Clear Sky Science · ar
إطار تعلم مكدّس هجين للكشف متعدد الوسوم عن عواطف النص
لماذا يهم قراءة العواطف في النص
يعبّر الناس يومياً عن مشاعرهم في منشورات وسائل التواصل الاجتماعي والتقييمات والرسائل. في هذا السيل من الكلمات تكمن إشارات مبكرة حول مشاكل الصحة النفسية، وتصاعد خطاب الكراهية، وردود الفعل العامة تجاه الأزمات والكوارث. لكن الحواسيب غالباً ما ترى فقط «موقفاً» إيجابياً أو سلبياً، فتفوت خليط العواطف التي يعبر عنها الناس في آن واحد. يستعرض هذا المقال طريقة جديدة لتعليم الآلات التعرف على عدة عواطف في قطعة نصية واحدة، وليس فقط بالإنجليزية بل أيضاً باللغات التي نادراً ما تستفيد من تقنيات الذكاء الاصطناعي المتقدمة.
الانتقال إلى ما بعد الإيجابي أو السلبي البسيط
تشبه أدوات تحليل المشاعر التقليدية موازين حرارة خشنة: يمكنها أن تخبرك ما إذا كان المزاج جيداً أم سيئاً، لكنها لا تميز ما إذا كان الشخص يشعر بغضب أو خوف أو أمل أو ارتياح في الوقت نفسه. يرى الباحثون أن فهم هذه اللوحة العاطفية الأثرى أمر حاسم لتطبيقات مثل الاستجابة للكوارث، والدعم العلاجي، وخدمة العملاء. قد يتطلب رسالة تجمع بين الخوف والعجلة مثلاً اهتماماً فورياً، بينما قد يحتاج مزيج الحزن والتفاؤل إلى نوع مختلف من الدعم. لذا فإن التقاط عدة عواطف بالتوازي — المعروف باسم «كشف العواطف متعدد الوسوم» — هو خطوة أساسية نحو أنظمة أكثر حساسية ووعياً إنسانياً.
منح صوت للغات المهمَلة
