Clear Sky Science · ar
تخصيص الموارد بمساعدة التوأم الرقمي عبر التعلم بالتقليد التوليدي التنافسي في سيناريوهات سحابة-حافة-نهاية معقدة
طرق بيانات أكثر ذكاءً لإنترنت الأشياء
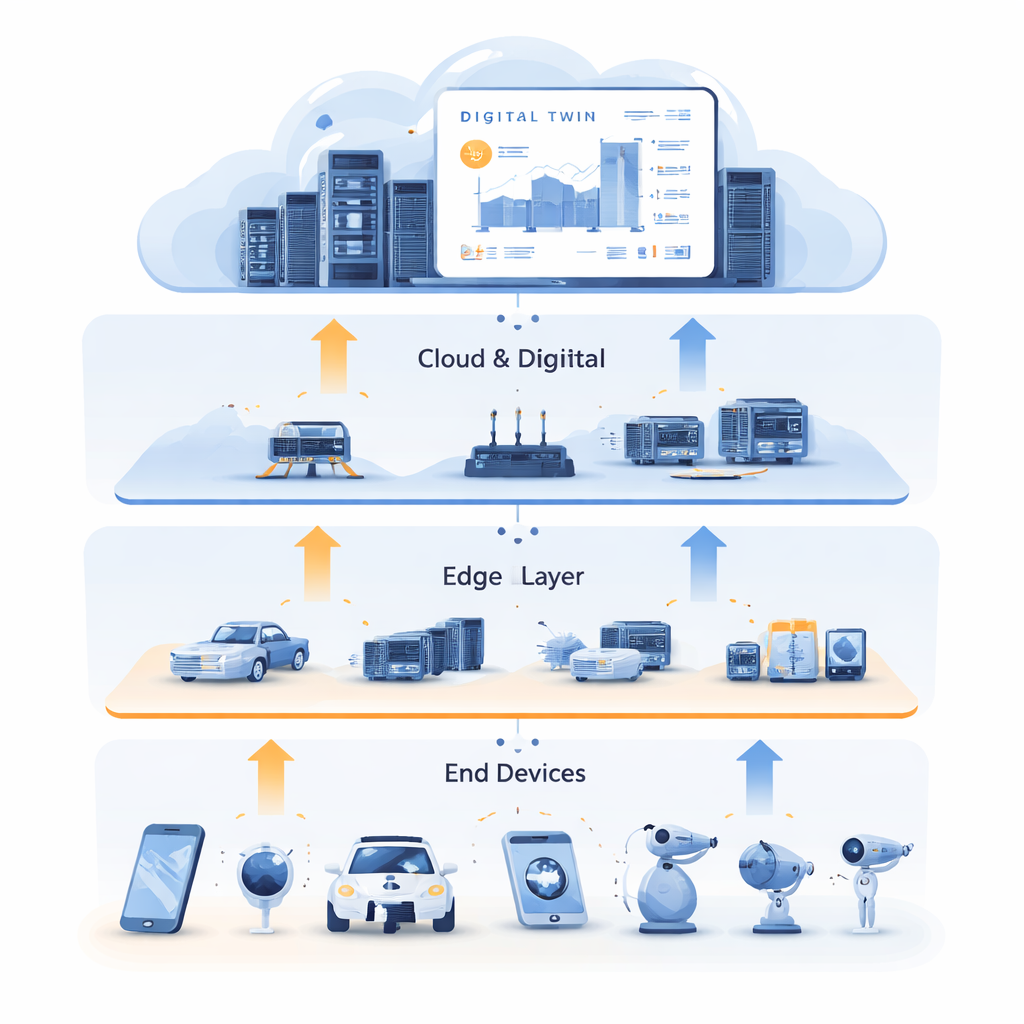
مع امتلاء المدن والمصانع والمنازل بالمستشعرات والأجهزة المتصلة، تولّد هذه البيئات سيلًا من البيانات التي يجب معالجتها بسرعة وبموثوقية. إرسال كل شيء إلى خوادم سحابية بعيدة قد يكون بطيئًا للغاية، بينما تفتقر الأجهزة الصغيرة عند «الحافة» غالبًا إلى قدر كافٍ من القدرة الحاسوبية. تستكشف هذه الورقة طريقة جديدة لتوجيه وتخصيص موارد الحوسبة والتخزين والشبكة عبر الأجهزة وخوادم الحافة القريبة والسحابة—بحيث تظل التطبيقات الذكية سريعة ومرنة حتى عندما تكون ظروف العالم الحقيقي فوضوية وغير متوقعة.
