Clear Sky Science · ar
نقاد توزيعيون توأمان حساسون للمخاطر مع حد ثقة سفلي لامبدا للتحكم المستمر في التعلم المعزز
تعليم الروبوتات الحذر
تعتمد العديد من الروبوتات والبرامج المتميزة في الألعاب اليوم على التعلم المعزز، وهو عملية تدريب تقوم على التجربة والخطأ حيث يتعلّم الوكلاء البرمجيون عبر جمع المكافآت. لكن هؤلاء الوكلاء غالبًا ما يسعون وراء أعلى نتيجة ممكنة متجاهلين مخاطر قراراتهم، مما يؤدي إلى تعلم غير مستقر وحوادث عرضية. تقدم هذه الورقة طريقة تسمى TDC-λ (نقاد توزيعيون توأمان مع حد ثقة سفلي لامبدا) تعلم هؤلاء الوكلاء ليس فقط أن يستهدفوا نتائج عالية، بل أيضًا أن يبقوا بأمان موثوق أثناء التعلم.
لماذا الاستقرار مهم في آلات التعلم
مكنت خوارزميات التحكم المستمر القياسية، مثل TD3 وSoft Actor–Critic (SAC) واسعة الاستخدام، الروبوتات من الجري والقفز والتوازن في محاكيات معقدة. ومع ذلك، تقيم هذه الأساليب عادة كل إجراء باستخدام رقم واحد: تقدير مقدار المكافأة التي سيجلبها على المدى الطويل. قد يكون ذلك التقييم المبسط مضللاً عندما يكون سير التعلم ضوضائيًا، مما يجعل النظام يبالغ في تقدير جودة بعض الإجراءات. النتيجة هي منحنى تعلم قد يبدو قويًا في المتوسط لكنه يتقلب بشدة من تجربة لأخرى، وهو أمر مقلق إذا كان من المقرر أن يتحكم نفس الخوارزم في آلات فعلية أو أنظمة حرجة للسلامة.
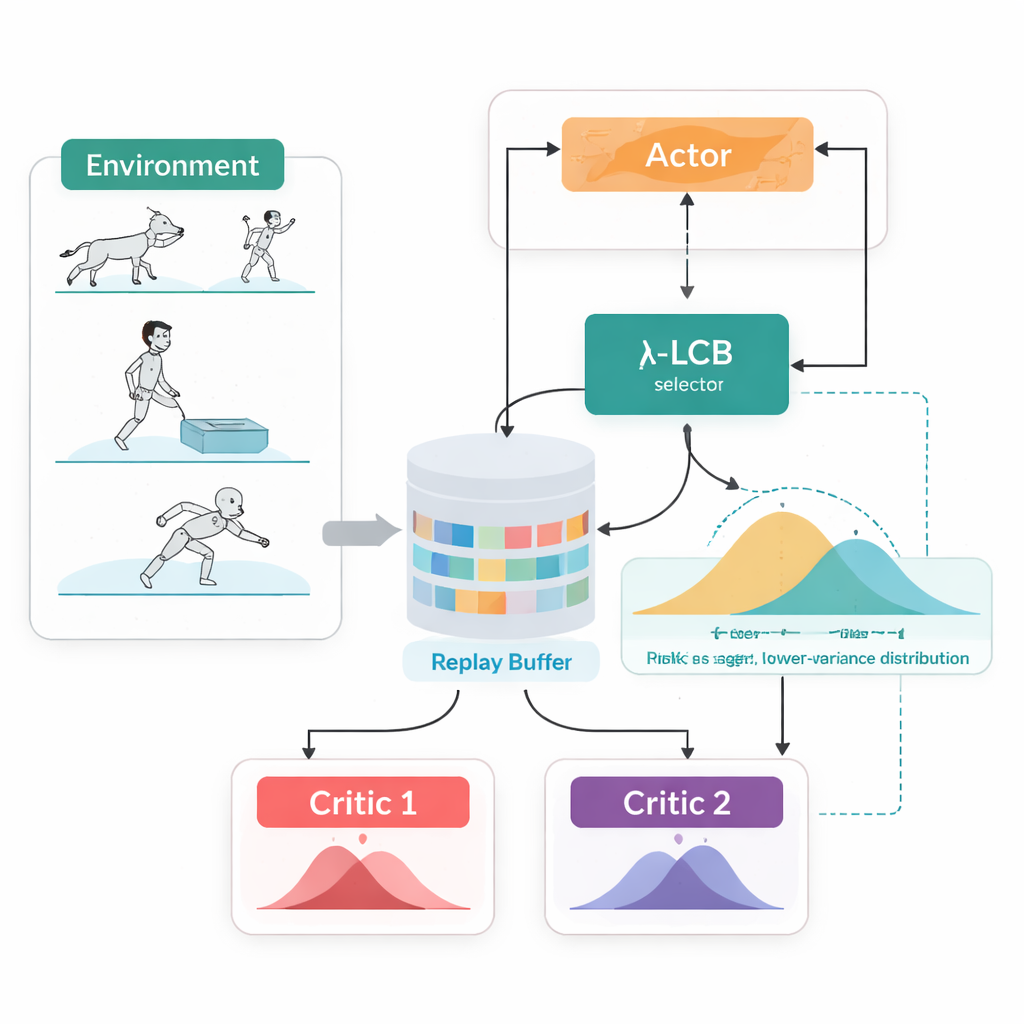
النظر إلى المستقبل الكامل، لا إلى رقم واحد
تعالج TDC-λ هذه المشكلة بتغيير طريقة تقييم الوكيل لمستقبله. بدلًا من توقع مكافأة متوقعة واحدة لكل إجراء، يتعلم ناقدان منفصلان لكل منهما توزيعًا كاملاً للعوائد المستقبلية الممكنة. من هذه التوزيعات، تحسب الخوارزمية ليس فقط المتوسط المتوقع ولكن أيضًا مدى تشتت الاحتمالات. يعكس هذا التشتت عدم اليقين أو المخاطرة. باستخدام قاعدة بسيطة