تُدرّب وتُحسَّن أقوى تقنيات اللغة غالباً على الإنجليزية وعدة لغات واسعة الانتشار. ويتعرض متحدثو اللغات قليلة الموارد — أي تلك التي تملك بيانات معنونة قليلة وأدوات رقمية محدودة — للتهميش. لمواجهة هذه الفجوة، ركز الباحثون على ثلاث مجموعات بيانات: معيار معروف لعواطف الإنجليزية؛ مجموعة باللغة الإندونيسية (Bahasa Indonesia) تركز على اللغة المسيئة والكرائية؛ ومجموعة هوسا جديدة على تويتر أنشأوها باسم HaEmoC_V1. تتضمن مجموعة هوسا أكثر من اثني عشر ألف تغريدة منظفة ومعنونة بعناية، ووسِمَت كل واحدة بواحدة أو أكثر من أحد عشر شعوراً مثل الغضب، الفرح، الثقة، التشاؤم، والترقب. راجع خبراء الوسوم، وأظهرت مقاييس التوافق أن العلامات متسقة وموثوقة.
دمج عدة قراء أذكياء في واحد
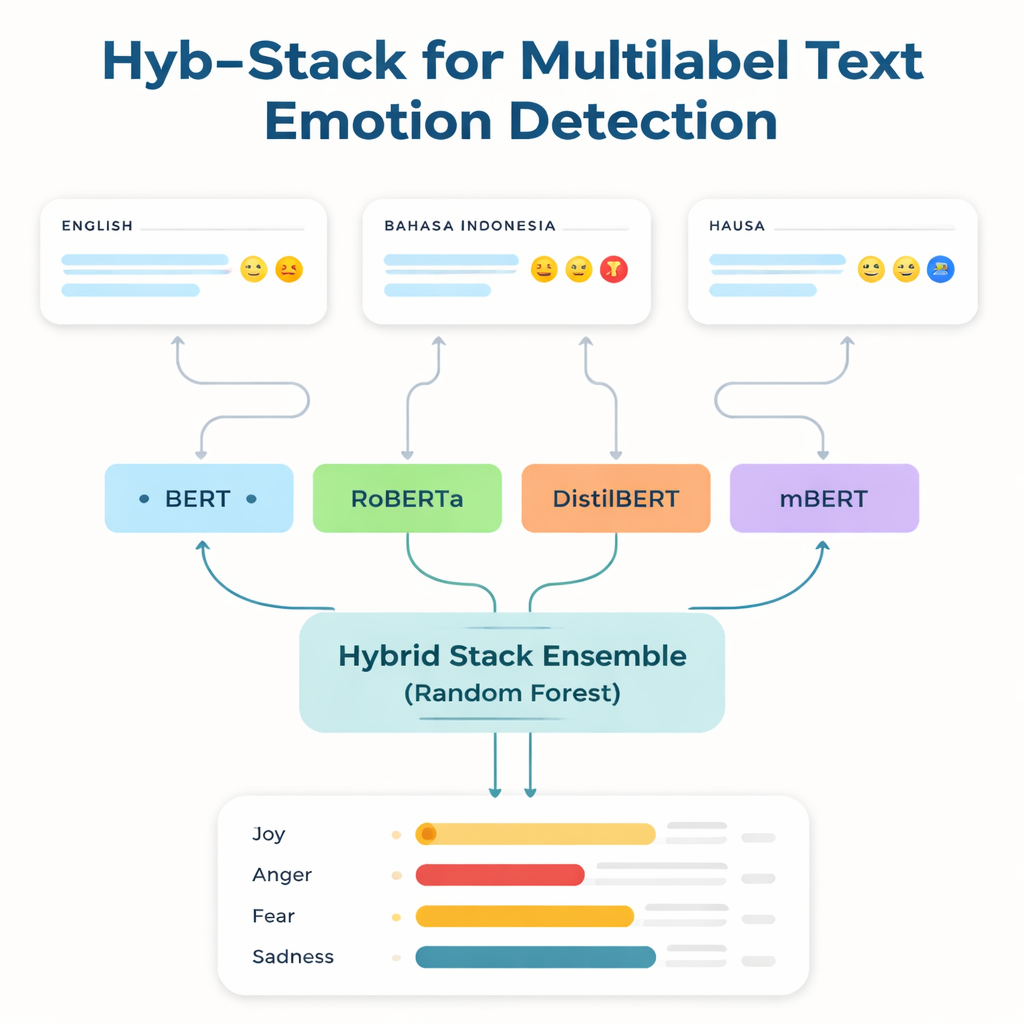
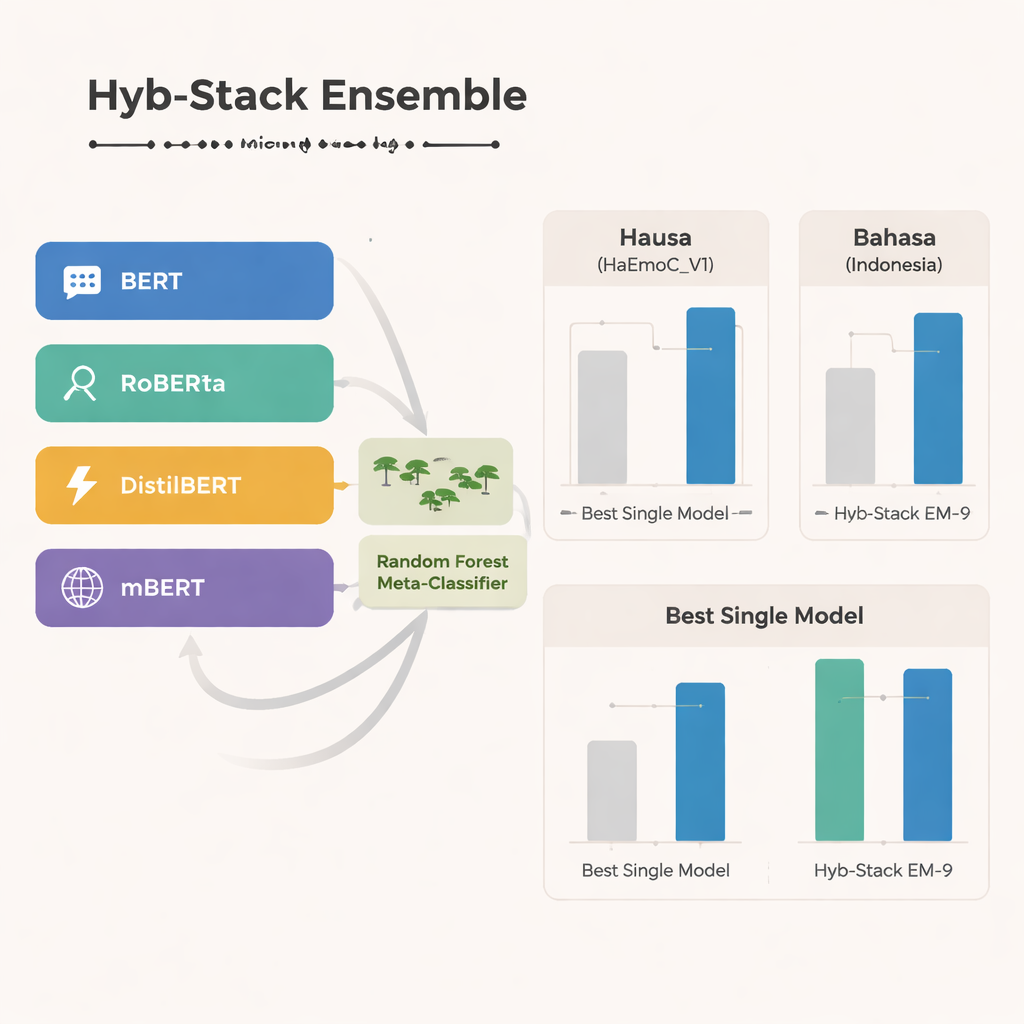
في صميم الدراسة يقبع Hyb-Stack، وهو مكدس هجيني للتجميع — نوع من «لجنة الخبراء» للغة. تم ضبط أربعة نماذج متقدمة قائمة على محولات (BERT، RoBERTa، DistilBERT، وmBERT متعدد اللغات) لالتقاط الإشارات العاطفية في النص. بدلاً من الاعتماد على نموذج واحد فقط، يسمح Hyb-Stack لها جميعاً بإصدار توقعات، ثم يمرر درجاتها الداخلية إلى صانع قرار من المستوى الثاني: مصنف الغابات العشوائية (Random Forest). يتعلم هذا الميتا-مصنف كيفية وزن نقاط القوة المختلفة لكل نموذج، والتقاط أنماط معقدة في تزامن العواطف. كما اختبر الفريق طرق تجميع أبسط تجري متوسط التوقعات فقط، مع أو بدون وزن حسب الأداء السابق، ليفحصوا ما إذا كان التكديس الأكثر تعقيداً يستحق العناء فعلاً.
كيف أداء النهج الهجين
عبر اللغات الثلاث، برز نموذج mBERT متعدد اللغات كنموذج فردي أقوى، وأظهر أداءً جيداً خصوصاً على بيانات الهوسا البُنية حديثاً ومجموعة خطاب الكراهية باللغة البنغالية الإندونيسية. ومع ذلك، يحقق التجميع الهجين نتائج أفضل. تركيبة محددة — تسمى EM-9، والتي