Clear Sky Science · ar
تصحيح الوسوم المزعجة عبر التقطير المقارن: نهج للتكيّف عبر المجالات
لماذا أصبحت البيانات الفوضوية مشكلة متصاعدة
تزدهر الذكاء الاصطناعي الحديث بالاعتماد على البيانات، لكن تلك البيانات غالبًا ما تكون خاطئة أو ناقصة أو معنونة بشكل غير متسق. عندما تكون الوسوم مضللة—مثل صورة قطة موسومة ككلب—قد تنخدع أنظمة التعلّم وتفقد دقتها وموثوقيتها. تتناول هذه الورقة هذه المشكلة الواقعية: كيفية تدريب أنظمة تعرف على الصور تعمل جيدًا حتى عندما تكون الوسوم في مجموعة التدريب معيبة وتأتي الصور من بيئات مختلفة، مثل متاجر الإنترنت مقابل صور العالم الحقيقي.
التعلّم عبر عوالم مختلفة
في الواقع العملي، غالبًا ما تتعلّم نماذج الذكاء الاصطناعي من «عالم مصدر» تُراجع فيه الوسوم بعناية، ثم يجب أن تُؤدّي في «عالم هدف» تكون فيه الوسوم نادرة وعرضة للأخطاء. على سبيل المثال، تُصوَّر أدوات المكتب في استوديو بترتيب ووسوم صحيحة، بينما تكون صور الويبكام أو الصور اليومية للأشياء نفسها فوضوية وموسومة بشكل غير متسق. تحاول أساليب التكيّف التقليدية ردم هذه الفجوة بمطابقة الإحصاءات العامة للعالمين. ومع ذلك، فإنها عادةً ما تفترض أن وسوم الهدف، عند توافرها، صحيحة—وهو افتراض محفوف بالمخاطرة ينهار في تطبيقات العالم الحقيقي التي تعتمد على وسم الجمهور، أو حساسات منخفضة الجودة، أو أدوات التعلّم الآلي الآلية.
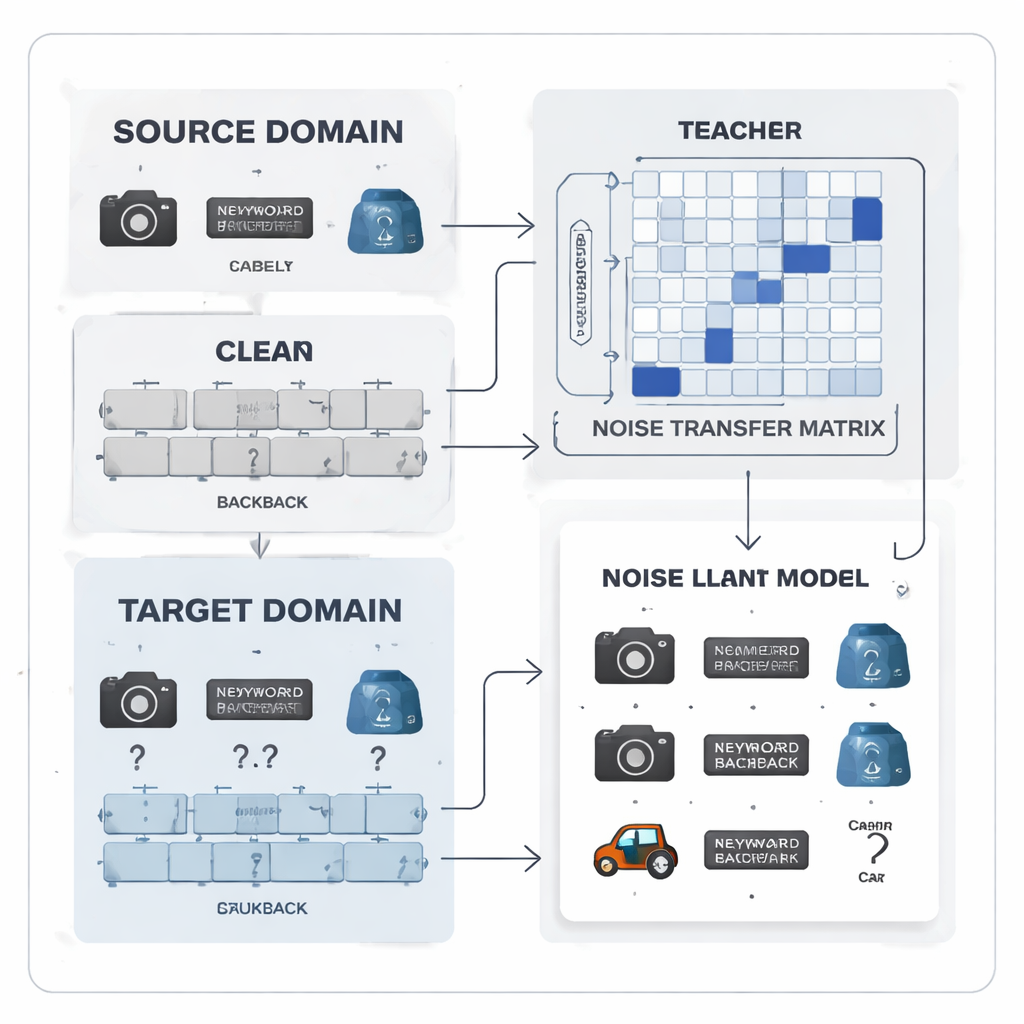
تحويل أخطاء الوسم إلى نمط قابل للتعلّم
يقترح المؤلفون التعامل مع ضوضاء الوسوم ليس كفوضى عشوائية بل كنمط يمكن تعلّمه. يقدمون «مصفوفة نقل الضوضاء»، جدول يلتقط احتمالية أن يتم وسم كل فئة حقيقية كفئة أخرى بالخطأ. بدلًا من تقدير هذا الجدول من عدد محدود من أمثلة «مرساة» مثالية—وهذا غير واقعي عندما تكون الوسوم مضللة والفئات غير متوازنة—فإن المصفوفة تُتعلم مباشرة أثناء التدريب. لبدء عملية التعلّم، يبني الأسلوب «نماذج أولية» لكل فئة، وهي بصمات ميّزة متوسطة لكل فئة مستخرجة بواسطة نموذج قوي مدرّب مسبقًا. تُستخدم درجة التشابه بين هذه النماذج الأولية لتهيئة المصفوفة بحيث ترتبط الفئات القابلة للخلط، مثل أدوات المكتب المتشابهة، بقوة أكبر من البداية، ما يمنح النظام قدرة مبكرة على تصحيح الوسوم.
