Clear Sky Science · ar
نموذج اقتران شبكي موجه بنماذج الرؤية-اللغة لمعالجة التدهور للاندماج الواعي للتدهور بين صور الأشعة تحت الحمراء والمرئية
رؤية ليلية أوضح لعالم مليئ بالضجيج
يمكن للكاميرات الحديثة أن ترى في الظلام، وتستشعر الحرارة، وتراقب الطريق من أجلنا—لكن لصورها كثيراً ما تكون بعيدة عن الكمال. أضواء الشوارع تتوهج، الظلال تبتلع التفاصيل، وأجهزة الاستشعار تضيف ضوضاء منقطة. تعرض هذه الدراسة طريقة جديدة لدمج فيديو ملون عادي مع صور الأشعة تحت الحمراء الحسية للحرارة بحيث تكون النتيجة أكثر وضوحاً واعتمادية، حتى عندما يكون كل من المدخلين متدهورين بشدة. قد تجعل هذه الطريقة السيارات الذاتية والأنظمة الأمنية والكاميرات الذكية الأخرى أكثر موثوقية في الظروف التي نحتاجها فيها أكثر: ليلاً، في الطقس السيئ، وفي المشاهد الحقيقية المزدحمة.
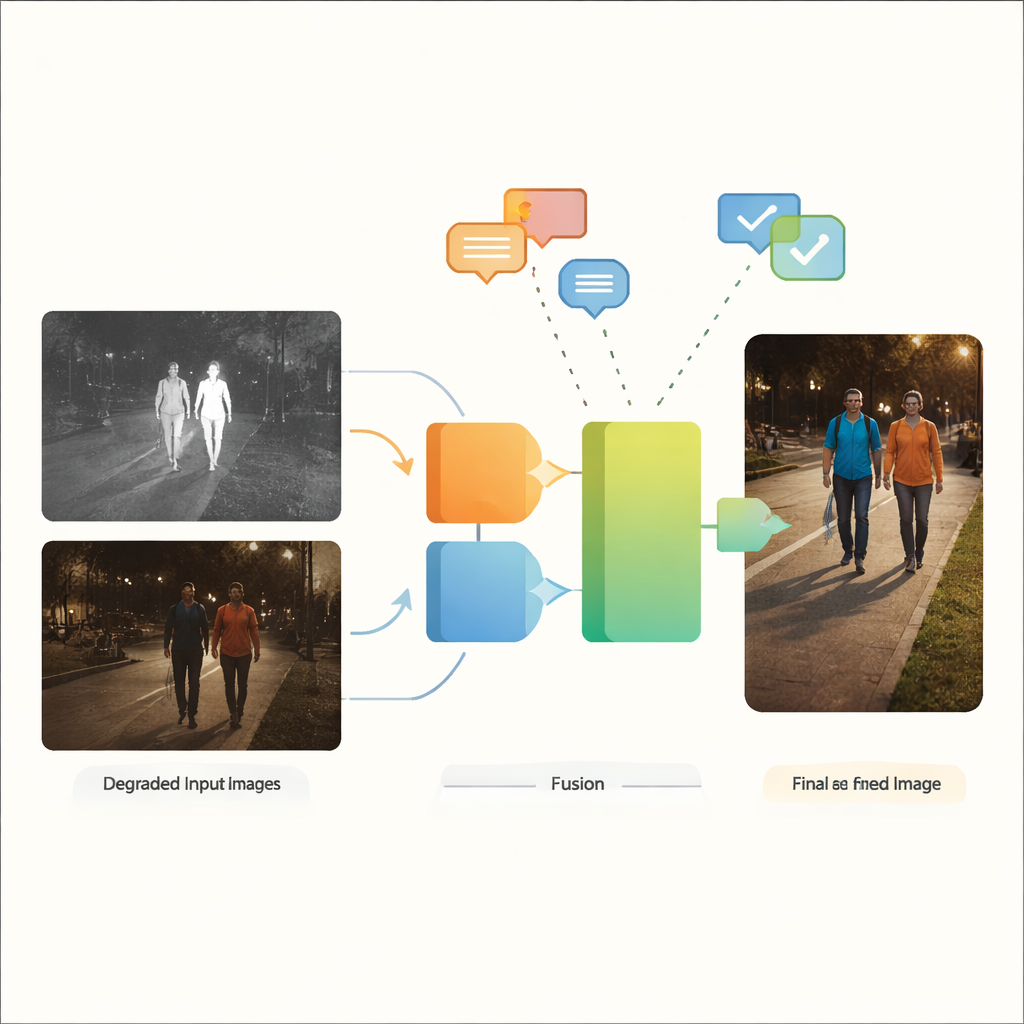
لماذا العينان أفضل من واحدة
تلتقط كاميرات الضوء المرئي الألوان والأنسجة الغنية التي اعتاد البشر رؤيتها، لكنها تكافح في الإضاءة المنخفضة والوهج والظلال الكثيفة. من ناحية أخرى، تستشعر كاميرات الأشعة تحت الحمراء الحرارة ويمكنها تمييز الأجسام الدافئة مثل الأشخاص أو المركبات في الظلام بسهولة، رغم أن صورها غالباً ما تبدو مسطحة وتفتقر إلى التفاصيل الدقيقة. يهدف اندماج صور الأشعة تحت الحمراء والمرئية إلى الجمع بين