Clear Sky Science · ar
NeuroAction: نهج عصبي تطوري للتعلم المعزز للمركبات الذاتية
لماذا تهم أنماط القيادة الأذكى
يخيّل إلى معظمنا أن السيارات الذاتية القيادة سائقون هادئون وعقلانيون تمامًا. لكن أنظمة اليوم تميل إلى ملاحقة توازن واحد من الأهداف — مثل عدم التصادم مع الوصول السريع — وهذا التوازن يتم تضمينه من قبل المهندسين. يهدف نهج NeuroAction، الموضح في هذه الورقة، إلى منح السيارات الذاتية شيئًا أقرب إلى المرونة البشرية: القدرة على الاختيار من بين العديد من أساليب القيادة الآمنة، من سلوك حذر «طفل على متن المركبة» إلى الانطلاق السريع على الطريق السريع، دون إعادة تدريب السيارة في كل مرة.
من نموذج واحد يناسب الجميع إلى خيارات آمنة متعددة
تتعلم أنظمة التعلم المعزز العميق الحالية للقيادة عن طريق المحاولة والخطأ: تراقب الطريق، تتخذ إجراءات مثل التوجيه والتسارع، وتحصل على مكافأة رقمية واحدة تمزج بين أهداف مختلفة مثل السرعة والسلامة وموقع المسار. لضبط النظام، يجب على المهندسين تصميم تلك المكافأة الواحدة بعناية شديدة. إذا وُزنت السرعة بشكل مبالغ فيه، قد تقود السيارة بشكل عدواني؛ وإذا تم التركيز على السلامة بقوة، فقد تمشي السيارة ببطء. عادةً ما يعني تغيير التفضيلات لاحقًا العودة وإعادة تدريب شبكة عصبية كبيرة من الصفر، وهو أمر بطيء ويتطلب ذاكرة وحساس لإعدادات تقنية.
تقسيم القيادة إلى أهداف بسيطة