عمل جماعي بين المعلم والطالب لإشارات أنظف
في صلب النظام زوج من الشبكات العصبية على شكل معلم–طالب. المعلم قائم على نموذج بصري كبير مُدرّب ذاتيًّا تعلّم ميزات بصرية غنية من بيانات ضخمة غير معنونة. الطالب شبكة أخف يجب أن تؤدّي جيدًا على بيانات الهدف المليئة بالضوضاء. ينتج المعلم درجات تنبؤ ناعمة تكشف عن مدى ارتباط الفئات؛ ومن هذه الدرجات تُبنى مصفوفة ارتباط الفئات التي تلخّص أي الوسوم تميل إلى التكرار المشترك. تعمل هذه المصفوفة كدليل يدفع مصفوفة نقل الضوضاء نحو تصحيحات أكثر واقعية. في الوقت نفسه، يُدرّب الطالب على مطابقة سلوك المعلم عبر عملية تعرف بالتقطير، بينما يشجّع التعلّم التبايني كلا الشبكتين على إعطاء تمثيلات داخلية متقاربة لنسخ مُعدَّلة مختلفة من نفس الصورة وتمثيلات متميزة لأشياء مختلفة.
المحافظة على استقرار التصحيحات وتجنب الثقة المفرطة
السماح لمصفوفة نقل الضوضاء بالتغير بحرية قد يجعلها غير مستقرة أو حسّاسة مبالغًا فيها للشواذ. لمنع ذلك، يستخدم المؤلفون خدعة رياضية مبنية على تحليل القيمة المفردة، الذي يكسر المصفوفة إلى اتجاهات شدّ أساسية. من خلال معاقبة «الحجم» الكلي المستلهم من هذه الاتجاهات، يُثبط الأسلوب التشوّهات القصوى التي قد تضخّم الضوضاء. تظهر مشكلة أخرى عندما يصبح النموذج واثقًا جدًا من نفسه، مخصِّصًا تقريبًا كل الاحتمالية لفئة واحدة؛ تحت مثل هذه التنبؤات الحادة، يصعب تعديل الوسوم الخاطئة. لمعالجة ذلك، يضيف الأسلوب شكلًا من أشكال تنظيم الإنتروبيا، مستندًا إلى إنتروبيا تساليس، للحفاظ على احتمالات التنبؤ أكثر نعومة. هذا يجعل من الأسهل لمصفوفة نقل الضوضاء إعادة تخصيص كتلة احتمالية جزئيًا من فئة غير صحيحة إلى بدائل أكثر واقعية.