الأفضل من الاثنين: الحواف الواضحة للأهداف الدافئة من الأشعة تحت الحمراء مع التفاصيل السياقية والألوان من الضوء المرئي. ومع ذلك، تفترض معظم طرق الدمج التقليدية أن كلا الصورتين المدخلتين نظيفتان وعاليتا الجودة—وهو افتراض غير مناسب للشوارع والمدن والمواقع الصناعية الحقيقية حيث قد تكون الضبابية والضوضاء والإضاءة الخافتة والتعرض الزائد القاعدة وليس الاستثناء.
عندما تفشل المعالجة المسبقة
تعالج الأنظمة الحالية عادة الصور السيئة في خطوتين منفصلتين. أولاً، تضيء أدوات التحسين المنفصلة المشاهد المظلمة، وتقلل الضوضاء، أو تصحح التباين. ثم تقوم شبكة الدمج بخلط الصور المحسنة. لهذا النهج ثنائية المراحل عدة أوجه قصور. فهو يجبر المهندسين على اختيار وضبط أدوات تحسين مختلفة لكل نوع من العيوب ولكل مستشعر، مما يجعل سير العمل هشاً ومعقداً. والأهم من ذلك، أن أي معلومات فقدت أو تشوهت أثناء التنظيف المنفصل لا يمكن استعادتها لاحقاً في مرحلة الدمج. قدمت بعض الأبحاث الحديثة شبكات خاصة موجهة لنوع واحد من التدهور أو استخدمت نماذج موجهة بالنص للتعامل مع نمط واحد من المدخلات السيئة في كل مرة. ومع ذلك، عندما تكون كلتا الصورتين—الأشعة تحت الحمراء والمرئية—متدهورتين وغالباً بطرق مختلفة، تظل هذه الاستراتيجيات تعتمد بشكل كبير على المعالجة المسبقة اليدوية وتجد صعوبة في التعامل مع الظروف المختلطة والواقعية.