يتعامل NeuroAction مع هذا بتقسيم مهمة القيادة إلى عدة أهداف واضحة بدلًا من هدف واحد. في الدراسة، يُقيَّم السائق الافتراضي للسيارة بشكل مستقل على ثلاثة أمور: مدى سرعته داخل نطاق آمن، مدى تمسّكه بالبقاء في المسار الأيمن (الذي يكون عادةً أكثر أمانًا)، ومدى تجنبه للحوادث. بدلًا من دمج هذه المعايير في درجة واحدة، يعاملها الأسلوب كمؤشرات منفصلة. في الخلفية، يتم تقييم كل سياسة قيادة ممكنة — الشبكة العصبية التي تحول مدخلات المستشعرات إلى قرارات توجيه وسرعة — على المحاور الثلاثة معًا في آن واحد.
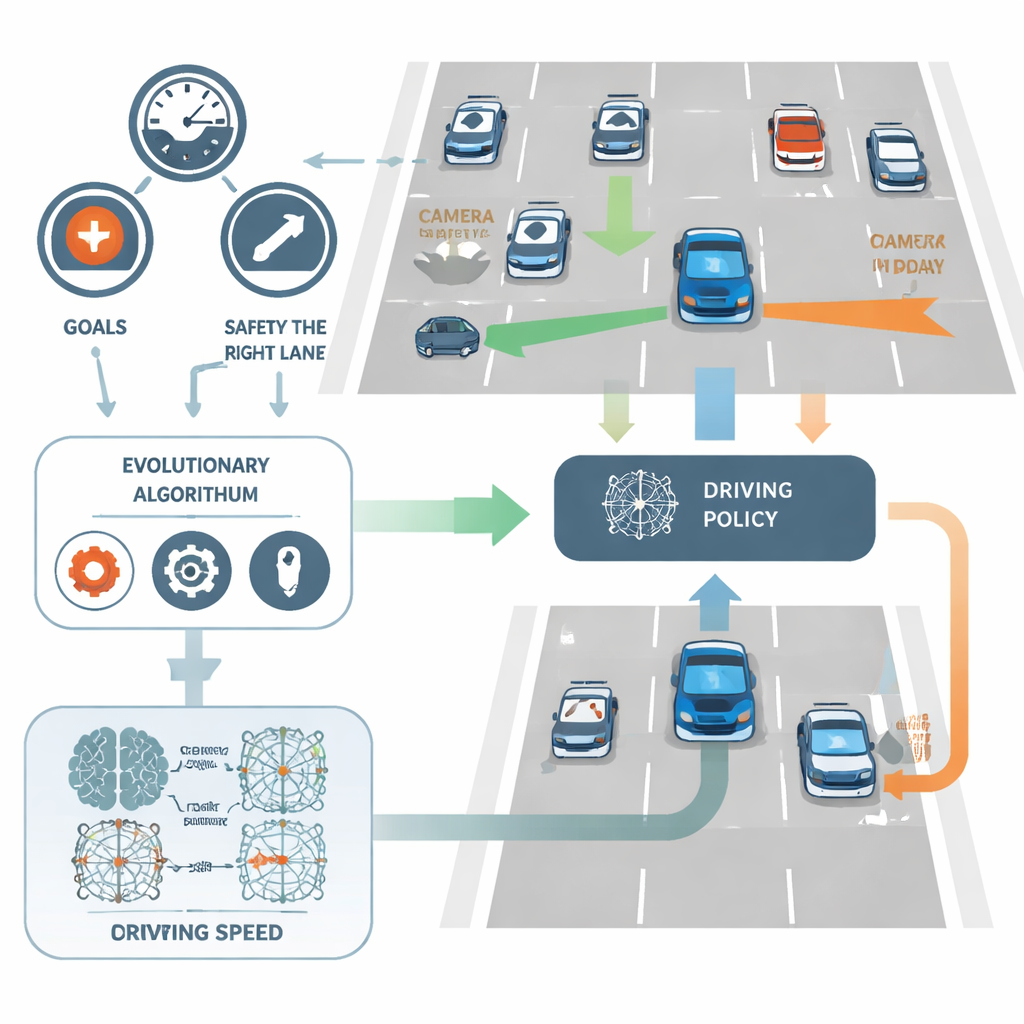
دع التطور يبحث عن سائقين أفضل
بدلًا من تعديل أوزان الشبكة بتقنية الانتشار العكسي التقليدية، يستخدم NeuroAction أفكارًا مستعارة من التطور البيولوجي. يتم إنشاء مجموعة من سياسات القيادة المختلفة واختبارها في بيئة محاكاة للطريق السريع. تُحتفظ بالسياسات التي تحقق توازنات جيدة بين السرعة والانضباط في المسار والسلامة وتُعاد مزاوجتها، بينما تُستبعد السياسات الأضعف. عبر أجيال عديدة، يكتشف هذا المسار التطوري مجموعة كاملة من الحلول القوية — المعروفة بحد بااريتو — حيث لا يمكن تحسين سياسة في هدف واحد دون التضحية بواحد على الأقل من الأهداف الأخرى.
مقارنة بين التعلم التطوري والتعلم المعتمد على التدرج
طبق الباحثون NeuroAction على محاكي طريق سريع ثنائي الأبعاد مستخدم على نطاق واسع، باستخدام وكيل قيادة قياسي قائم على الشبكات العصبية. ثم قاموا بتحسين معلمات الوكيل باستخدام عدة خوارزميات تطورية متعددة الأهداف معروفة، وقارنوا مدى تغطية كلٍّ منها لمجال التنازلات المرغوبة. مقياس أداء رئيسي، «الحجم الفائق» (hypervolume) للحد المكتشف، يجمع بين مدى جودة الحلول وتنوّعها. حققت إحدى الخوارزميات، NSGA-II، أفضل تغطية إجمالية، بينما قدمت قريبة لها، NSGA-III، نتائج متسقة بشكل خاص عبر تكرار التجارب.