تُلخّص كحد ثقة سفلي، تفضّل TDC-λ الناقد الذي يتنبأ بنتيجة أكثر أمانًا: قد تكون أقل تفاؤلًا بقليل لكنها مدعومة بأدلة أكثر اتساقًا. إعداد واحد، وهو معلمة المخاطرة λ، يضبط بسلاسة مدى الحذر في هذا الاختيار — من السلوك مثل أسلوب TD3 التقليدي عندما λ تساوي صفرًا إلى أن يصبح أكثر تحفظًا كلما كبرت λ.
حلقة تدريب واحدة، طريقتان للتصرف
ميزة عملية أخرى في TDC-λ هي أنها تدعم كلًا من الطرق الحتمية والعشوائية لاختيار الإجراءات ضمن إطار موحّد واحد. أثناء التدريب، يمكن للمستخدمين الاختيار بين سياسة حتمية تقليدية أو سياسة غاوسية مقلصة بتابع tanh تقوم بعينات من الإجراءات لتعزيز الاستكشاف. بغض النظر عن هذا الاختيار، تُدرّب النقّاد التوزيعيون التوأمان بنفس الطريقة، والتقييم يستخدم دائمًا الإجراء الحتمي المتوسط. يستفيد هذا التصميم من النتائج السابقة التي أظهرت أن السلوك الحتمي أثناء الاختبار غالبًا ما يؤدي أداءً مماثلًا أو أفضل من العيّنة العشوائية، مع السماح بسياسات غنية تعزز الاستكشاف أثناء التعلم.
وضع الطريقة تحت الاختبار
قيّم المؤلفون TDC-λ على خمسة مهام معيارية شهيرة في MuJoCo حيث يجب أن تتعلم روبوتات محاكاة مثل HalfCheetah وHopper وAnt وWalker2d وHumanoid التحرك بكفاءة. عبر هذه المهام، طابقت الطريقة الجديدة أو حسّنت الأداء النهائي لأساسيات قوية بما في ذلك TD3 وDDPG وSAC، ونهج متقدم قائم على التدفق يسمى MEOW، بينما أظهرت باستمرار تقلبًا أقل عبر التجارب المتكررة. في المهام الأصعب والأعلى أبعادًا مثل Humanoid، أدت قيم λ الأعلى قليلاً — أي تقديرات هدف أكثر حذرًا — إلى أفضل العوائد على المدى البعيد وأضيق نطاقات أداء. عززت تجارب إضافية في محاكيات أخرى (PyBullet وNVIDIA Isaac) والقياسات التشخيصية التي تتعقب تباين إشارة التعلم النتيجة القائلة إن TDC-λ يجعل التعلم أكثر استقرارًا دون إبطائه.