شبكة دمج تفهم التدهور
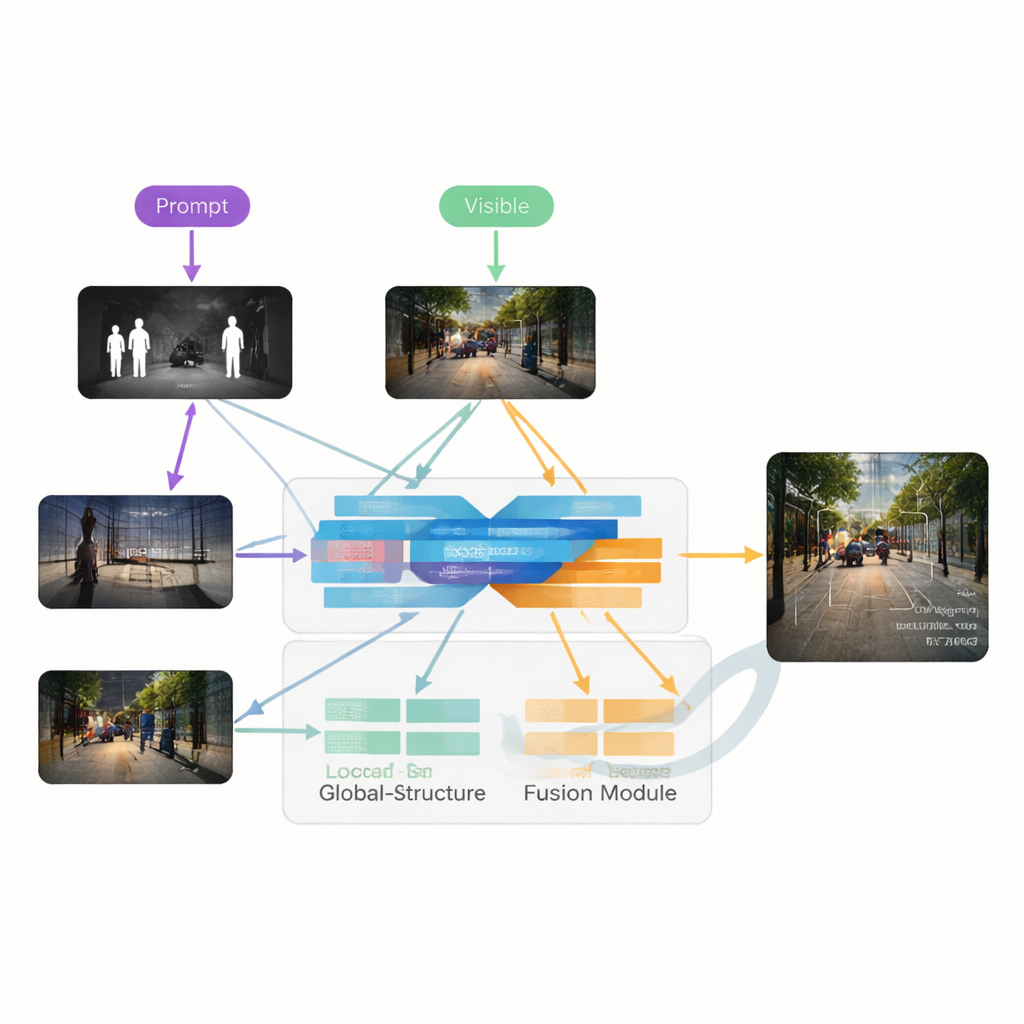
يقترح المؤلفون VGDCFusion، إطار تعلم عميق جديد يدمج معالجة التدهور مباشرة في عملية الدمج. الفكرة الأساسية هي إعلام الشبكة، بكلمات، بنوعية المشكلات التي يجب أن تتوقعها، ثم استخدام تلك المعرفة في كل خطوة من استخراج ودمج الميزات. تصف موجهات نصية قصيرة المهمة (الاندماج بين الأشعة تحت الحمراء والمرئية) والقضايا المحددة الموجودة، مثل الإضاءة المنخفضة، التعريض الزائد، التباين المنخفض أو الضوضاء. يحول نموذج رؤية-لغة قوي—مشابه روحياً لأنظمة مثل CLIP—هذه الموجهات إلى أوصاف رقمية مدمجة. توجه هذه الأوصاف لبنتين رئيسيتين: مستخلص اقتران التدهور بالموجه الخاص (SPDCE)، الذي يعمل بشكل منفصل على كل نمط، ودمج اقتران التدهور بالموجه المشترك (JPDCF)، الذي يمزج المعلومات عبر النمطين مع الاستمرار في الانتباه لنوعية التدهور المتبقي.
