُظهر الدراسة أن أنظمة الرؤية الحالية يمكن خداعها حتى عندما يرى المهاجمون القرارات النهائية فقط ولديهم فرص محدودة لاستجواب النموذج. من خلال الاستكشاف الذكي للتغيرات اللطيفة منخفضة التردد وتوزيع كل استعلام بعناية، يمكن لـOPOQA إنشاء صور تبدو نفسها للبشر لكنها تضلل الآلات بشكل كبير. للخلاصة لغير المتخصصين: قدرة الذكاء الاصطناعي على "الرؤية" لا تزال هشة إلى حد كبير؛ يمكن دفعها عن مسارها بطرق دقيقة يصعب ملاحظتها. إن التعرف على مثل هذه الهجمات الفعالة ودراستها هو خطوة أساسية لتقوية الأنظمة الواقعية—مثل كاميرات المراقبة وأدوات الصور الطبية والمركبات الذاتية—ضد التلاعب الذي قد يمر دون أن يُكشف عنه.
الاستشهاد: Tuo, Y., Yin, M. & Che, S. Query-efficient decision-based adversarial attack with low query budget. Sci Rep 16, 6886 (2026). https://doi.org/10.1038/s41598-026-38428-4
الكلمات المفتاحية: أمثلة عدائية, هجمات الصندوق الأسود, أمن التعلم العميق, تصنيف الصور, هجوم كفء من حيث الاستعلام