لماذا تعاني الأساليب الحالية
تعتمد الأنظمة الحديثة كثيرًا على التعلم المعزز العميق، حيث يتعلم الخوارزم عن طريق التجربة والخطأ باستخدام إشارات مكافأة من البيئة. لكن في شبكات معقدة ومرتبكة، تكون تلك المكافآت صعبة التعريف والقياس. إذا كانت دالة المكافأة خاطئة أو مشوَّهة بسبب التداخل، فقد يتعلم النظام سلوكًا غير آمن أو مسرفًا. كما تفترض العديد من الطرق القائمة توفر معرفة مسبقة غنية عن أنماط الحركة وسلوك الأجهزة، وهو أمر نادر في الشبكات الصناعية الحية. علاوة على ذلك، تُحسّن معظم الحلول موردًا واحدًا فقط في كل مرة—مثل القدرة الحاسوبية—مع تجاهل التخزين أو عرض النطاق الترددي للشبكة، مع أن الثلاثة يعملون معًا لتحديد الأداء في العالم الحقيقي.
التعلم من نسخة رقمية مماثلة
لكسر هذا الجمود، يجمع المؤلفون بين تخصيص الموارد وتقنية التوأم الرقمي. التوأم الرقمي هو نسخة افتراضية مفصّلة للشبكة الفيزيائية، مُدارة في السحابة. يعكس حالة خوادم الحافة والروابط والمهام على مر الزمن، باستخدام بيانات تاريخية غنية من المستشعرات والسجلات. في هذا العمل، لا يقتصر التوأم الرقمي على كونه لوحة عرض؛ بل يصبح ساحة تدريب. يستخدم النظام بيانات الماضي لتوليد أمثلة «خبيرة» لقرارات جيدة، تلتقط كيفية تقسيم المهام بين الحوسبة والتخزين المؤقت، وأين ينبغي معالجتها لتقليل التأخير. يحدث هذا التدريب دون الاتصال بالخدمات الحية، ويستفيد من قدرة السحابة الحاسوبية الكبيرة لاستكشاف العديد من الحالات المحتملة.
التقليد بدلًا من التجربة والخطأ
بدلاً من التعلم مباشرة من المكافآت، يتبنى نموذج E‑GAIL المقترح التعلم بالتقليد: يحاول الوكيل التصرف مثل الخبير. أولًا، يبني المؤلفون سياسات متعددة للخبراء باستخدام إطار Actor–Critic محسن بطبقة NoisyNet. تسمح حقن ضوضاء مضبوطة بعناية في شبكة اتخاذ القرار لهؤلاء الخبراء بتجربة مجموعة واسعة من الظروف—بما في ذلك اضطرابات تحاكي التداخل اللاسلكي الحقيقي وتقلبات أحمال العمل—بحيث تصبح مساراتهم أكثر واقعية. بعد ذلك، يقوم النظام بدمج عدة مسارات لخبراء منفردين في مرجعية واحدة «متعددة الخبراء» باستخدام أدوات من نظرية الألعاب. من خلال السعي إلى توازن نش بين الخبراء، يتجنب تعارضاتهم وينتج استراتيجية توافقية تغطي مجموعة أوسع من السيناريوهات المحتملة.
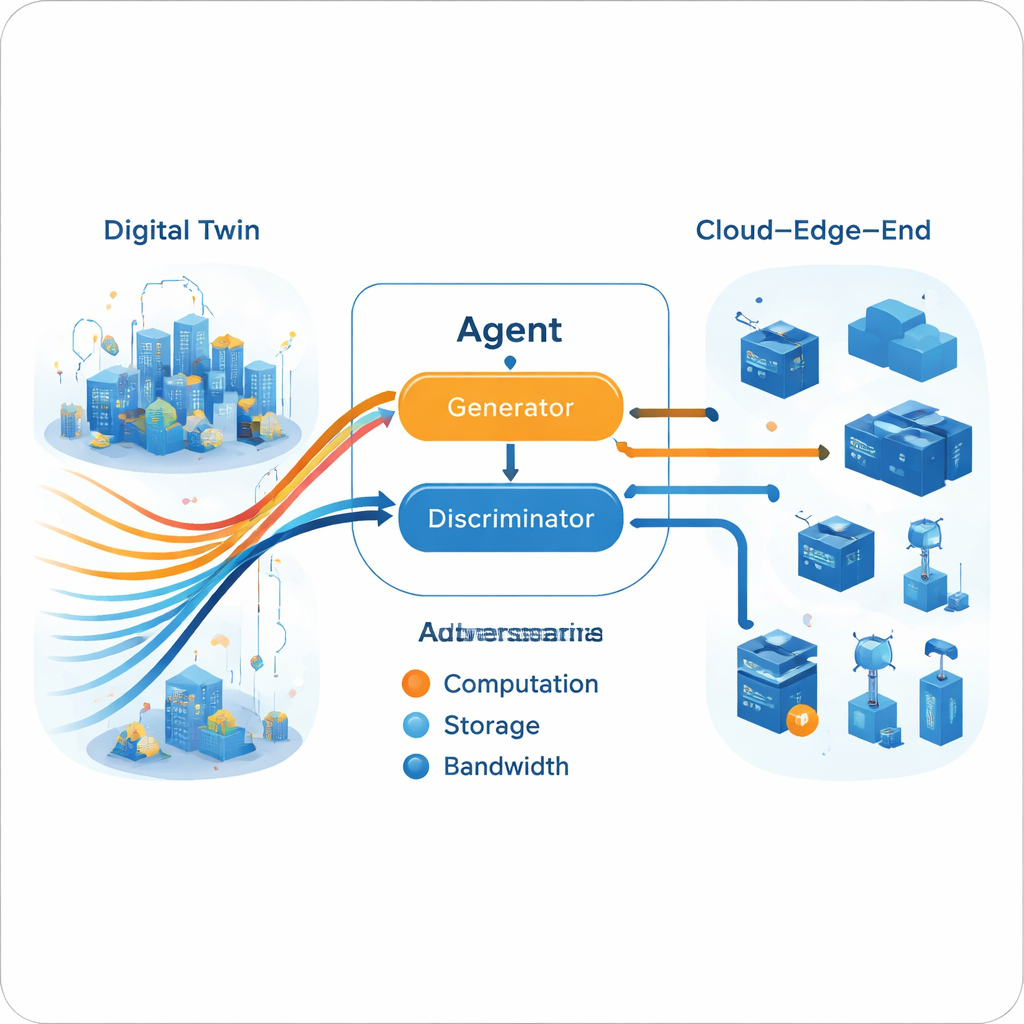
محرك تنافسي توليدي لاتخاذ القرارات