كيف يعمل عملية الدمج الموجهة
داخل كل وحدة SPDCE، توجه الإرشادات المشتقة من الموجه الشبكة نحو الميزات المهمة والابتعاد عن الشوائب. تنظر طبقات الالتفاف متعددة المقاييس إلى الأحياء الصغيرة للحفاظ على الحواف والأنسجة، بينما تلتقط طبقات الترانسفورمر البنية والسياق على نطاق أوسع. تعمل معاً لتتعلم إبراز، على سبيل المثال، تواقيع الحرارة المهمة في إطار أشعة تحت الحمراء مليء بالضوضاء أو علامات الطريق الخافتة في صورة مرئية ناقصة التعريض، مع كبت ضوضاء المستشعر وعيوب الإضاءة. بالتوازي، تأخذ وحدات JPDCF الميزات المنقّاة من الفرعين وتجمعها، مرة أخرى تحت توجيه الموجه. تستخدم الانتباه المكاني وقنوي لتسليط الضوء على المناطق المعلوماتية، ترشيح التدهور المتبقي، وجمع القرائن التكميلية—مثل محاذاة مخطط واضح بالأشعة تحت الحمراء لمشاة مع اللون وبنية الخلفية من الكاميرا المرئية—قبل إعادة بناء صورة مدمجة بثلاث قنوات.
وضع الطريقة على المحك
لاختبار فائدته، قيّم الفريق VGDCFusion على عدة مجموعات بيانات عامة تتضمن صوراً مرئية منخفضة الإضاءة ومبالغ في تعريضها بالإضافة إلى صور أشعة تحت حمراء صاخبة أو منخفضة التباين. قارنوا طريقتهم مع مجموعة من تقنيات الدمج الحديثة التي تشمل المشفرات الذاتية، والشبكات الالتفافية، وشبكات الخصومة التوليدية، والـTransformers. باستخدام مقاييس جودة الصورة القياسية، أنتج VGDCFusion بصورة ثابتة صوراً مدمجة ذات حواف أكثر حدة، وتباين أفضل، وألوان أكثر طبيعية، حتى عندما مُنحت الطرق المنافسة ميزة المعالجة المسبقة المضبوطة بعناية. حسّن النهج الجديد المؤشرات الرئيسية بحوالي 15% في المتوسط في السيناريوهات المتدهورة بشدة. وعندما أدخلت الصور المدمجة في نظام كشف الأشياء الشائع، أدى ذلك أيضاً إلى دقة كشف أعلى مقارنة باستخدام صور الأشعة تحت الحمراء أو المرئية بمفردها، أو مقارنة باستخدام شبكات دمج أخرى.
رؤية أوضح لأنظمة أكثر أماناً
بعبارات بسيطة، تُظهر هذه الدراسة أن إخبار شبكة دمج الصور بأنواع المشكلات البصرية المتوقعة—وتمكينها من الإصلاح والدمج في خطوة متصلة بإحكام—يمكن أن يولد صوراً أنظف وأكثر معلوماتية من التعامل مع التحسين والاندماج كمهمتين منفصلتين. من خلال ربط نمذجة التدهور بعملية الدمج واستخدام إشارات موجهة بالنص في كل طبقة، يستطيع VGDCFusion التكيّف مع أشكال متنوعة ومختلطة من تدهور الصورة دون إعادة ضبط بشرية مستمرة. يمكن أن يساعد هذا النوع من الدمج الذكي الواعي بالتدهور أنظمة الرؤية المستقبلية، من سيارات ذاتية القيادة إلى كاميرات الأمن، على الرؤية بمزيد من الاعتمادية في ظروف العالم الواقعي الفوضوية والناقصة الكمال.
الاستشهاد: Zhao, J., Zhang, T. & Cui, G. A VLM guided network coupling degradation modeling for degradation aware infrared and visible image fusion. Sci Rep 16, 8249 (2026). https://doi.org/10.1038/s41598-026-38181-8
الكلمات المفتاحية: اندماج الأشعة تحت الحمراء والمرئية, التصوير في الإضاءة المنخفضة, نماذج الرؤية واللغة, تدهور الصورة, إدراك القيادة الذاتية