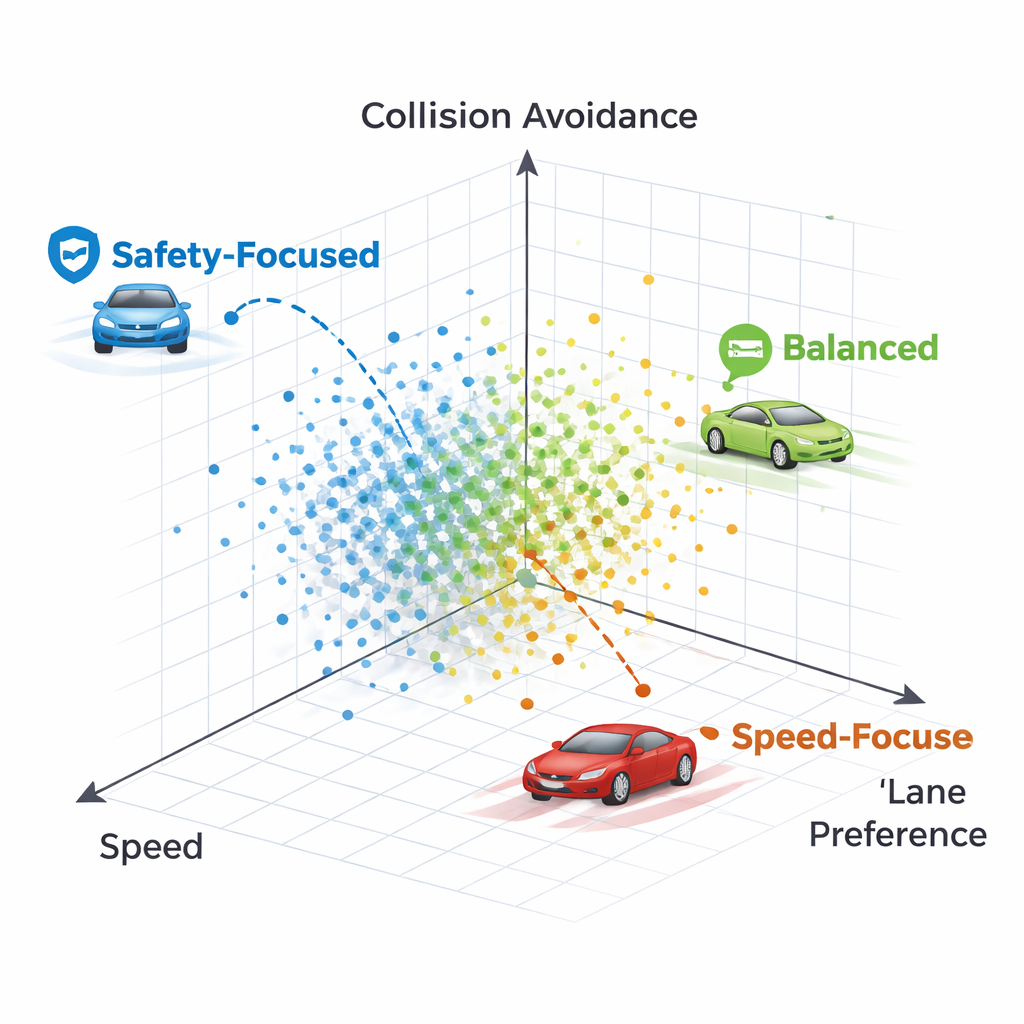
كيف تبدو أنماط القيادة المختلفة
من خلال فحص سياسات فردية على حد بااريتو، يبيّن المؤلفون أن كل نقطة تمثل أسلوب قيادة يمكن تمييزه. إحدى السياسات تبقى بحزم في المسار الأيمن تقريبًا مهما كلف الثمن، فتهاونت بالسرعة وفي النهاية اصطدمت بمركبة بطيئة جدًا أمامها — استراتيجية مفرطة الحذر تفضل تفضيل المسار أكثر من اللازم. سياسة أخرى تغير المسار مبدئيًا ثم تعود إلى مسار أيمن واضح، محافظة على سرعة أعلى مع تجنّب الحوادث. عمومًا، تنتج الطرق طيفًا من الاستراتيجيات يتراوح من السائقين المحافظين الملتزمين بالمسار إلى المتجولين الأكثر جرأة ولكن الآمنين، جميعها متاحة في آن واحد دون إعادة تدريب.
ما الذي يعنيه هذا لسيارات المستقبل الذاتية
لغير المتخصص، الرسالة الأساسية هي أن NeuroAction يحول تدريب السيارات الذاتية إلى بحث عن خيارات جيدة متعددة بدلًا من سلوك ثابت واحد. هذا يجعل من الممكن اختيار سياسة قيادة تناسب الموقف — بطيئة وفائقة الأمان عند نقل الأطفال، أسرع عندما تكون في عجلة — مع الالتزام بقيود السلامة. على الرغم من أن التجارب الحالية في محاكاة وتستخدم أهدافًا مبسطة، يشير الإطار إلى مركبات ذاتية أكثر تكيفًا ووعيًا بتفضيلات المستخدم يمكنها تقديم أنماط قيادة مخصصة وموثوقة معتمدًا على أساس رياضي متين.
الاستشهاد: Aboyeji, E., Ajani, O.S., Fenyom, I. et al. NeuroAction: a neuroevolutionary approach to reinforcement learning for autonomous vehicles. Sci Rep 16, 7403 (2026). https://doi.org/10.1038/s41598-026-38269-1
الكلمات المفتاحية: القيادة الذاتية, التعلم المعزز, خوارزميات تطورية, تحسين متعدد الأهداف, سيارات ذاتية القيادة