بمجرد بناء مسار الخبراء المتعدد في التوأم الرقمي، يتعلم الوكيل الحي تقليده باستخدام إعداد تنافسي توليدي، شبيه بالروح بنماذج الشبكات العصبية التي تولد الصور. يقترح المولّد إجراءات تخصيص موارد بناءً على حالة الشبكة الحالية، في حين يحاول المميّز التمييز بين ما إذا كانت سلسلة من الإجراءات صادرة من الوكيل أو من مسارات الخبراء. مع مرور الوقت، يدفع هذا اللعبة التنافسية المولد لإنتاج قرارات لا يستطيع المميّز تمييزها عن سلوك الخبراء. والأهم أن هذه العملية لا تتطلب دالة مكافأة صريحة من البيئة الحقيقية. يُقسَّم التدريب: تعلم مكثف غير متصل (في السحابة) يصقل الخبراء والمولد، بينما تُجرى تحديثات أخف وزنًا عبر الإنترنت (على الحافة) للحفاظ على توافق النموذج مع الظروف الحالية، بما يتوافق مع حدود أجهزة الحافة العملية.
ما مدى كفاءته؟
يختبر المؤلفون E‑GAIL مقابل عدة أساليب مرجعية شائعة، بما في ذلك Q‑learning العميق، والتفريغ القائم على نظرية الألعاب، وخوارزميات الجشع التقريبية، والمعالجة عبر السحابة فقط، والتخصيص العشوائي. عبر العديد من التجارب—بتغيير عدد الأجهزة الطرفية والقنوات وخليط المهام وأحمال العمل وأحجام البيانات والمسافات ونماذج الضوضاء—يحقق E‑GAIL باستمرار تأخيرات شاملة قريبة جدًا من تلك الخاصة بسياسة الخبير وبشكل ملحوظ أفضل من الأساليب الآلية الأخرى. يتكيف جيدًا عندما تنتقل المهام بين احتياج كبير للحوسبة واحتياج كبير للتخزين، عندما تكبر الشبكة، أو عندما يتكثف التداخل. يسرّع التوأم الرقمي توليد مسارات الخبراء ويحسن جودتها، بينما يوسّع دمج الخبراء المتعددين السيناريوهات التي يمكن للوكيل التعامل معها دون الحاجة لإعادة تدريب من الصفر.
ما المغزى لأنظمة الحياة اليومية
بالنسبة للقارئ غير المتخصص، الرسالة الأساسية هي أن هذا النهج يتيح للشبكات إدارة نفسها بذكاء أكبر في مواجهة عدم اليقين. بدلًا من صياغة قواعد يدوية أو الاعتماد على تعلم ضعيف هشّ مرتكز على التجربة والخطأ، يتعلم E‑GAIL من خبرات محاكاة غنية يوفّرها التوأم الرقمي ومن عدة «خبراء» متمرّسيْن يتم التوفيق بين نصائحهم بشكل رياضي. النتيجة هي مخصّص موارد قادر على اتخاذ قرار سريع بشأن مكان تشغيل المهام وأين تخزن البيانات، ما يحافظ على أزمنة استجابة منخفضة حتى مع تغير الظروف. في أنظمة المصانع والمدن الذكية المستقبلية، قد تتولى مثل هذه المنسقات المتعلّمة ذاتيًا تبديل الحوسبة والتخزين وعرض النطاق بهدوء وراء الكواليس، مما يجعل عالمنا المتصل أسرع وأكثر موثوقية وكفاءة في استهلاك الطاقة.
الاستشهاد: Zhang, X., Xin, M., Li, Y. et al. DT-aided resource allocation via generative adversarial imitation learning in complex cloud-edge-end scenarios. Sci Rep 16, 7657 (2026). https://doi.org/10.1038/s41598-026-38367-0
الكلمات المفتاحية: التوأم الرقمي, حوسبة الحافة, التعلم بالتقليد, تخصيص الموارد, الإنترنت الصناعي للأشياء