تدمج BERT وDistilBERT وmBERT داخل إطار Hyb-Stack — تقدم باستمرار أفضل النتائج. تحقق نقاط F1 أعلى، وهو مقياس شائع للدقة، مقارنة بأي نموذج فردي أو نهج متوسط بسيط، مع أكبر مكاسب في مجموعات البيانات قليلة الموارد مثل هوسا وبهاسا إندونيسيا. تُظهر تحليلات الأخطاء التفصيلية أن الأخطاء المتبقية عادة ما تحدث بين عواطف متقاربة، مثل الفرح مقابل الدهشة أو الحزن مقابل الخوف، ما يعكس غموض المشاعر البشرية الطبيعي أكثر من فشل صريح للنظام.
ماذا يعني هذا للأنظمة الواقعية
للقارئ العام، الخلاصة الرئيسية هي أن الجمع بين عدة نماذج ذكاء اصطناعي بطريقة ذكية يمكن أن يساعد الحواسيب على قراءة العواطف في النص بدقة أكبر، لا سيما في اللغات التي طالما أُهملت في التكنولوجيا. من خلال بناء مجموعة بيانات عالية الجودة لعواطف الهوسا وإظهار أن التجميعات الهجينة تتفوق على النماذج الفردية وطرق التصويت البسيطة، يعرض المؤلفون مساراً عملياً نحو أدوات أكثر شمولية ووعياً عاطفياً. سيشمل العمل المستقبلي توسيع النهج ليشمل درجات عاطفية أدق، واللغات المختلطة (code-mixed)، والرموز التعبيرية، ولغات ممثلة تمثيلاً أقل، بهدف إنشاء أنظمة تستطيع الإحساس ليس فقط بما إذا كان الناس سعداء أم حزينين، بل كيف ولماذا يشعرون بتلك الطريقة — بغض النظر عن اللغة التي يتحدثونها.
الاستشهاد: Adamu, H., Azmi Murad, M.A. & Nasharuddin, N.A. A hybrid stacked ensemble learning framework for multilabel text emotion detection. Sci Rep 16, 7714 (2026). https://doi.org/10.1038/s41598-026-38172-9
الكلمات المفتاحية: كشف العواطف, المعالجة اللغوية المتعددة اللغات, تعلم التجميع, نماذج التحويل, اللغات قليلة الموارد