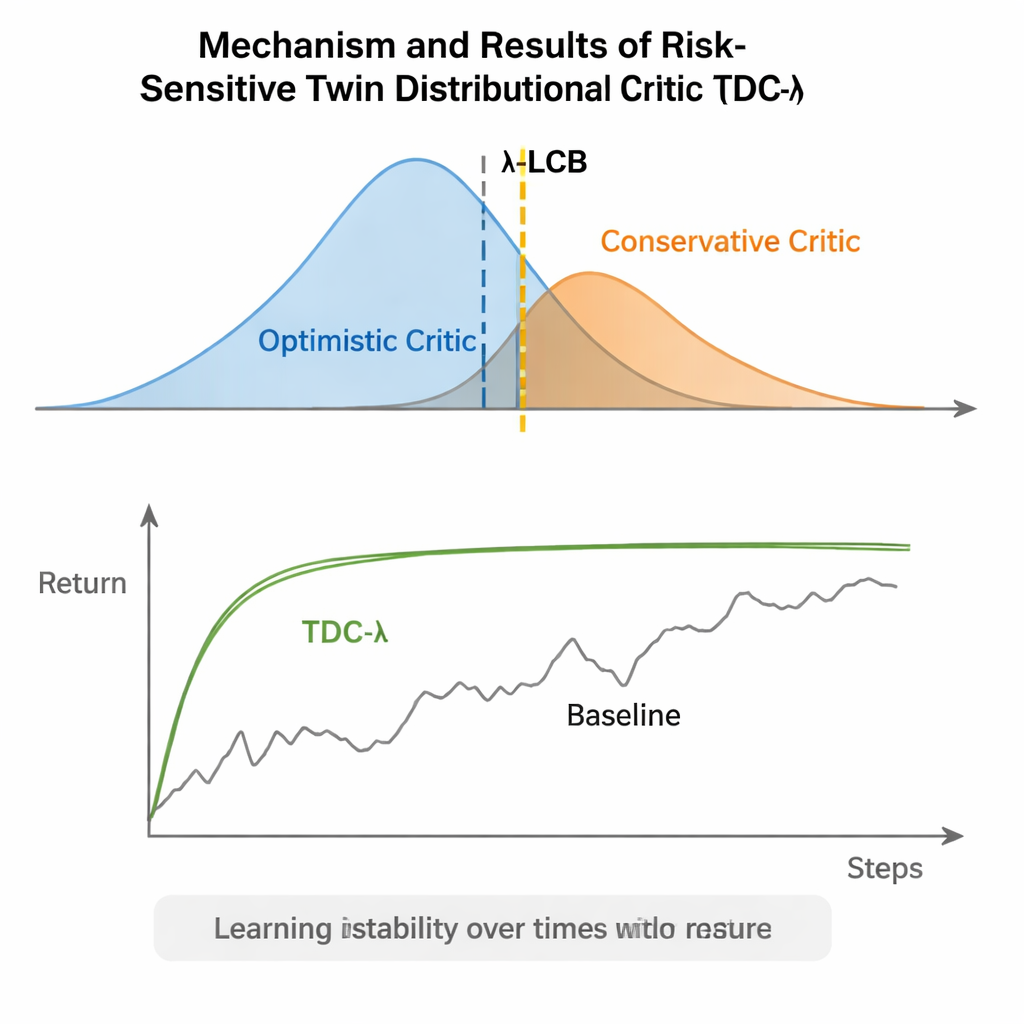
مؤشر بسيط لتعلم أكثر أمانًا
بعبارات بسيطة، تمنح TDC-λ أنظمة التعلم المعزز "هامش أمان" عند تقرير مدى الثقة بتفاؤلها الخاص. من خلال تعلم توزيعات كاملة للنتائج المحتملة ثم الميل نحو الناقد الأكثر أمانًا باستخدام مقبض λ، تقلل الخوارزمية التقلبات الحادة في التدريب مع الحفاظ على أداء نهائي مرتفع. بالنسبة للممارسين، هذا يقدم طريقة عملية لبناء متحكمات أكثر موثوقية للروبوتات وأنظمة التحكم المستمر الأخرى: ابدأ بقيمة λ محافظة إلى حد ما واضبطها بناءً على مدى تقلب عملية التعلم. الرسالة الأوسع هي أن تشكيل أهداف التدريب بعناية — ما يتعلم الوكيل منه — يمكن أن يوفر الكثير من المتانة التي تُنسب غالبًا إلى هياكل أكثر تعقيدًا، مما يجعل التعلم المعزز المتقدم أكثر ثباتًا ويسهل الوصول إليه.
الاستشهاد: Osman, O., Yalcin Kavus, B., Karaca, T.K. et al. Risk sensitive twin distributional critics with a lambda lower confidence bound for continuous control reinforcement learning. Sci Rep 16, 6699 (2026). https://doi.org/10.1038/s41598-026-37910-3
الكلمات المفتاحية: التعلم المعزز, التحكم المستمر, التعلم الحساس للمخاطر, نقاد توزيعيون, الروبوتات