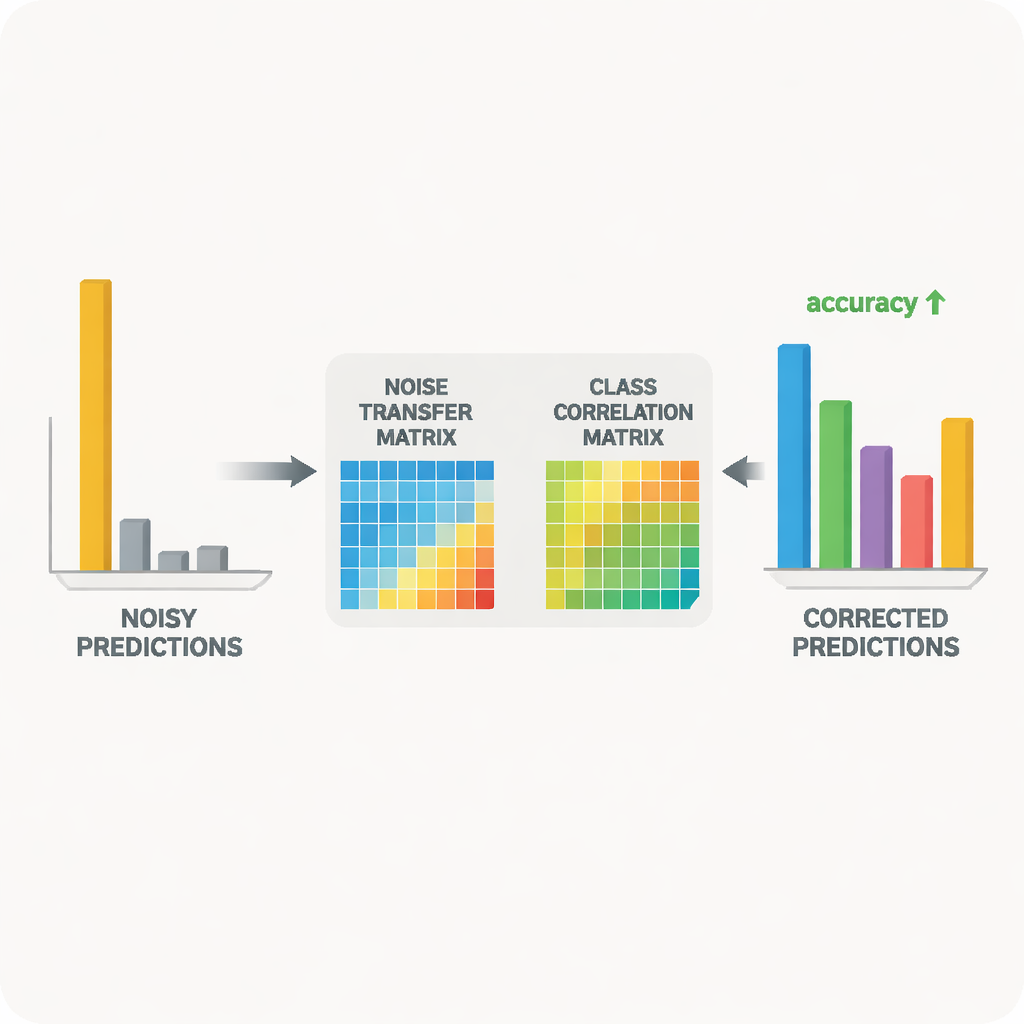
إثبات الفكرة على مجموعات صور حقيقية
اختبر الباحثون منهجهم على معيارين مستخدمين على نطاق واسع للتعرّف عبر المجالات: Office‑31 وOffice‑Home، اللذين يتضمّنان صورًا لأدوات مكتب يومية عبر أنماط متعددة مثل صور المنتج، والرسوم التوضيحية، واللقطات الحقيقية. عبر مجموعة من مهام «التدريب على نمط واحد، والاختبار على آخر»، طابقت طريقتهم أو تجاوزت الخوارزميات الرائدة، لا سيما في أصعب الحالات حيث يكون التحول بين المجالات أكبر. أظهرت دراسات مفصّلة أن كل مكوّن—تحكّم الحجم لمصفوفة الضوضاء، وإرشاد ارتباط الفئات، وتنعيم الإنتروبيا—أضاف مكاسب قابلة للقياس. وأكدت تصوّرات المصفوفة المتعلّمة ومساحة الميزات أنه، على مدار التدريب، تم سحب الأمثلة الموسومة خطأ تدريجيًا نحو فئاتها الصحيحة وأن توزيعات صور المصدر والهدف أصبحت أكثر توافقًا.
ماذا يعني هذا لأنظمة الذكاء الاصطناعي اليومية
بالنسبة لغير المتخصّصين، الخلاصة الأساسية أن هذا العمل يجعل نماذج الذكاء الاصطناعي أكثر تسامحًا مع أخطاء البشر والآلات في وسم البيانات، خصوصًا عندما تضطر هذه النماذج إلى الانتقال من ظروف المختبر النظيفة إلى بيئات العالم الحقيقي الأكثر فوضوية. من خلال تعلّم كيفية انحراف الوسوم صراحةً واستخدام نموذج معلم قوي لتوجيه التصحيحات، يمكن للطريقة تنظيف إشارات التدريب المزعجة وإنتاج مصنفات أكثر دقة وصلابة. وعلى الرغم من أن النهج يتطلب حسابًا إضافيًا، فإنه يشير إلى مستقبل يمكن فيه استغلال مجموعات البيانات الكبيرة وغير الكاملة المجمعة «في البرية» بشكل أكثر أمانًا وفعالية، مما يقلّل اعتمادنا على الوسم اليدوي المتعب.
الاستشهاد: Feng, Y., Liu, J. & Zhong, H. Correcting noisy labels via comparative distillation: a domain adaptation approach. Sci Rep 16, 7422 (2026). https://doi.org/10.1038/s41598-026-37935-8
الكلمات المفتاحية: وسوم مضللة, التكيّف عبر المجالات, تقطير المعرفة, تصنيف الصور, التعلّم شبه المراقب