Clear Sky Science · ar
تحليل مقارن لأداء نماذج اللغة الكبيرة في امتحان تخصص طب الأسنان
لماذا تعتبر الدردشات الذكية مهمة لأطباء الأسنان المستقبليين
الذكاء الاصطناعي يغير بسرعة كيفية تعلم وعمل الأطباء وأطباء الأسنان. أحد الأدوات الأكثر وضوحاً هو الروبوت الحواري المدعوم بنماذج اللغة الكبيرة — نفس تقنية المساعدة وراء العديد من المساعدين الذكيين الشائعين. طرحت هذه الدراسة سؤالاً بسيطاً لكنه مهم: إذا استخدم طلاب طب الأسنان هذه الأدوات للاستعداد لامتحان تخصصي تنافسي جداً في الأشعة الفموية والوجهية، فما مدى كفاءة هذه الآلات فعلاً؟
اختبار الذكاء الاصطناعي على امتحان حقيقي
لاكتشاف ذلك، لجأ الباحثون إلى امتحان القبول للتخصص في طب الأسنان (DUS) في تركيا، الذي يساعد على تحديد من يمكنه الالتحاق ببرامج التدريب المتقدم. من سنوات سابقة لهذا الاختبار الوطني، اختاروا 208 أسئلة متعددة الاختيارات تغطي مواضيع يجب أن يتقنها أخصائيو الأشعة، من فيزياء الإشعاع وتقنيات التصوير إلى أورام الفك وأمراض الجيوب. كانت معظم الأسئلة نصية فقط، لكن مجموعة أصغر تطلبت تفسير صور شعاعية، مما يعكس العمل التشخيصي في الحياة الواقعية.
سبعة روبوتات تجيب على نفس التحدي
ثم طرح الفريق كل سؤال باللغة التركية على سبعة روبوتات محادثة شائعة تعتمد على نماذج لغة كبيرة مختلفة: نسختان من ChatGPT، بالإضافة إلى Gemini وCopilot وDeepSeek وClaude وGrok. تم إدخال كل سؤال بعناية وبشكل منفصل لتجنب أي تأثير متبادل بين المحادثات. قارن باحث ثانٍ كل إجابة للذكاء الاصطناعي بالمفتاح الرسمي وعلمها صحيحة أو خاطئة. أخيراً، استخدم المؤلفون اختبارات إحصائية معيارية لمقارنة النماذج إجمالاً وضمن مجالات موضوعية محددة.
من حصل على أعلى الدرجات — وأين تعثّروا
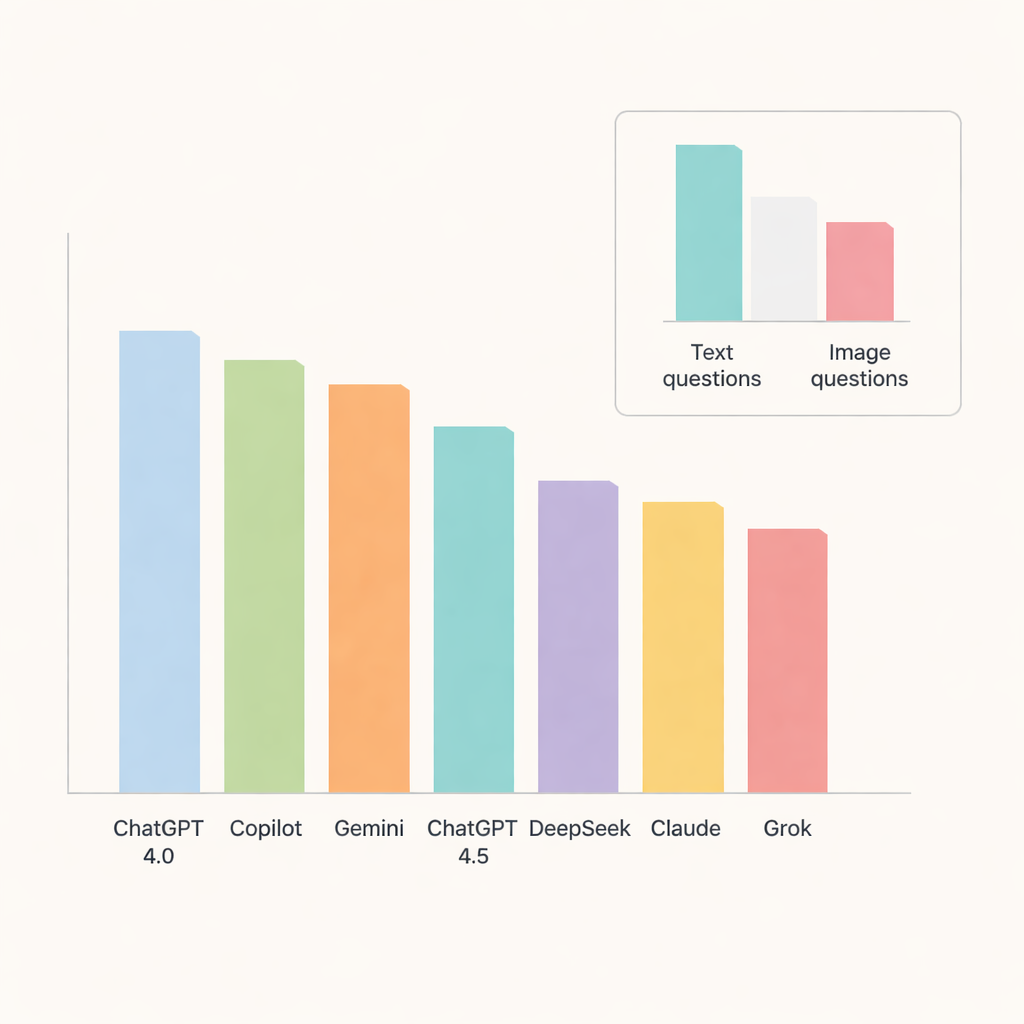
من بين جميع الروبوتات، تميز ChatGPT 4.0، حيث أجاب نحو 91 بالمئة من الأسئلة بشكل صحيح. جاء Copilot وGemini بعده بدقة تقارب منتصف إلى أواخر الثمانينات، بينما quedaron ChatGPT 4.5 وDeepSeek وClaude وGrok أدنى قليلاً. عند تفصيل النتائج بحسب الموضوعات، أدّت النماذج أداءً جيداً بشكل خاص في علم الأمراض الفموي وأمراض الغدد اللعابية، حيث اقتربت الدقة أو تجاوزت 90 بالمئة. بالمقابل، كانت تشريح الصور الشعاعية وتكلسات الأنسجة الرخوة أصعب بشكل ملحوظ، مما خفض الدرجات عبر الأنظمة وأشار إلى مجالات ما تزال فيها أنظمة الذكاء الاصطناعي تواجه صعوبة في التفاصيل الدقيقة.
الصور تبقى أصعب من النصوص
كان اختبار رئيسي هو ما إذا كان بإمكان الروبوتات التعامل مع الصور كما تفعل مع النصوص. هنا أصبحت حدودها واضحة. انخفضت الدقة بشكل حاد في الأسئلة المعتمدة على الصور، حتى بالنسبة للنماذج الأفضل أداءً. تصدرت ChatGPT 4.0 وGemini وCopilot هذه الفئة لكنها أجابت فقط نحو ثلثي الأسئلة البصرية بشكل صحيح. سجّل DeepSeek أسوأ أداء على الصور، مع ما يزيد بقليل عن ثلث الإجابات الصحيحة. بالنسبة لمعظم النماذج، كان الفرق بين الأداء على النصوص والصور كبيراً بما يكفي ليكون ذا دلالة إحصائية، ما يبرز أن تفسير الصور الطبية لا يزال مهمة صعبة للذكاء الاصطناعي العام الحالي.
ماذا يعني هذا للطلاب والمرضى
الخلاصة من الدراسة هي أن الروبوتات الحديثة يمكن أن تكون مساعدات قوية في تعليم طب الأسنان، خصوصاً لمراجعة الحقائق وممارسة أسئلة نمط الامتحانات في الأشعة. مع ذلك، حتى أقوى الأنظمة ترتكب أخطاء كافية — لا سيما في المواضيع التي تتطلب رؤية بصرية دقيقة أو معرفة متخصصة جداً — بحيث لا يمكنها استبدال الحكم الخبير بأمان. بالنسبة للطلاب والسريريين، من الأفضل رؤية هذه الأدوات كشركاء دراسيين أذكياء أو مساعدي قرار، لا كسلطات مستقلة. إذا استخدمت بحذر وإشراف مناسبين، فقد تسرّع التعلم وتوسع الوصول إلى شروحات عالية الجودة، بينما تبقى المسؤولية النهائية عن التشخيص والعلاج بيد المهنيين المدربين.
الاستشهاد: Geduk, G., Hasırcı, U.C., Kusay, D.D. et al. A comparative analysis of the performance of large Language models in the dentistry specialty examination. Sci Rep 16, 6739 (2026). https://doi.org/10.1038/s41598-026-37800-8
الكلمات المفتاحية: تعليم طب الأسنان, الذكاء الاصطناعي, نماذج اللغة الكبيرة, الأشعة الفموية والوجهية, الامتحانات الطبية